 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeArtContext: Contextualizing Artworks with Open-Access Art History Articles and Wikidata Knowledge through a LoRA-Tuned CLIP Model
Feb 11, 2026Many Art History articles discuss artworks in general as well as specific parts of works, such as layout, iconography, or material culture. However, when viewing an artwork, it is not trivial to identify what different articles have said about the piece. Therefore, we propose ArtContext, a pipeline for taking a corpus of Open-Access Art History articles and Wikidata Knowledge and annotating Artworks with this information. We do this using a novel corpus collection pipeline, then learn a bespoke CLIP model adapted using Low-Rank Adaptation (LoRA) to make it domain-specific. We show that the new model, PaintingCLIP, which is weakly supervised by the collected corpus, outperforms CLIP and provides context for a given artwork. The proposed pipeline is generalisable and can be readily applied to numerous humanities areas.
ReassembleNet: Learnable Keypoints and Diffusion for 2D Fresco Reconstruction
May 29, 2025



The task of reassembly is a significant challenge across multiple domains, including archaeology, genomics, and molecular docking, requiring the precise placement and orientation of elements to reconstruct an original structure. In this work, we address key limitations in state-of-the-art Deep Learning methods for reassembly, namely i) scalability; ii) multimodality; and iii) real-world applicability: beyond square or simple geometric shapes, realistic and complex erosion, or other real-world problems. We propose ReassembleNet, a method that reduces complexity by representing each input piece as a set of contour keypoints and learning to select the most informative ones by Graph Neural Networks pooling inspired techniques. ReassembleNet effectively lowers computational complexity while enabling the integration of features from multiple modalities, including both geometric and texture data. Further enhanced through pretraining on a semi-synthetic dataset. We then apply diffusion-based pose estimation to recover the original structure. We improve on prior methods by 55% and 86% for RMSE Rotation and Translation, respectively.
Maps from Motion (MfM): Generating 2D Semantic Maps from Sparse Multi-view Images
Nov 19, 2024

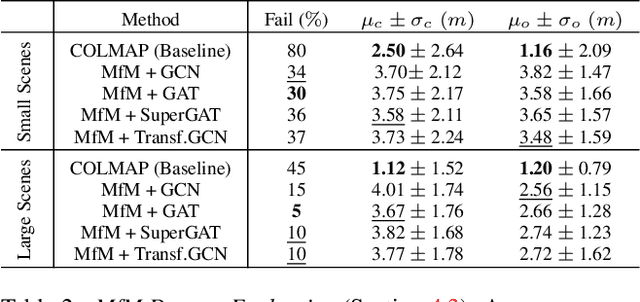

World-wide detailed 2D maps require enormous collective efforts. OpenStreetMap is the result of 11 million registered users manually annotating the GPS location of over 1.75 billion entries, including distinctive landmarks and common urban objects. At the same time, manual annotations can include errors and are slow to update, limiting the map's accuracy. Maps from Motion (MfM) is a step forward to automatize such time-consuming map making procedure by computing 2D maps of semantic objects directly from a collection of uncalibrated multi-view images. From each image, we extract a set of object detections, and estimate their spatial arrangement in a top-down local map centered in the reference frame of the camera that captured the image. Aligning these local maps is not a trivial problem, since they provide incomplete, noisy fragments of the scene, and matching detections across them is unreliable because of the presence of repeated pattern and the limited appearance variability of urban objects. We address this with a novel graph-based framework, that encodes the spatial and semantic distribution of the objects detected in each image, and learns how to combine them to predict the objects' poses in a global reference system, while taking into account all possible detection matches and preserving the topology observed in each image. Despite the complexity of the problem, our best model achieves global 2D registration with an average accuracy within 4 meters (i.e., below GPS accuracy) even on sparse sequences with strong viewpoint change, on which COLMAP has an 80% failure rate. We provide extensive evaluation on synthetic and real-world data, showing how the method obtains a solution even in scenarios where standard optimization techniques fail.
Re-assembling the past: The RePAIR dataset and benchmark for real world 2D and 3D puzzle solving
Oct 31, 2024



This paper proposes the RePAIR dataset that represents a challenging benchmark to test modern computational and data driven methods for puzzle-solving and reassembly tasks. Our dataset has unique properties that are uncommon to current benchmarks for 2D and 3D puzzle solving. The fragments and fractures are realistic, caused by a collapse of a fresco during a World War II bombing at the Pompeii archaeological park. The fragments are also eroded and have missing pieces with irregular shapes and different dimensions, challenging further the reassembly algorithms. The dataset is multi-modal providing high resolution images with characteristic pictorial elements, detailed 3D scans of the fragments and meta-data annotated by the archaeologists. Ground truth has been generated through several years of unceasing fieldwork, including the excavation and cleaning of each fragment, followed by manual puzzle solving by archaeologists of a subset of approx. 1000 pieces among the 16000 available. After digitizing all the fragments in 3D, a benchmark was prepared to challenge current reassembly and puzzle-solving methods that often solve more simplistic synthetic scenarios. The tested baselines show that there clearly exists a gap to fill in solving this computationally complex problem.
6DGS: 6D Pose Estimation from a Single Image and a 3D Gaussian Splatting Model
Jul 22, 2024



We propose 6DGS to estimate the camera pose of a target RGB image given a 3D Gaussian Splatting (3DGS) model representing the scene. 6DGS avoids the iterative process typical of analysis-by-synthesis methods (e.g. iNeRF) that also require an initialization of the camera pose in order to converge. Instead, our method estimates a 6DoF pose by inverting the 3DGS rendering process. Starting from the object surface, we define a radiant Ellicell that uniformly generates rays departing from each ellipsoid that parameterize the 3DGS model. Each Ellicell ray is associated with the rendering parameters of each ellipsoid, which in turn is used to obtain the best bindings between the target image pixels and the cast rays. These pixel-ray bindings are then ranked to select the best scoring bundle of rays, which their intersection provides the camera center and, in turn, the camera rotation. The proposed solution obviates the necessity of an "a priori" pose for initialization, and it solves 6DoF pose estimation in closed form, without the need for iterations. Moreover, compared to the existing Novel View Synthesis (NVS) baselines for pose estimation, 6DGS can improve the overall average rotational accuracy by 12% and translation accuracy by 22% on real scenes, despite not requiring any initialization pose. At the same time, our method operates near real-time, reaching 15fps on consumer hardware.
IFFNeRF: Initialisation Free and Fast 6DoF pose estimation from a single image and a NeRF model
Mar 19, 2024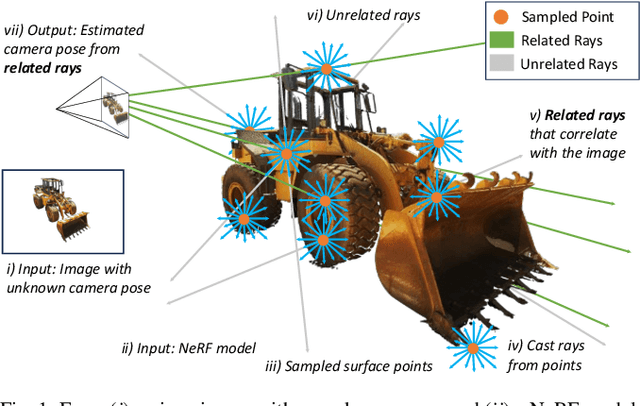
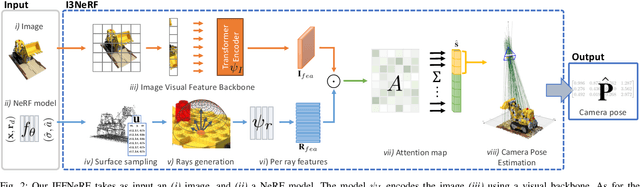
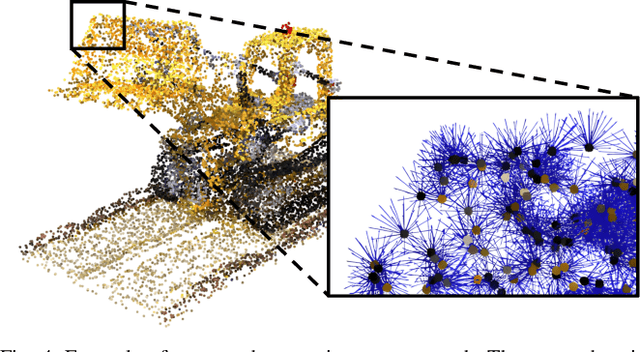
We introduce IFFNeRF to estimate the six degrees-of-freedom (6DoF) camera pose of a given image, building on the Neural Radiance Fields (NeRF) formulation. IFFNeRF is specifically designed to operate in real-time and eliminates the need for an initial pose guess that is proximate to the sought solution. IFFNeRF utilizes the Metropolis-Hasting algorithm to sample surface points from within the NeRF model. From these sampled points, we cast rays and deduce the color for each ray through pixel-level view synthesis. The camera pose can then be estimated as the solution to a Least Squares problem by selecting correspondences between the query image and the resulting bundle. We facilitate this process through a learned attention mechanism, bridging the query image embedding with the embedding of parameterized rays, thereby matching rays pertinent to the image. Through synthetic and real evaluation settings, we show that our method can improve the angular and translation error accuracy by 80.1% and 67.3%, respectively, compared to iNeRF while performing at 34fps on consumer hardware and not requiring the initial pose guess.
PRAGO: Differentiable Multi-View Pose Optimization From Objectness Detections
Mar 15, 2024



Robustly estimating camera poses from a set of images is a fundamental task which remains challenging for differentiable methods, especially in the case of small and sparse camera pose graphs. To overcome this challenge, we propose Pose-refined Rotation Averaging Graph Optimization (PRAGO). From a set of objectness detections on unordered images, our method reconstructs the rotational pose, and in turn, the absolute pose, in a differentiable manner benefiting from the optimization of a sequence of geometrical tasks. We show how our objectness pose-refinement module in PRAGO is able to refine the inherent ambiguities in pairwise relative pose estimation without removing edges and avoiding making early decisions on the viability of graph edges. PRAGO then refines the absolute rotations through iterative graph construction, reweighting the graph edges to compute the final rotational pose, which can be converted into absolute poses using translation averaging. We show that PRAGO is able to outperform non-differentiable solvers on small and sparse scenes extracted from 7-Scenes achieving a relative improvement of 21% for rotations while achieving similar translation estimates.
Towards the Reusability and Compositionality of Causal Representations
Mar 14, 2024



Causal Representation Learning (CRL) aims at identifying high-level causal factors and their relationships from high-dimensional observations, e.g., images. While most CRL works focus on learning causal representations in a single environment, in this work we instead propose a first step towards learning causal representations from temporal sequences of images that can be adapted in a new environment, or composed across multiple related environments. In particular, we introduce DECAF, a framework that detects which causal factors can be reused and which need to be adapted from previously learned causal representations. Our approach is based on the availability of intervention targets, that indicate which variables are perturbed at each time step. Experiments on three benchmark datasets show that integrating our framework with four state-of-the-art CRL approaches leads to accurate representations in a new environment with only a few samples.
You are here! Finding position and orientation on a 2D map from a single image: The Flatlandia localization problem and dataset
Apr 17, 2023



We introduce Flatlandia, a novel problem for visual localization of an image from object detections composed of two specific tasks: i) Coarse Map Localization: localizing a single image observing a set of objects in respect to a 2D map of object landmarks; ii) Fine-grained 3DoF Localization: estimating latitude, longitude, and orientation of the image within a 2D map. Solutions for these new tasks exploit the wide availability of open urban maps annotated with GPS locations of common objects (\eg via surveying or crowd-sourced). Such maps are also more storage-friendly than standard large-scale 3D models often used in visual localization while additionally being privacy-preserving. As existing datasets are unsuited for the proposed problem, we provide the Flatlandia dataset, designed for 3DoF visual localization in multiple urban settings and based on crowd-sourced data from five European cities. We use the Flatlandia dataset to validate the complexity of the proposed tasks.
Positional Diffusion: Ordering Unordered Sets with Diffusion Probabilistic Models
Mar 20, 2023



Positional reasoning is the process of ordering unsorted parts contained in a set into a consistent structure. We present Positional Diffusion, a plug-and-play graph formulation with Diffusion Probabilistic Models to address positional reasoning. We use the forward process to map elements' positions in a set to random positions in a continuous space. Positional Diffusion learns to reverse the noising process and recover the original positions through an Attention-based Graph Neural Network. We conduct extensive experiments with benchmark datasets including two puzzle datasets, three sentence ordering datasets, and one visual storytelling dataset, demonstrating that our method outperforms long-lasting research on puzzle solving with up to +18% compared to the second-best deep learning method, and performs on par against the state-of-the-art methods on sentence ordering and visual storytelling. Our work highlights the suitability of diffusion models for ordering problems and proposes a novel formulation and method for solving various ordering tasks. Project website at https://iit-pavis.github.io/Positional_Diffusion/