 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVision-Language Model Dialog Games for Self-Improvement
Feb 04, 2025



The increasing demand for high-quality, diverse training data poses a significant bottleneck in advancing vision-language models (VLMs). This paper presents VLM Dialog Games, a novel and scalable self-improvement framework for VLMs. Our approach leverages self-play between two agents engaged in a goal-oriented play centered around image identification. By filtering for successful game interactions, we automatically curate a high-quality dataset of interleaved images and text. We demonstrate that fine-tuning on this synthetic data leads to performance gains on downstream tasks and generalises across datasets. Moreover, as the improvements in the model lead to better game play, this procedure can be applied iteratively. This work paves the way for self-improving VLMs, with potential applications in various real-world scenarios especially when the high-quality multimodal data is scarce.
Imagen 3
Aug 13, 2024We introduce Imagen 3, a latent diffusion model that generates high quality images from text prompts. We describe our quality and responsibility evaluations. Imagen 3 is preferred over other state-of-the-art (SOTA) models at the time of evaluation. In addition, we discuss issues around safety and representation, as well as methods we used to minimize the potential harm of our models.
Reinforced Self-Training (ReST) for Language Modeling
Aug 21, 2023Reinforcement learning from human feedback (RLHF) can improve the quality of large language model's (LLM) outputs by aligning them with human preferences. We propose a simple algorithm for aligning LLMs with human preferences inspired by growing batch reinforcement learning (RL), which we call Reinforced Self-Training (ReST). Given an initial LLM policy, ReST produces a dataset by generating samples from the policy, which are then used to improve the LLM policy using offline RL algorithms. ReST is more efficient than typical online RLHF methods because the training dataset is produced offline, which allows data reuse. While ReST is a general approach applicable to all generative learning settings, we focus on its application to machine translation. Our results show that ReST can substantially improve translation quality, as measured by automated metrics and human evaluation on machine translation benchmarks in a compute and sample-efficient manner.
$\pi2\text{vec}$: Policy Representations with Successor Features
Jun 16, 2023



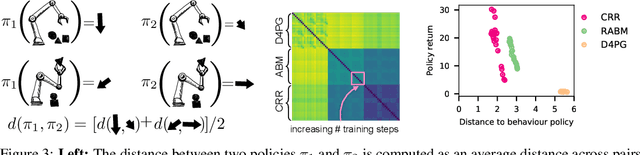
This paper describes $\pi2\text{vec}$, a method for representing behaviors of black box policies as feature vectors. The policy representations capture how the statistics of foundation model features change in response to the policy behavior in a task agnostic way, and can be trained from offline data, allowing them to be used in offline policy selection. This work provides a key piece of a recipe for fusing together three modern lines of research: Offline policy evaluation as a counterpart to offline RL, foundation models as generic and powerful state representations, and efficient policy selection in resource constrained environments.
Vision-Language Models as Success Detectors
Mar 13, 2023Detecting successful behaviour is crucial for training intelligent agents. As such, generalisable reward models are a prerequisite for agents that can learn to generalise their behaviour. In this work we focus on developing robust success detectors that leverage large, pretrained vision-language models (Flamingo, Alayrac et al. (2022)) and human reward annotations. Concretely, we treat success detection as a visual question answering (VQA) problem, denoted SuccessVQA. We study success detection across three vastly different domains: (i) interactive language-conditioned agents in a simulated household, (ii) real world robotic manipulation, and (iii) "in-the-wild" human egocentric videos. We investigate the generalisation properties of a Flamingo-based success detection model across unseen language and visual changes in the first two domains, and find that the proposed method is able to outperform bespoke reward models in out-of-distribution test scenarios with either variation. In the last domain of "in-the-wild" human videos, we show that success detection on unseen real videos presents an even more challenging generalisation task warranting future work. We hope our initial results encourage further work in real world success detection and reward modelling.
Retrieval-Augmented Reinforcement Learning
Mar 09, 2022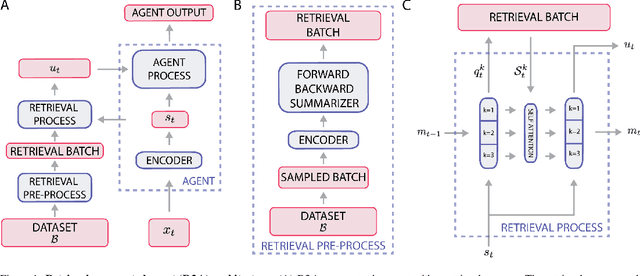

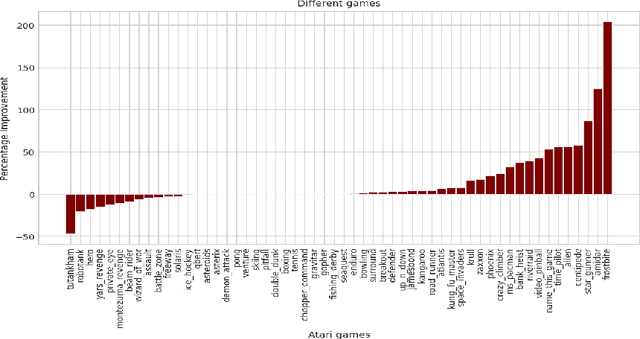
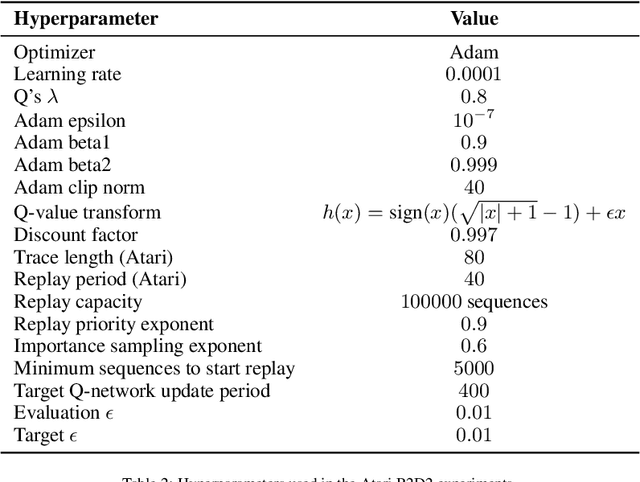
Most deep reinforcement learning (RL) algorithms distill experience into parametric behavior policies or value functions via gradient updates. While effective, this approach has several disadvantages: (1) it is computationally expensive, (2) it can take many updates to integrate experiences into the parametric model, (3) experiences that are not fully integrated do not appropriately influence the agent's behavior, and (4) behavior is limited by the capacity of the model. In this paper we explore an alternative paradigm in which we train a network to map a dataset of past experiences to optimal behavior. Specifically, we augment an RL agent with a retrieval process (parameterized as a neural network) that has direct access to a dataset of experiences. This dataset can come from the agent's past experiences, expert demonstrations, or any other relevant source. The retrieval process is trained to retrieve information from the dataset that may be useful in the current context, to help the agent achieve its goal faster and more efficiently. We integrate our method into two different RL agents: an offline DQN agent and an online R2D2 agent. In offline multi-task problems, we show that the retrieval-augmented DQN agent avoids task interference and learns faster than the baseline DQN agent. On Atari, we show that retrieval-augmented R2D2 learns significantly faster than the baseline R2D2 agent and achieves higher scores. We run extensive ablations to measure the contributions of the components of our proposed method.
Active Offline Policy Selection
Jun 18, 2021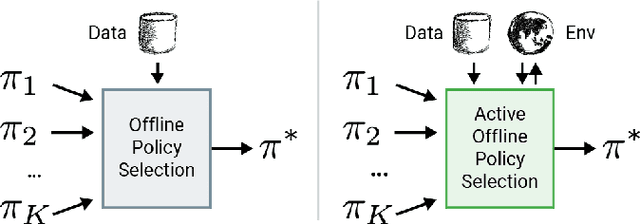
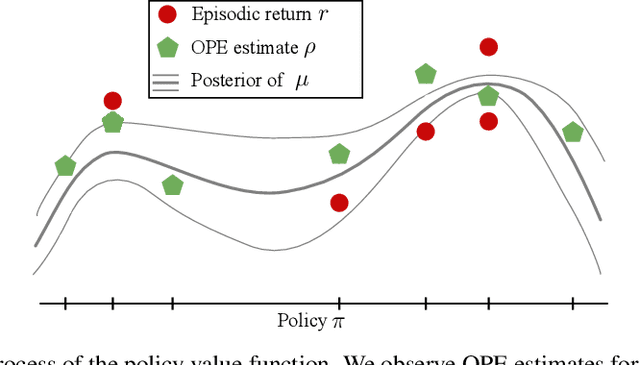

This paper addresses the problem of policy selection in domains with abundant logged data, but with a very restricted interaction budget. Solving this problem would enable safe evaluation and deployment of offline reinforcement learning policies in industry, robotics, and healthcare domain among others. Several off-policy evaluation (OPE) techniques have been proposed to assess the value of policies using only logged data. However, there is still a big gap between the evaluation by OPE and the full online evaluation in the real environment. To reduce this gap, we introduce a novel \emph{active offline policy selection} problem formulation, which combined logged data and limited online interactions to identify the best policy. We rely on the advances in OPE to warm start the evaluation. We build upon Bayesian optimization to iteratively decide which policies to evaluate in order to utilize the limited environment interactions wisely. Many candidate policies could be proposed, thus, we focus on making our approach scalable and introduce a kernel function to model similarity between policies. We use several benchmark environments to show that the proposed approach improves upon state-of-the-art OPE estimates and fully online policy evaluation with limited budget. Additionally, we show that each component of the proposed method is important, it works well with various number and quality of OPE estimates and even with a large number of candidate policies.
Semi-supervised reward learning for offline reinforcement learning
Dec 12, 2020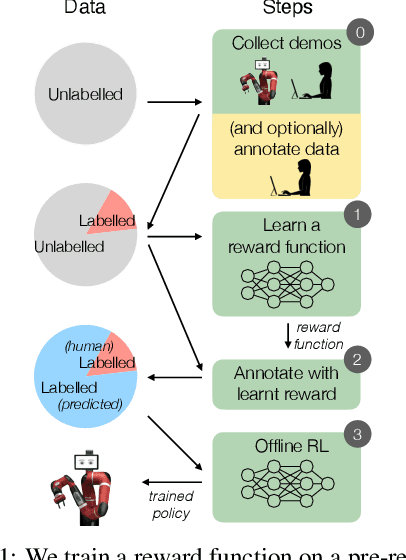
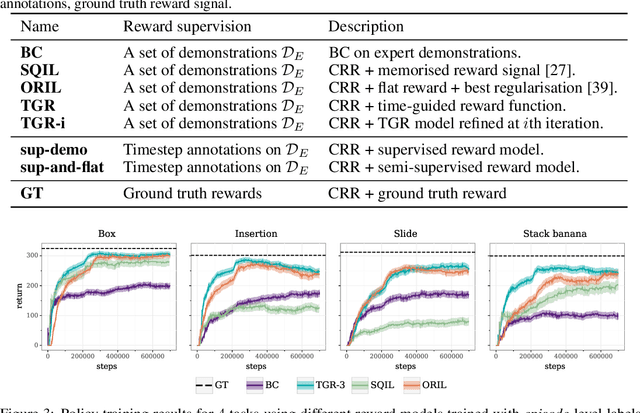

In offline reinforcement learning (RL) agents are trained using a logged dataset. It appears to be the most natural route to attack real-life applications because in domains such as healthcare and robotics interactions with the environment are either expensive or unethical. Training agents usually requires reward functions, but unfortunately, rewards are seldom available in practice and their engineering is challenging and laborious. To overcome this, we investigate reward learning under the constraint of minimizing human reward annotations. We consider two types of supervision: timestep annotations and demonstrations. We propose semi-supervised learning algorithms that learn from limited annotations and incorporate unlabelled data. In our experiments with a simulated robotic arm, we greatly improve upon behavioural cloning and closely approach the performance achieved with ground truth rewards. We further investigate the relationship between the quality of the reward model and the final policies. We notice, for example, that the reward models do not need to be perfect to result in useful policies.
Offline Learning from Demonstrations and Unlabeled Experience
Nov 27, 2020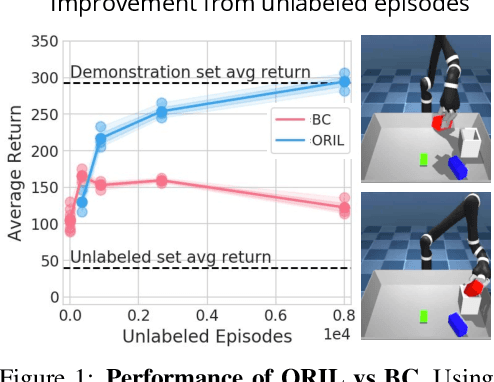
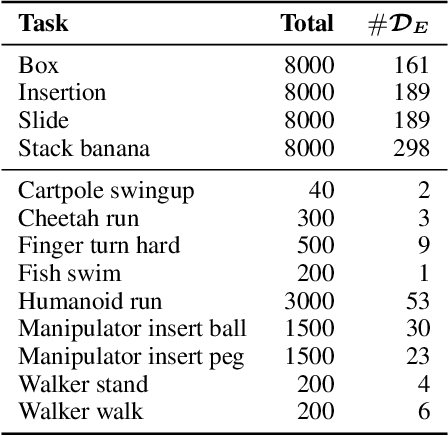
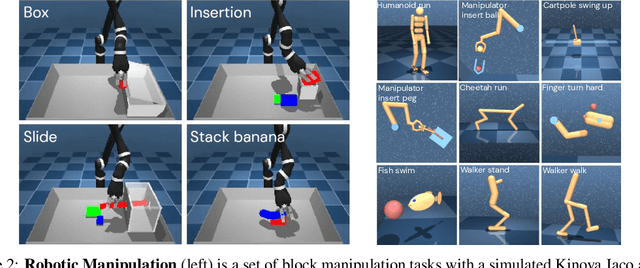

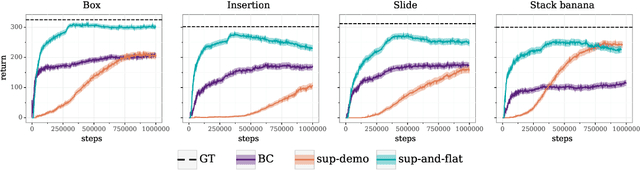
Behavior cloning (BC) is often practical for robot learning because it allows a policy to be trained offline without rewards, by supervised learning on expert demonstrations. However, BC does not effectively leverage what we will refer to as unlabeled experience: data of mixed and unknown quality without reward annotations. This unlabeled data can be generated by a variety of sources such as human teleoperation, scripted policies and other agents on the same robot. Towards data-driven offline robot learning that can use this unlabeled experience, we introduce Offline Reinforced Imitation Learning (ORIL). ORIL first learns a reward function by contrasting observations from demonstrator and unlabeled trajectories, then annotates all data with the learned reward, and finally trains an agent via offline reinforcement learning. Across a diverse set of continuous control and simulated robotic manipulation tasks, we show that ORIL consistently outperforms comparable BC agents by effectively leveraging unlabeled experience.
A Framework for Data-Driven Robotics
Sep 26, 2019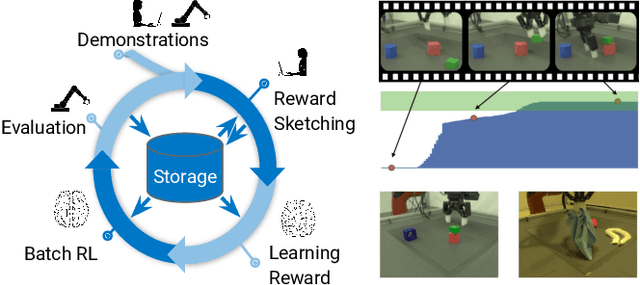
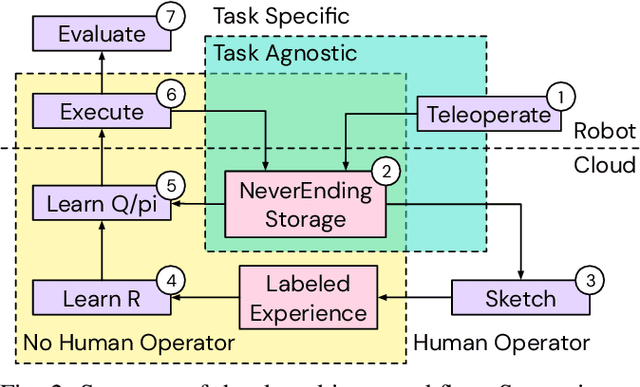
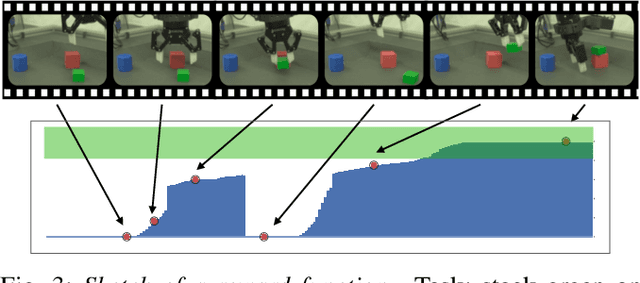
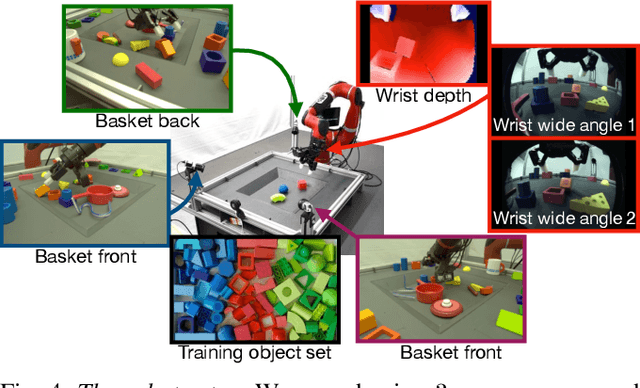
We present a framework for data-driven robotics that makes use of a large dataset of recorded robot experience and scales to several tasks using learned reward functions. We show how to apply this framework to accomplish three different object manipulation tasks on a real robot platform. Given demonstrations of a task together with task-agnostic recorded experience, we use a special form of human annotation as supervision to learn a reward function, which enables us to deal with real-world tasks where the reward signal cannot be acquired directly. Learned rewards are used in combination with a large dataset of experience from different tasks to learn a robot policy offline using batch RL. We show that using our approach it is possible to train agents to perform a variety of challenging manipulation tasks including stacking rigid objects and handling cloth.