 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFew-step Cofolding with All-Atom Flow Maps
Jun 07, 2026All-atom generative modeling of 3D biomolecular complexes has emerged as the dominant paradigm for predicting the structure of proteins and protein-ligand systems. Generating structures at the atomic level of fidelity, however, typically requires expensive iterative diffusion rollouts, making both conventional deployment and inference-time search techniques computationally costly. In this paper, we introduce the Denoiser Cofolding All-Atom Flowmap (DeCAF) framework for distilling state-of-the-art all-atom cofolding models into all-atom flow maps that produce high-quality samples in only a few inference steps. We build DeCAF on a denoiser-based formulation of flow maps with endpoint losses that naturally support SE(3) rigid alignment, which we show is critical for training accurate models. We further derive a simple change of variables that lets DeCAF operate in the σ-space noise schedule of EDM-style architectures, enabling direct distillation from pretrained cofolding diffusion models. Equipped with DeCAF's flowmap lookahead, we introduce a purpose-built inference-time framework that improves sampling through reward-guided search. Empirically, DeCAF-Boltz statistically improves over Boltz-1x in both accuracy (RMSD) and physical validity scores of protein-ligand poses at strict NFE budgets on the challenging Runs N' Poses, while also showing a more optimal Pareto frontier across all inference compute budgets on PoseBusters. Distilling the state-of-the-art Pearl cofolding model, DeCAF-Pearl outperforms diffusion-based cofolding models and matches its teacher on success rate while using 5x fewer NFEs. We release our code at https://github.com/genesistherapeutics/decaf.
Re-assembling the past: The RePAIR dataset and benchmark for real world 2D and 3D puzzle solving
Oct 31, 2024



This paper proposes the RePAIR dataset that represents a challenging benchmark to test modern computational and data driven methods for puzzle-solving and reassembly tasks. Our dataset has unique properties that are uncommon to current benchmarks for 2D and 3D puzzle solving. The fragments and fractures are realistic, caused by a collapse of a fresco during a World War II bombing at the Pompeii archaeological park. The fragments are also eroded and have missing pieces with irregular shapes and different dimensions, challenging further the reassembly algorithms. The dataset is multi-modal providing high resolution images with characteristic pictorial elements, detailed 3D scans of the fragments and meta-data annotated by the archaeologists. Ground truth has been generated through several years of unceasing fieldwork, including the excavation and cleaning of each fragment, followed by manual puzzle solving by archaeologists of a subset of approx. 1000 pieces among the 16000 available. After digitizing all the fragments in 3D, a benchmark was prepared to challenge current reassembly and puzzle-solving methods that often solve more simplistic synthetic scenarios. The tested baselines show that there clearly exists a gap to fill in solving this computationally complex problem.
DiffAssemble: A Unified Graph-Diffusion Model for 2D and 3D Reassembly
Feb 29, 2024



Reassembly tasks play a fundamental role in many fields and multiple approaches exist to solve specific reassembly problems. In this context, we posit that a general unified model can effectively address them all, irrespective of the input data type (images, 3D, etc.). We introduce DiffAssemble, a Graph Neural Network (GNN)-based architecture that learns to solve reassembly tasks using a diffusion model formulation. Our method treats the elements of a set, whether pieces of 2D patch or 3D object fragments, as nodes of a spatial graph. Training is performed by introducing noise into the position and rotation of the elements and iteratively denoising them to reconstruct the coherent initial pose. DiffAssemble achieves state-of-the-art (SOTA) results in most 2D and 3D reassembly tasks and is the first learning-based approach that solves 2D puzzles for both rotation and translation. Furthermore, we highlight its remarkable reduction in run-time, performing 11 times faster than the quickest optimization-based method for puzzle solving. Code available at https://github.com/IIT-PAVIS/DiffAssemble
$\pi2\text{vec}$: Policy Representations with Successor Features
Jun 16, 2023



This paper describes $\pi2\text{vec}$, a method for representing behaviors of black box policies as feature vectors. The policy representations capture how the statistics of foundation model features change in response to the policy behavior in a task agnostic way, and can be trained from offline data, allowing them to be used in offline policy selection. This work provides a key piece of a recipe for fusing together three modern lines of research: Offline policy evaluation as a counterpart to offline RL, foundation models as generic and powerful state representations, and efficient policy selection in resource constrained environments.
Positional Diffusion: Ordering Unordered Sets with Diffusion Probabilistic Models
Mar 20, 2023



Positional reasoning is the process of ordering unsorted parts contained in a set into a consistent structure. We present Positional Diffusion, a plug-and-play graph formulation with Diffusion Probabilistic Models to address positional reasoning. We use the forward process to map elements' positions in a set to random positions in a continuous space. Positional Diffusion learns to reverse the noising process and recover the original positions through an Attention-based Graph Neural Network. We conduct extensive experiments with benchmark datasets including two puzzle datasets, three sentence ordering datasets, and one visual storytelling dataset, demonstrating that our method outperforms long-lasting research on puzzle solving with up to +18% compared to the second-best deep learning method, and performs on par against the state-of-the-art methods on sentence ordering and visual storytelling. Our work highlights the suitability of diffusion models for ordering problems and proposes a novel formulation and method for solving various ordering tasks. Project website at https://iit-pavis.github.io/Positional_Diffusion/
Self-improving object detection via disagreement reconciliation
Feb 21, 2023



Object detectors often experience a drop in performance when new environmental conditions are insufficiently represented in the training data. This paper studies how to automatically fine-tune a pre-existing object detector while exploring and acquiring images in a new environment without relying on human intervention, i.e., in a self-supervised fashion. In our setting, an agent initially explores the environment using a pre-trained off-the-shelf detector to locate objects and associate pseudo-labels. By assuming that pseudo-labels for the same object must be consistent across different views, we devise a novel mechanism for producing refined predictions from the consensus among observations. Our approach improves the off-the-shelf object detector by 2.66% in terms of mAP and outperforms the current state of the art without relying on ground-truth annotations.
Look around and learn: self-improving object detection by exploration
Feb 10, 2023Object detectors often experience a drop in performance when new environmental conditions are insufficiently represented in the training data. This paper studies how to automatically fine-tune a pre-existing object detector while exploring and acquiring images in a new environment without relying on human intervention, i.e., in an utterly self-supervised fashion. In our setting, an agent initially learns to explore the environment using a pre-trained off-the-shelf detector to locate objects and associate pseudo-labels. By assuming that pseudo-labels for the same object must be consistent across different views, we learn an exploration policy mining hard samples and we devise a novel mechanism for producing refined predictions from the consensus among observations. Our approach outperforms the current state-of-the-art, and it closes the performance gap against a fully supervised setting without relying on ground-truth annotations. We also compare various exploration policies for the agent to gather more informative observations. Code and dataset will be made available upon paper acceptance
Lifting Monocular Events to 3D Human Poses
Apr 21, 2021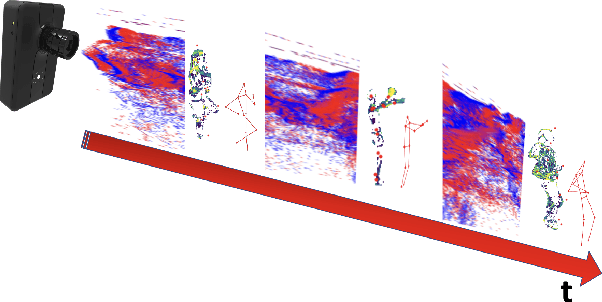
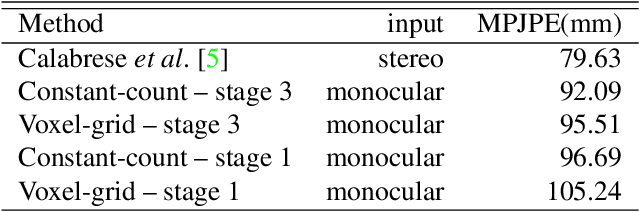
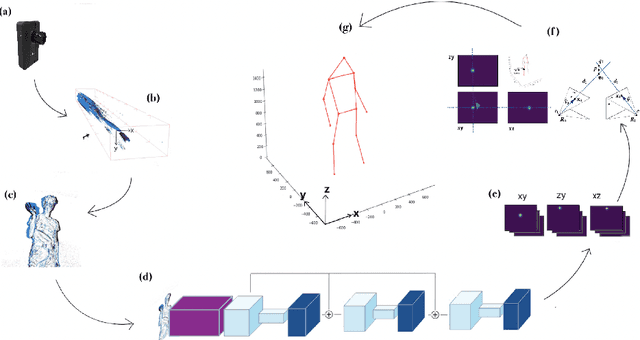

This paper presents a novel 3D human pose estimation approach using a single stream of asynchronous events as input. Most of the state-of-the-art approaches solve this task with RGB cameras, however struggling when subjects are moving fast. On the other hand, event-based 3D pose estimation benefits from the advantages of event-cameras, especially their efficiency and robustness to appearance changes. Yet, finding human poses in asynchronous events is in general more challenging than standard RGB pose estimation, since little or no events are triggered in static scenes. Here we propose the first learning-based method for 3D human pose from a single stream of events. Our method consists of two steps. First, we process the event-camera stream to predict three orthogonal heatmaps per joint; each heatmap is the projection of of the joint onto one orthogonal plane. Next, we fuse the sets of heatmaps to estimate 3D localisation of the body joints. As a further contribution, we make available a new, challenging dataset for event-based human pose estimation by simulating events from the RGB Human3.6m dataset. Experiments demonstrate that our method achieves solid accuracy, narrowing the performance gap between standard RGB and event-based vision. The code is freely available at https://iit-pavis.github.io/lifting_events_to_3d_hpe.