 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSplatFill: 3D Scene Inpainting via Depth-Guided Gaussian Splatting
Sep 09, 20253D Gaussian Splatting (3DGS) has enabled the creation of highly realistic 3D scene representations from sets of multi-view images. However, inpainting missing regions, whether due to occlusion or scene editing, remains a challenging task, often leading to blurry details, artifacts, and inconsistent geometry. In this work, we introduce SplatFill, a novel depth-guided approach for 3DGS scene inpainting that achieves state-of-the-art perceptual quality and improved efficiency. Our method combines two key ideas: (1) joint depth-based and object-based supervision to ensure inpainted Gaussians are accurately placed in 3D space and aligned with surrounding geometry, and (2) we propose a consistency-aware refinement scheme that selectively identifies and corrects inconsistent regions without disrupting the rest of the scene. Evaluations on the SPIn-NeRF dataset demonstrate that SplatFill not only surpasses existing NeRF-based and 3DGS-based inpainting methods in visual fidelity but also reduces training time by 24.5%. Qualitative results show our method delivers sharper details, fewer artifacts, and greater coherence across challenging viewpoints.
Maps from Motion (MfM): Generating 2D Semantic Maps from Sparse Multi-view Images
Nov 19, 2024

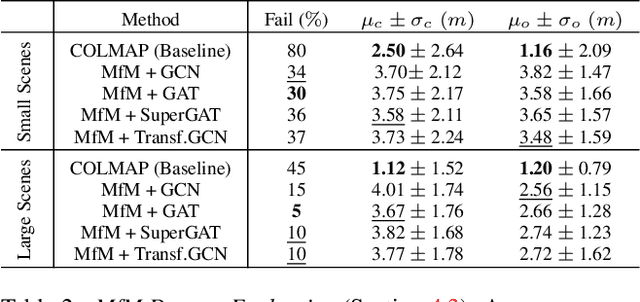

World-wide detailed 2D maps require enormous collective efforts. OpenStreetMap is the result of 11 million registered users manually annotating the GPS location of over 1.75 billion entries, including distinctive landmarks and common urban objects. At the same time, manual annotations can include errors and are slow to update, limiting the map's accuracy. Maps from Motion (MfM) is a step forward to automatize such time-consuming map making procedure by computing 2D maps of semantic objects directly from a collection of uncalibrated multi-view images. From each image, we extract a set of object detections, and estimate their spatial arrangement in a top-down local map centered in the reference frame of the camera that captured the image. Aligning these local maps is not a trivial problem, since they provide incomplete, noisy fragments of the scene, and matching detections across them is unreliable because of the presence of repeated pattern and the limited appearance variability of urban objects. We address this with a novel graph-based framework, that encodes the spatial and semantic distribution of the objects detected in each image, and learns how to combine them to predict the objects' poses in a global reference system, while taking into account all possible detection matches and preserving the topology observed in each image. Despite the complexity of the problem, our best model achieves global 2D registration with an average accuracy within 4 meters (i.e., below GPS accuracy) even on sparse sequences with strong viewpoint change, on which COLMAP has an 80% failure rate. We provide extensive evaluation on synthetic and real-world data, showing how the method obtains a solution even in scenarios where standard optimization techniques fail.
Gaussian Heritage: 3D Digitization of Cultural Heritage with Integrated Object Segmentation
Sep 27, 2024


The creation of digital replicas of physical objects has valuable applications for the preservation and dissemination of tangible cultural heritage. However, existing methods are often slow, expensive, and require expert knowledge. We propose a pipeline to generate a 3D replica of a scene using only RGB images (e.g. photos of a museum) and then extract a model for each item of interest (e.g. pieces in the exhibit). We do this by leveraging the advancements in novel view synthesis and Gaussian Splatting, modified to enable efficient 3D segmentation. This approach does not need manual annotation, and the visual inputs can be captured using a standard smartphone, making it both affordable and easy to deploy. We provide an overview of the method and baseline evaluation of the accuracy of object segmentation. The code is available at https://mahtaabdn.github.io/gaussian_heritage.github.io/.
Contrastive Gaussian Clustering: Weakly Supervised 3D Scene Segmentation
Apr 19, 2024We introduce Contrastive Gaussian Clustering, a novel approach capable of provide segmentation masks from any viewpoint and of enabling 3D segmentation of the scene. Recent works in novel-view synthesis have shown how to model the appearance of a scene via a cloud of 3D Gaussians, and how to generate accurate images from a given viewpoint by projecting on it the Gaussians before $\alpha$ blending their color. Following this example, we train a model to include also a segmentation feature vector for each Gaussian. These can then be used for 3D scene segmentation, by clustering Gaussians according to their feature vectors; and to generate 2D segmentation masks, by projecting the Gaussians on a plane and $\alpha$ blending over their segmentation features. Using a combination of contrastive learning and spatial regularization, our method can be trained on inconsistent 2D segmentation masks, and still learn to generate segmentation masks consistent across all views. Moreover, the resulting model is extremely accurate, improving the IoU accuracy of the predicted masks by $+8\%$ over the state of the art. Code and trained models will be released soon.
PRAGO: Differentiable Multi-View Pose Optimization From Objectness Detections
Mar 15, 2024



Robustly estimating camera poses from a set of images is a fundamental task which remains challenging for differentiable methods, especially in the case of small and sparse camera pose graphs. To overcome this challenge, we propose Pose-refined Rotation Averaging Graph Optimization (PRAGO). From a set of objectness detections on unordered images, our method reconstructs the rotational pose, and in turn, the absolute pose, in a differentiable manner benefiting from the optimization of a sequence of geometrical tasks. We show how our objectness pose-refinement module in PRAGO is able to refine the inherent ambiguities in pairwise relative pose estimation without removing edges and avoiding making early decisions on the viability of graph edges. PRAGO then refines the absolute rotations through iterative graph construction, reweighting the graph edges to compute the final rotational pose, which can be converted into absolute poses using translation averaging. We show that PRAGO is able to outperform non-differentiable solvers on small and sparse scenes extracted from 7-Scenes achieving a relative improvement of 21% for rotations while achieving similar translation estimates.
You are here! Finding position and orientation on a 2D map from a single image: The Flatlandia localization problem and dataset
Apr 17, 2023



We introduce Flatlandia, a novel problem for visual localization of an image from object detections composed of two specific tasks: i) Coarse Map Localization: localizing a single image observing a set of objects in respect to a 2D map of object landmarks; ii) Fine-grained 3DoF Localization: estimating latitude, longitude, and orientation of the image within a 2D map. Solutions for these new tasks exploit the wide availability of open urban maps annotated with GPS locations of common objects (\eg via surveying or crowd-sourced). Such maps are also more storage-friendly than standard large-scale 3D models often used in visual localization while additionally being privacy-preserving. As existing datasets are unsuited for the proposed problem, we provide the Flatlandia dataset, designed for 3DoF visual localization in multiple urban settings and based on crowd-sourced data from five European cities. We use the Flatlandia dataset to validate the complexity of the proposed tasks.
PoserNet: Refining Relative Camera Poses Exploiting Object Detections
Jul 21, 2022

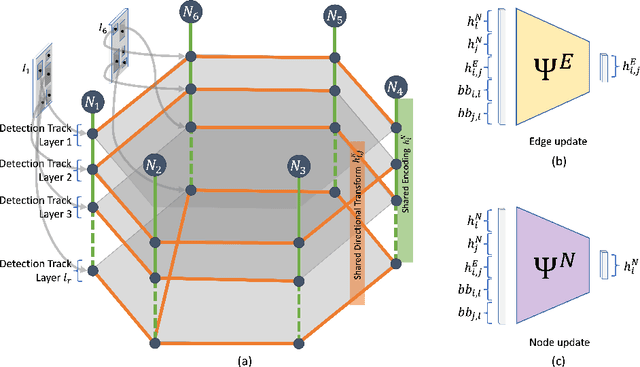

The estimation of the camera poses associated with a set of images commonly relies on feature matches between the images. In contrast, we are the first to address this challenge by using objectness regions to guide the pose estimation problem rather than explicit semantic object detections. We propose Pose Refiner Network (PoserNet) a light-weight Graph Neural Network to refine the approximate pair-wise relative camera poses. PoserNet exploits associations between the objectness regions - concisely expressed as bounding boxes - across multiple views to globally refine sparsely connected view graphs. We evaluate on the 7-Scenes dataset across varied sizes of graphs and show how this process can be beneficial to optimisation-based Motion Averaging algorithms improving the median error on the rotation by 62 degrees with respect to the initial estimates obtained based on bounding boxes. Code and data are available at https://github.com/IIT-PAVIS/PoserNet.
Rethinking Pose in 3D: Multi-stage Refinement and Recovery for Markerless Motion Capture
Aug 04, 2018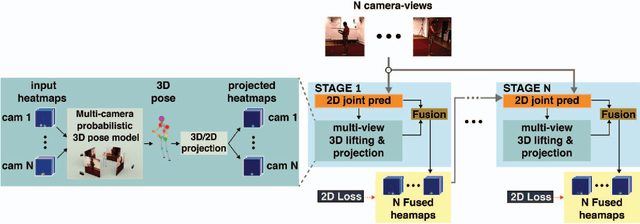
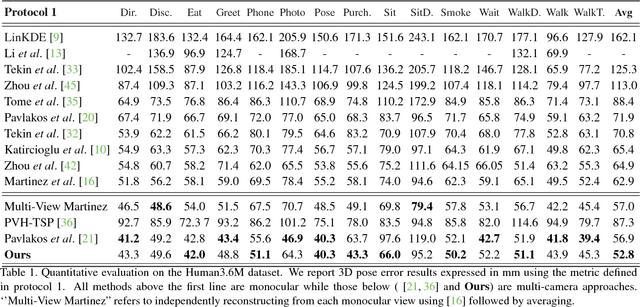
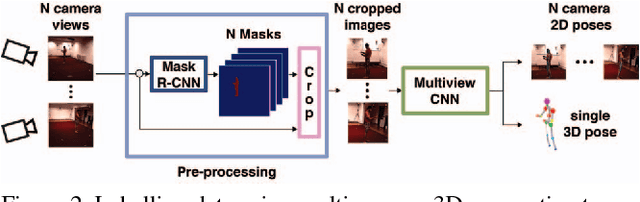

We propose a CNN-based approach for multi-camera markerless motion capture of the human body. Unlike existing methods that first perform pose estimation on individual cameras and generate 3D models as post-processing, our approach makes use of 3D reasoning throughout a multi-stage approach. This novelty allows us to use provisional 3D models of human pose to rethink where the joints should be located in the image and to recover from past mistakes. Our principled refinement of 3D human poses lets us make use of image cues, even from images where we previously misdetected joints, to refine our estimates as part of an end-to-end approach. Finally, we demonstrate how the high-quality output of our multi-camera setup can be used as an additional training source to improve the accuracy of existing single camera models.