 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePRAGO: Differentiable Multi-View Pose Optimization From Objectness Detections
Mar 15, 2024



Robustly estimating camera poses from a set of images is a fundamental task which remains challenging for differentiable methods, especially in the case of small and sparse camera pose graphs. To overcome this challenge, we propose Pose-refined Rotation Averaging Graph Optimization (PRAGO). From a set of objectness detections on unordered images, our method reconstructs the rotational pose, and in turn, the absolute pose, in a differentiable manner benefiting from the optimization of a sequence of geometrical tasks. We show how our objectness pose-refinement module in PRAGO is able to refine the inherent ambiguities in pairwise relative pose estimation without removing edges and avoiding making early decisions on the viability of graph edges. PRAGO then refines the absolute rotations through iterative graph construction, reweighting the graph edges to compute the final rotational pose, which can be converted into absolute poses using translation averaging. We show that PRAGO is able to outperform non-differentiable solvers on small and sparse scenes extracted from 7-Scenes achieving a relative improvement of 21% for rotations while achieving similar translation estimates.
You are here! Finding position and orientation on a 2D map from a single image: The Flatlandia localization problem and dataset
Apr 17, 2023



We introduce Flatlandia, a novel problem for visual localization of an image from object detections composed of two specific tasks: i) Coarse Map Localization: localizing a single image observing a set of objects in respect to a 2D map of object landmarks; ii) Fine-grained 3DoF Localization: estimating latitude, longitude, and orientation of the image within a 2D map. Solutions for these new tasks exploit the wide availability of open urban maps annotated with GPS locations of common objects (\eg via surveying or crowd-sourced). Such maps are also more storage-friendly than standard large-scale 3D models often used in visual localization while additionally being privacy-preserving. As existing datasets are unsuited for the proposed problem, we provide the Flatlandia dataset, designed for 3DoF visual localization in multiple urban settings and based on crowd-sourced data from five European cities. We use the Flatlandia dataset to validate the complexity of the proposed tasks.
3DSGrasp: 3D Shape-Completion for Robotic Grasp
Jan 02, 2023



Real-world robotic grasping can be done robustly if a complete 3D Point Cloud Data (PCD) of an object is available. However, in practice, PCDs are often incomplete when objects are viewed from few and sparse viewpoints before the grasping action, leading to the generation of wrong or inaccurate grasp poses. We propose a novel grasping strategy, named 3DSGrasp, that predicts the missing geometry from the partial PCD to produce reliable grasp poses. Our proposed PCD completion network is a Transformer-based encoder-decoder network with an Offset-Attention layer. Our network is inherently invariant to the object pose and point's permutation, which generates PCDs that are geometrically consistent and completed properly. Experiments on a wide range of partial PCD show that 3DSGrasp outperforms the best state-of-the-art method on PCD completion tasks and largely improves the grasping success rate in real-world scenarios. The code and dataset will be made available upon acceptance.
PoserNet: Refining Relative Camera Poses Exploiting Object Detections
Jul 21, 2022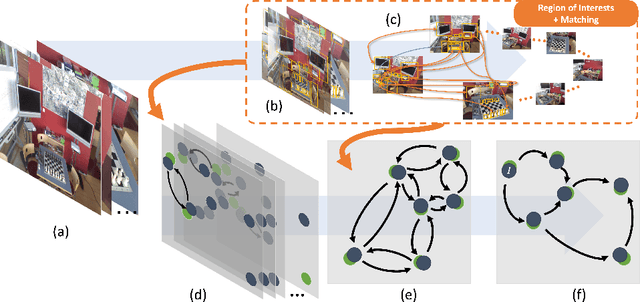

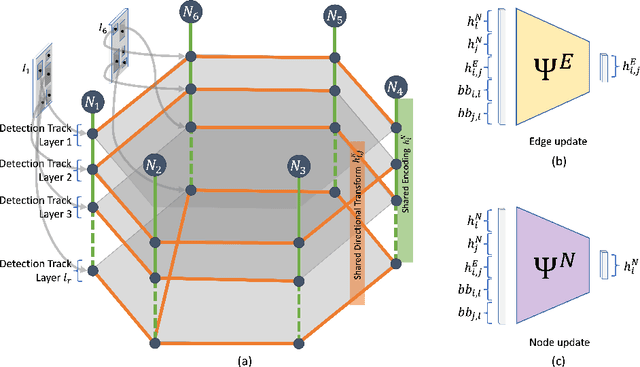

The estimation of the camera poses associated with a set of images commonly relies on feature matches between the images. In contrast, we are the first to address this challenge by using objectness regions to guide the pose estimation problem rather than explicit semantic object detections. We propose Pose Refiner Network (PoserNet) a light-weight Graph Neural Network to refine the approximate pair-wise relative camera poses. PoserNet exploits associations between the objectness regions - concisely expressed as bounding boxes - across multiple views to globally refine sparsely connected view graphs. We evaluate on the 7-Scenes dataset across varied sizes of graphs and show how this process can be beneficial to optimisation-based Motion Averaging algorithms improving the median error on the rotation by 62 degrees with respect to the initial estimates obtained based on bounding boxes. Code and data are available at https://github.com/IIT-PAVIS/PoserNet.