 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCost-Efficient Multi-Scale Fovea for Semantic-Based Visual Search Attention
Apr 04, 2026Semantics are one of the primary sources of top-down preattentive information. Modern deep object detectors excel at extracting such valuable semantic cues from complex visual scenes. However, the size of the visual input to be processed by these detectors can become a bottleneck, particularly in terms of time costs, affecting an artificial attention system's biological plausibility and real-time deployability. Inspired by classical exponential density roll-off topologies, we apply a new artificial foveation module to our novel attention prediction pipeline: the Semantic-based Bayesian Attention (SemBA) framework. We aim at reducing detection-related computational costs without compromising visual task accuracy, thereby making SemBA more biologically plausible. The proposed multi-scale pyramidal field-of-view retains maximum acuity at an innermost level, around a focal point, while gradually increasing distortion for outer levels to mimic peripheral uncertainty via downsampling. In this work we evaluate the performance of our novel Multi-Scale Fovea, incorporated into \textit{SemBA}, on target-present visual search. We also compare it against other artificial foveal systems, and conduct ablation studies with different deep object detection models to assess the impact of the new topology in terms of computational costs. We experimentally demonstrate that including the new Multi-Scale Fovea module effectively reduces inherent processing costs while improving SemBA's scanpath prediction accuracy. Remarkably, we show that SemBA closely approximates human consistency while retaining the actual human fovea's proportions.
Task-oriented grasping for dexterous robots using postural synergies and reinforcement learning
Feb 24, 2026In this paper, we address the problem of task-oriented grasping for humanoid robots, emphasizing the need to align with human social norms and task-specific objectives. Existing methods, employ a variety of open-loop and closed-loop approaches but lack an end-to-end solution that can grasp several objects while taking into account the downstream task's constraints. Our proposed approach employs reinforcement learning to enhance task-oriented grasping, prioritizing the post-grasp intention of the agent. We extract human grasp preferences from the ContactPose dataset, and train a hand synergy model based on the Variational Autoencoder (VAE) to imitate the participant's grasping actions. Based on this data, we train an agent able to grasp multiple objects while taking into account distinct post-grasp intentions that are task-specific. By combining data-driven insights from human grasping behavior with learning by exploration provided by reinforcement learning, we can develop humanoid robots capable of context-aware manipulation actions, facilitating collaboration in human-centered environments.
GRASPLAT: Enabling dexterous grasping through novel view synthesis
Oct 22, 2025Achieving dexterous robotic grasping with multi-fingered hands remains a significant challenge. While existing methods rely on complete 3D scans to predict grasp poses, these approaches face limitations due to the difficulty of acquiring high-quality 3D data in real-world scenarios. In this paper, we introduce GRASPLAT, a novel grasping framework that leverages consistent 3D information while being trained solely on RGB images. Our key insight is that by synthesizing physically plausible images of a hand grasping an object, we can regress the corresponding hand joints for a successful grasp. To achieve this, we utilize 3D Gaussian Splatting to generate high-fidelity novel views of real hand-object interactions, enabling end-to-end training with RGB data. Unlike prior methods, our approach incorporates a photometric loss that refines grasp predictions by minimizing discrepancies between rendered and real images. We conduct extensive experiments on both synthetic and real-world grasping datasets, demonstrating that GRASPLAT improves grasp success rates up to 36.9% over existing image-based methods. Project page: https://mbortolon97.github.io/grasplat/
Measuring Uncertainty in Shape Completion to Improve Grasp Quality
Apr 22, 2025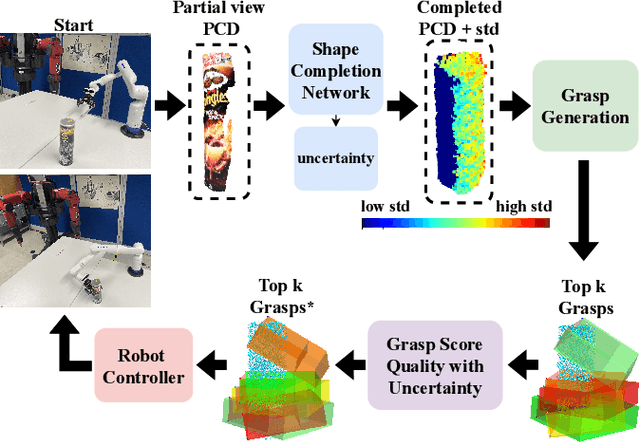
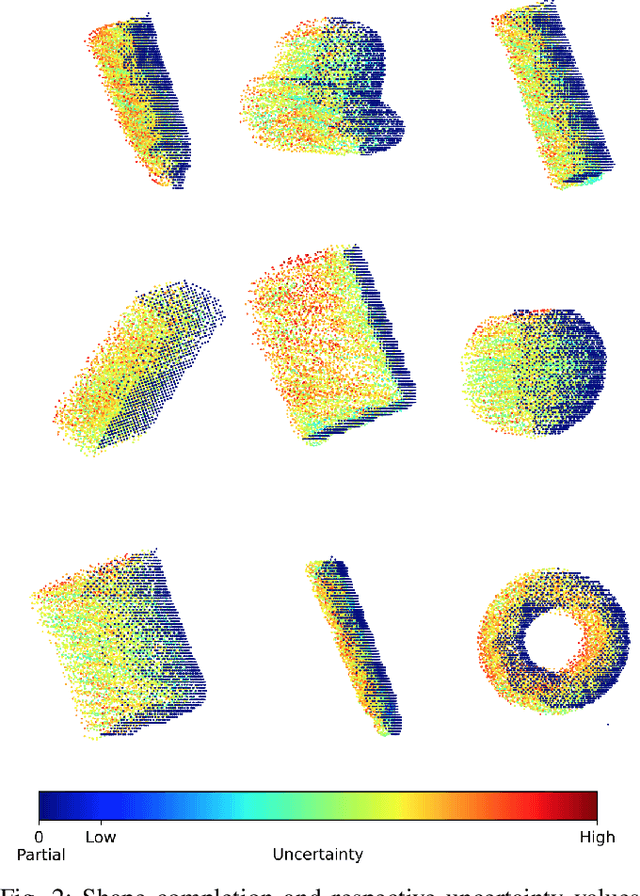

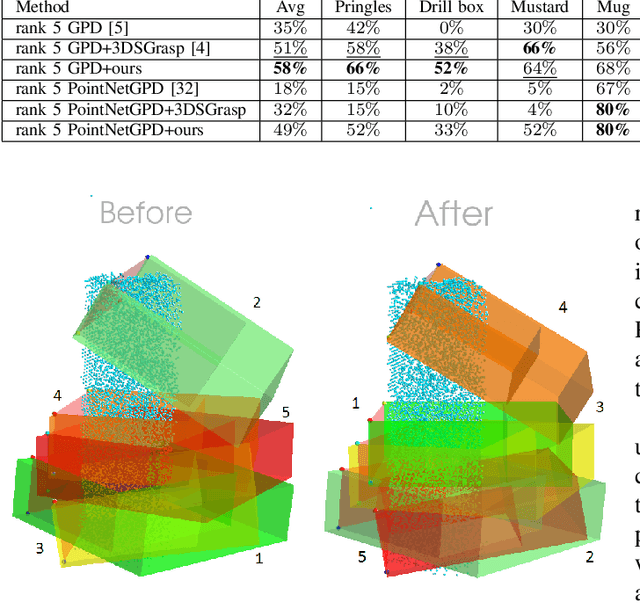
Shape completion networks have been used recently in real-world robotic experiments to complete the missing/hidden information in environments where objects are only observed in one or few instances where self-occlusions are bound to occur. Nowadays, most approaches rely on deep neural networks that handle rich 3D point cloud data that lead to more precise and realistic object geometries. However, these models still suffer from inaccuracies due to its nondeterministic/stochastic inferences which could lead to poor performance in grasping scenarios where these errors compound to unsuccessful grasps. We present an approach to calculate the uncertainty of a 3D shape completion model during inference of single view point clouds of an object on a table top. In addition, we propose an update to grasp pose algorithms quality score by introducing the uncertainty of the completed point cloud present in the grasp candidates. To test our full pipeline we perform real world grasping with a 7dof robotic arm with a 2 finger gripper on a large set of household objects and compare against previous approaches that do not measure uncertainty. Our approach ranks the grasp quality better, leading to higher grasp success rate for the rank 5 grasp candidates compared to state of the art.
Prediction of 30-day hospital readmission with clinical notes and EHR information
Mar 29, 2025



High hospital readmission rates are associated with significant costs and health risks for patients. Therefore, it is critical to develop predictive models that can support clinicians to determine whether or not a patient will return to the hospital in a relatively short period of time (e.g, 30-days). Nowadays, it is possible to collect both structured (electronic health records - EHR) and unstructured information (clinical notes) about a patient hospital event, all potentially containing relevant information for a predictive model. However, their integration is challenging. In this work we explore the combination of clinical notes and EHRs to predict 30-day hospital readmissions. We address the representation of the various types of information available in the EHR data, as well as exploring LLMs to characterize the clinical notes. We collect both information sources as the nodes of a graph neural network (GNN). Our model achieves an AUROC of 0.72 and a balanced accuracy of 66.7\%, highlighting the importance of combining the multimodal information.
Next Best View For Point-Cloud Model Acquisition: Bayesian Approximation and Uncertainty Analysis
Nov 04, 2024The Next Best View problem is a computer vision problem widely studied in robotics. To solve it, several methodologies have been proposed over the years. Some, more recently, propose the use of deep learning models. Predictions obtained with the help of deep learning models naturally have some uncertainty associated with them. Despite this, the standard models do not allow for their quantification. However, Bayesian estimation theory contributed to the demonstration that dropout layers allow to estimate prediction uncertainty in neural networks. This work adapts the point-net-based neural network for Next-Best-View (PC-NBV). It incorporates dropout layers into the model's architecture, thus allowing the computation of the uncertainty estimate associated with its predictions. The aim of the work is to improve the network's accuracy in correctly predicting the next best viewpoint, proposing a way to make the 3D reconstruction process more efficient. Two uncertainty measurements capable of reflecting the prediction's error and accuracy, respectively, were obtained. These enabled the reduction of the model's error and the increase in its accuracy from 30\% to 80\% by identifying and disregarding predictions with high values of uncertainty. Another method that directly uses these uncertainty metrics to improve the final prediction was also proposed. However, it showed very residual improvements.
Semantic-Based Active Perception for Humanoid Visual Tasks with Foveal Sensors
Apr 16, 2024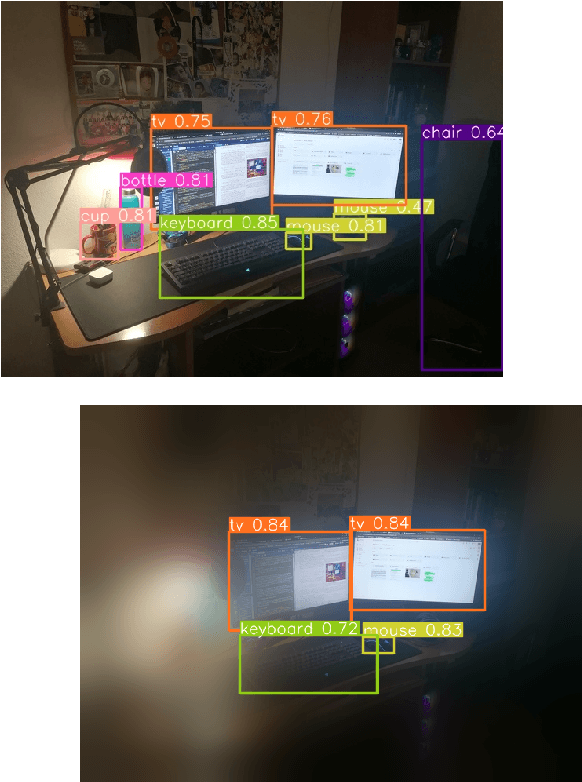
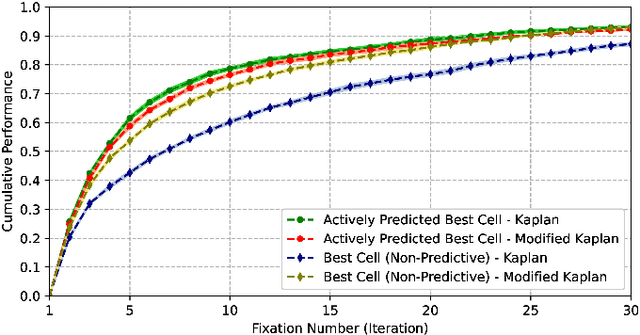
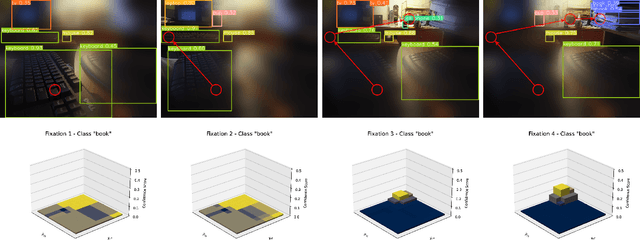
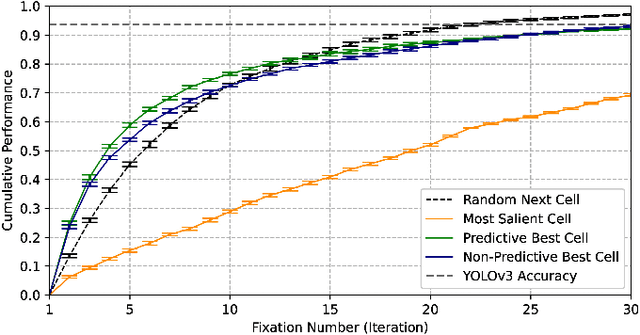
The aim of this work is to establish how accurately a recent semantic-based foveal active perception model is able to complete visual tasks that are regularly performed by humans, namely, scene exploration and visual search. This model exploits the ability of current object detectors to localize and classify a large number of object classes and to update a semantic description of a scene across multiple fixations. It has been used previously in scene exploration tasks. In this paper, we revisit the model and extend its application to visual search tasks. To illustrate the benefits of using semantic information in scene exploration and visual search tasks, we compare its performance against traditional saliency-based models. In the task of scene exploration, the semantic-based method demonstrates superior performance compared to the traditional saliency-based model in accurately representing the semantic information present in the visual scene. In visual search experiments, searching for instances of a target class in a visual field containing multiple distractors shows superior performance compared to the saliency-driven model and a random gaze selection algorithm. Our results demonstrate that semantic information, from the top-down, influences visual exploration and search tasks significantly, suggesting a potential area of research for integrating it with traditional bottom-up cues.
Pose-free object classification from surface contact features in sequences of Robotic grasps
Mar 28, 2024In this work, we propose two cost efficient methods for object identification, using a multi-fingered robotic hand equipped with proprioceptive sensing. Both methods are trained on known objects and rely on a limited set of features, obtained during a few grasps on an object. Contrary to most methods in the literature, our methods do not rely on the knowledge of the relative pose between object and hand, which greatly expands the domain of application. However, if that knowledge is available, we propose an additional active exploration step that reduces the overall number of grasps required for a good recognition of the object. One of the methods depends on the contact positions and normals and the other depends on the contact positions alone. We test the proposed methods in the GraspIt! simulator and show that haptic-based object classification is possible in pose-free conditions. We evaluate the parameters that produce the most accurate results and require the least number of grasps for classification.
Socially reactive navigation models for mobile robots in dynamic environments
Oct 15, 2023The objective of this work is to expand upon previous works, considering socially acceptable behaviours within robot navigation and interaction, and allow a robot to closely approach static and dynamic individuals or groups. The space models developed in this dissertation are adaptive, that is, capable of changing over time to accommodate the changing circumstances often existent within a social environment. The space model's parameters' adaptation occurs with the end goal of enabling a close interaction between humans and robots and is thus capable of taking into account not only the arrangement of the groups, but also the basic characteristics of the robot itself. This work also further develops a preexisting approach pose estimation algorithm in order to better guarantee the safety and comfort of the humans involved in the interaction, by taking into account basic human sensibilities. The algorithms are integrated into ROS's navigation system through the use of the $costmap2d$ and the $move\_base$ packages. The space model adaptation is tested via comparative evaluation against previous algorithms through the use of datasets. The entire navigation system is then evaluated through both simulations (static and dynamic) and real life situations (static). These experiments demonstrate that the developed space model and approach pose estimation algorithms are capable of enabling a robot to closely approach individual humans and groups, while maintaining considerations for their comfort and sensibilities.
Learning to search for and detect objects in foveal images using deep learning
Apr 12, 2023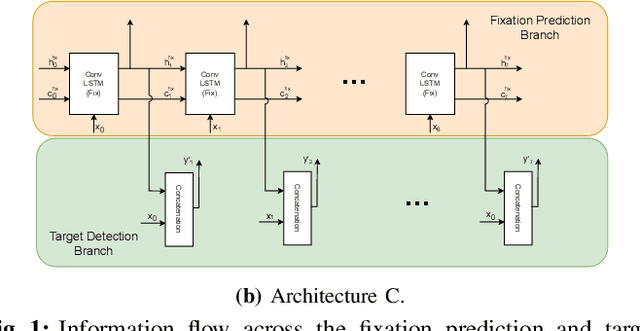
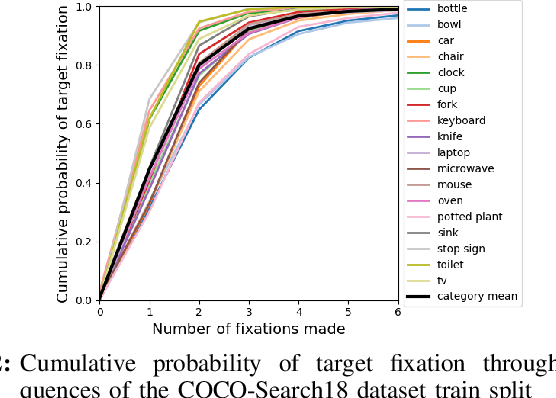
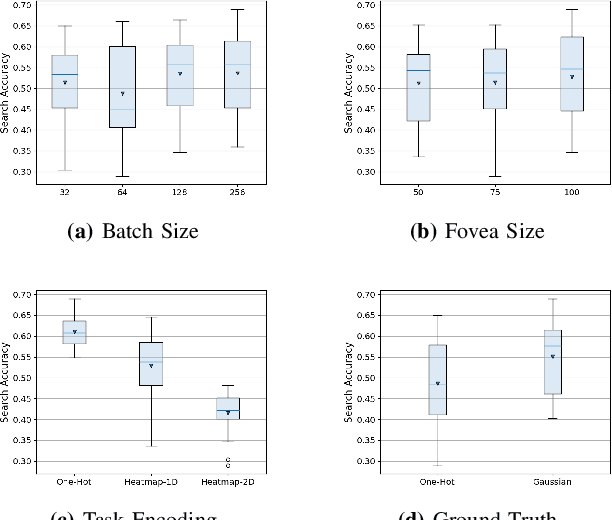
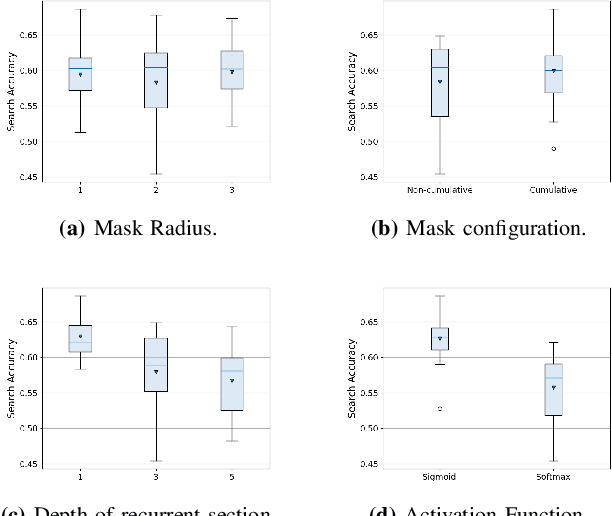
The human visual system processes images with varied degrees of resolution, with the fovea, a small portion of the retina, capturing the highest acuity region, which gradually declines toward the field of view's periphery. However, the majority of existing object localization methods rely on images acquired by image sensors with space-invariant resolution, ignoring biological attention mechanisms. As a region of interest pooling, this study employs a fixation prediction model that emulates human objective-guided attention of searching for a given class in an image. The foveated pictures at each fixation point are then classified to determine whether the target is present or absent in the scene. Throughout this two-stage pipeline method, we investigate the varying results obtained by utilizing high-level or panoptic features and provide a ground-truth label function for fixation sequences that is smoother, considering in a better way the spatial structure of the problem. Finally, we present a novel dual task model capable of performing fixation prediction and detection simultaneously, allowing knowledge transfer between the two tasks. We conclude that, due to the complementary nature of both tasks, the training process benefited from the sharing of knowledge, resulting in an improvement in performance when compared to the previous approach's baseline scores.