 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAxiom Learning and Belief Tracing for Transparent Decision Making in Robotics
Paper and Code
Oct 20, 2020
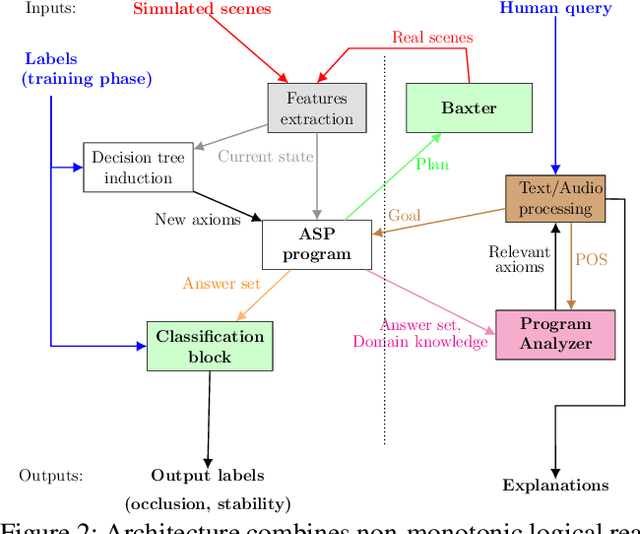
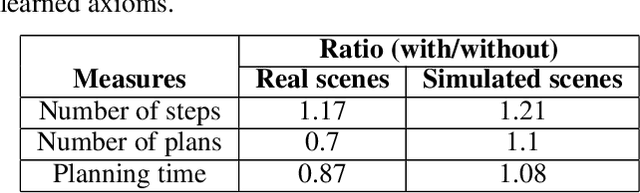
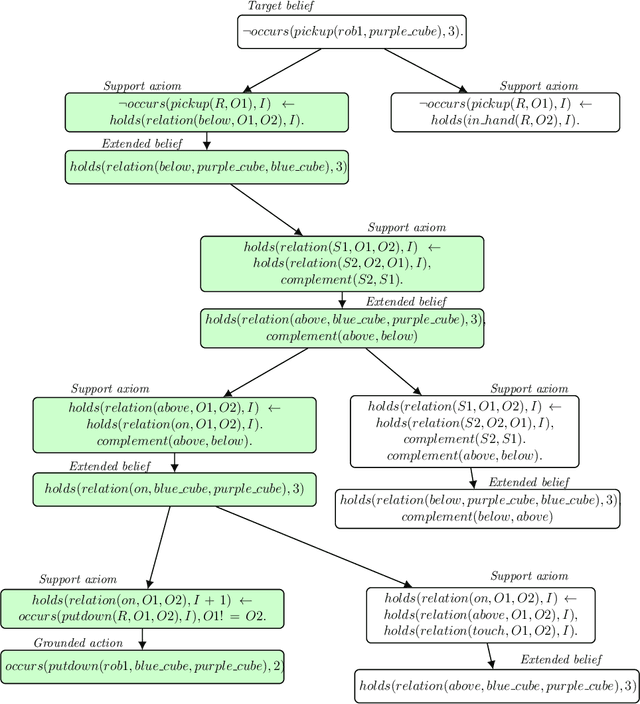
A robot's ability to provide descriptions of its decisions and beliefs promotes effective collaboration with humans. Providing such transparency is particularly challenging in integrated robot systems that include knowledge-based reasoning methods and data-driven learning algorithms. Towards addressing this challenge, our architecture couples the complementary strengths of non-monotonic logical reasoning, deep learning, and decision-tree induction. During reasoning and learning, the architecture enables a robot to provide on-demand relational descriptions of its decisions, beliefs, and the outcomes of hypothetical actions. These capabilities are grounded and evaluated in the context of scene understanding tasks and planning tasks performed using simulated images and images from a physical robot manipulating tabletop objects.