 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the Difficulty of Constructing a Robust and Publicly-Detectable Watermark
Feb 07, 2025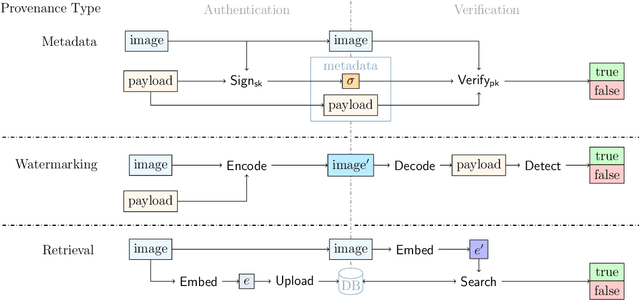
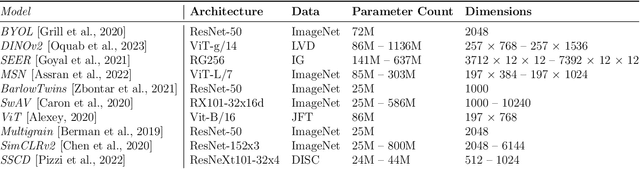
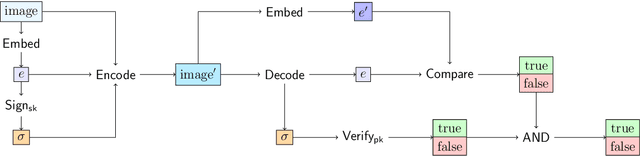
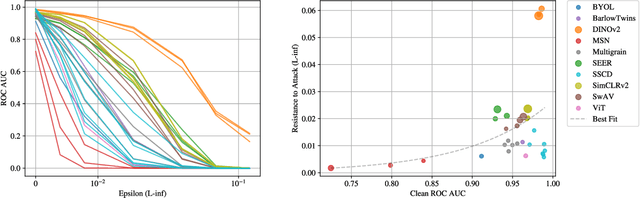
This work investigates the theoretical boundaries of creating publicly-detectable schemes to enable the provenance of watermarked imagery. Metadata-based approaches like C2PA provide unforgeability and public-detectability. ML techniques offer robust retrieval and watermarking. However, no existing scheme combines robustness, unforgeability, and public-detectability. In this work, we formally define such a scheme and establish its existence. Although theoretically possible, we find that at present, it is intractable to build certain components of our scheme without a leap in deep learning capabilities. We analyze these limitations and propose research directions that need to be addressed before we can practically realize robust and publicly-verifiable provenance.
Deep SE(3)-Equivariant Geometric Reasoning for Precise Placement Tasks
Apr 20, 2024



Many robot manipulation tasks can be framed as geometric reasoning tasks, where an agent must be able to precisely manipulate an object into a position that satisfies the task from a set of initial conditions. Often, task success is defined based on the relationship between two objects - for instance, hanging a mug on a rack. In such cases, the solution should be equivariant to the initial position of the objects as well as the agent, and invariant to the pose of the camera. This poses a challenge for learning systems which attempt to solve this task by learning directly from high-dimensional demonstrations: the agent must learn to be both equivariant as well as precise, which can be challenging without any inductive biases about the problem. In this work, we propose a method for precise relative pose prediction which is provably SE(3)-equivariant, can be learned from only a few demonstrations, and can generalize across variations in a class of objects. We accomplish this by factoring the problem into learning an SE(3) invariant task-specific representation of the scene and then interpreting this representation with novel geometric reasoning layers which are provably SE(3) equivariant. We demonstrate that our method can yield substantially more precise placement predictions in simulated placement tasks than previous methods trained with the same amount of data, and can accurately represent relative placement relationships data collected from real-world demonstrations. Supplementary information and videos can be found at https://sites.google.com/view/reldist-iclr-2023.
RoboTAP: Tracking Arbitrary Points for Few-Shot Visual Imitation
Aug 31, 2023



For robots to be useful outside labs and specialized factories we need a way to teach them new useful behaviors quickly. Current approaches lack either the generality to onboard new tasks without task-specific engineering, or else lack the data-efficiency to do so in an amount of time that enables practical use. In this work we explore dense tracking as a representational vehicle to allow faster and more general learning from demonstration. Our approach utilizes Track-Any-Point (TAP) models to isolate the relevant motion in a demonstration, and parameterize a low-level controller to reproduce this motion across changes in the scene configuration. We show this results in robust robot policies that can solve complex object-arrangement tasks such as shape-matching, stacking, and even full path-following tasks such as applying glue and sticking objects together, all from demonstrations that can be collected in minutes.
TAPIR: Tracking Any Point with per-frame Initialization and temporal Refinement
Jun 14, 2023We present a novel model for Tracking Any Point (TAP) that effectively tracks any queried point on any physical surface throughout a video sequence. Our approach employs two stages: (1) a matching stage, which independently locates a suitable candidate point match for the query point on every other frame, and (2) a refinement stage, which updates both the trajectory and query features based on local correlations. The resulting model surpasses all baseline methods by a significant margin on the TAP-Vid benchmark, as demonstrated by an approximate 20% absolute average Jaccard (AJ) improvement on DAVIS. Our model facilitates fast inference on long and high-resolution video sequences. On a modern GPU, our implementation has the capacity to track points faster than real-time. Visualizations, source code, and pretrained models can be found on our project webpage.
Few-Shot Keypoint Detection as Task Adaptation via Latent Embeddings
Dec 13, 2021
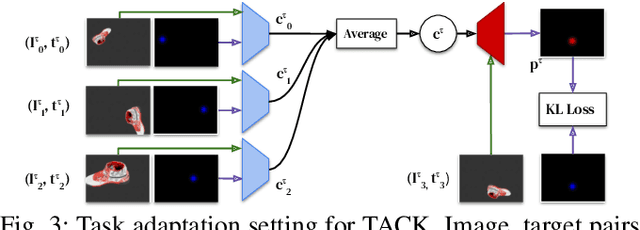
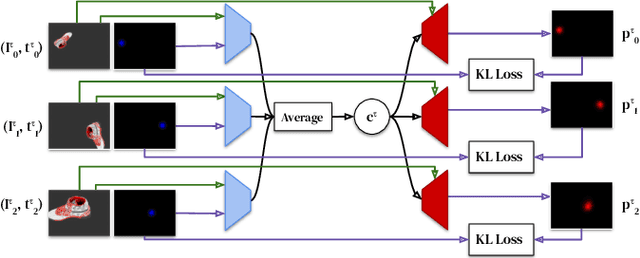
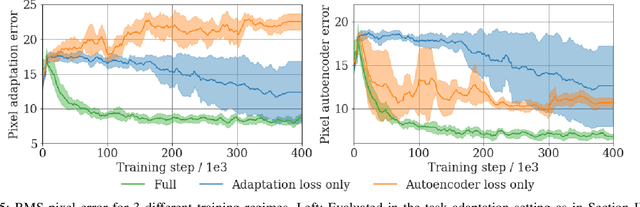
Dense object tracking, the ability to localize specific object points with pixel-level accuracy, is an important computer vision task with numerous downstream applications in robotics. Existing approaches either compute dense keypoint embeddings in a single forward pass, meaning the model is trained to track everything at once, or allocate their full capacity to a sparse predefined set of points, trading generality for accuracy. In this paper we explore a middle ground based on the observation that the number of relevant points at a given time are typically relatively few, e.g. grasp points on a target object. Our main contribution is a novel architecture, inspired by few-shot task adaptation, which allows a sparse-style network to condition on a keypoint embedding that indicates which point to track. Our central finding is that this approach provides the generality of dense-embedding models, while offering accuracy significantly closer to sparse-keypoint approaches. We present results illustrating this capacity vs. accuracy trade-off, and demonstrate the ability to zero-shot transfer to new object instances (within-class) using a real-robot pick-and-place task.
Robust Multi-Modal Policies for Industrial Assembly via Reinforcement Learning and Demonstrations: A Large-Scale Study
Mar 23, 2021


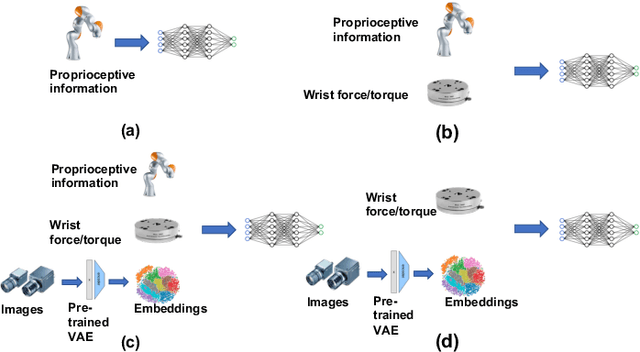
Over the past several years there has been a considerable research investment into learning-based approaches to industrial assembly, but despite significant progress these techniques have yet to be adopted by industry. We argue that it is the prohibitively large design space for Deep Reinforcement Learning (DRL), rather than algorithmic limitations per se, that are truly responsible for this lack of adoption. Pushing these techniques into the industrial mainstream requires an industry-oriented paradigm which differs significantly from the academic mindset. In this paper we define criteria for industry-oriented DRL, and perform a thorough comparison according to these criteria of one family of learning approaches, DRL from demonstration, against a professional industrial integrator on the recently established NIST assembly benchmark. We explain the design choices, representing several years of investigation, which enabled our DRL system to consistently outperform the integrator baseline in terms of both speed and reliability. Finally, we conclude with a competition between our DRL system and a human on a challenge task of insertion into a randomly moving target. This study suggests that DRL is capable of outperforming not only established engineered approaches, but the human motor system as well, and that there remains significant room for improvement. Videos can be found on our project website: https://sites.google.com/view/shield-nist.
S3K: Self-Supervised Semantic Keypoints for Robotic Manipulation via Multi-View Consistency
Oct 13, 2020

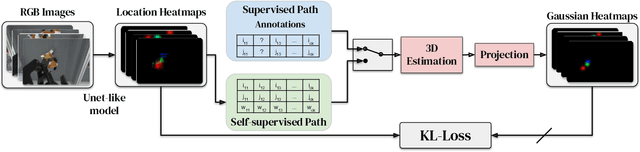
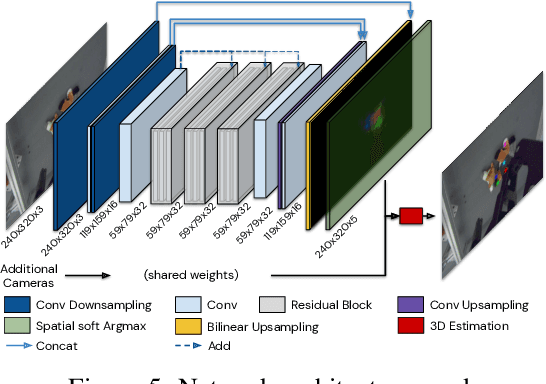
A robot's ability to act is fundamentally constrained by what it can perceive. Many existing approaches to visual representation learning utilize general-purpose training criteria, e.g. image reconstruction, smoothness in latent space, or usefulness for control, or else make use of large datasets annotated with specific features (bounding boxes, segmentations, etc.). However, both approaches often struggle to capture the fine-detail required for precision tasks on specific objects, e.g. grasping and mating a plug and socket. We argue that these difficulties arise from a lack of geometric structure in these models. In this work we advocate semantic 3D keypoints as a visual representation, and present a semi-supervised training objective that can allow instance or category-level keypoints to be trained to 1-5 millimeter-accuracy with minimal supervision. Furthermore, unlike local texture-based approaches, our model integrates contextual information from a large area and is therefore robust to occlusion, noise, and lack of discernible texture. We demonstrate that this ability to locate semantic keypoints enables high level scripting of human understandable behaviours. Finally we show that these keypoints provide a good way to define reward functions for reinforcement learning and are a good representation for training agents.
Improved Exploration through Latent Trajectory Optimization in Deep Deterministic Policy Gradient
Nov 15, 2019

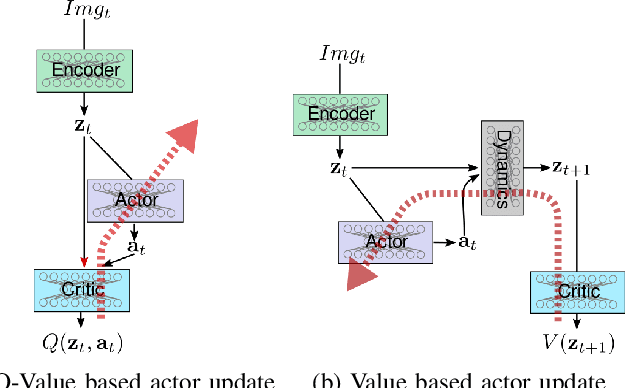
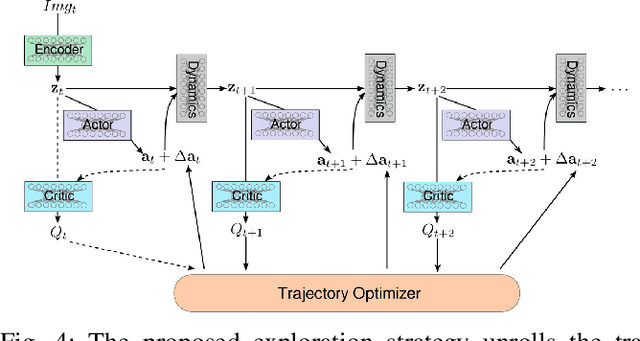
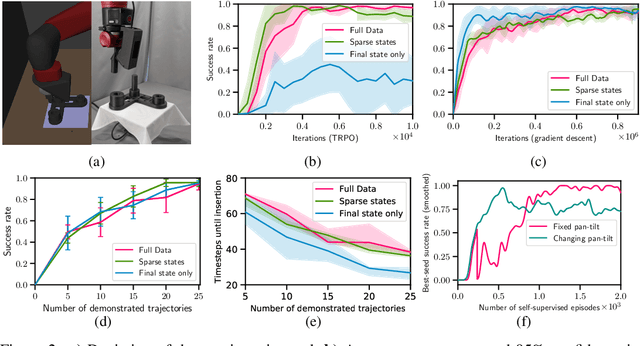
Model-free reinforcement learning algorithms such as Deep Deterministic Policy Gradient (DDPG) often require additional exploration strategies, especially if the actor is of deterministic nature. This work evaluates the use of model-based trajectory optimization methods used for exploration in Deep Deterministic Policy Gradient when trained on a latent image embedding. In addition, an extension of DDPG is derived using a value function as critic, making use of a learned deep dynamics model to compute the policy gradient. This approach leads to a symbiotic relationship between the deep reinforcement learning algorithm and the latent trajectory optimizer. The trajectory optimizer benefits from the critic learned by the RL algorithm and the latter from the enhanced exploration generated by the planner. The developed methods are evaluated on two continuous control tasks, one in simulation and one in the real world. In particular, a Baxter robot is trained to perform an insertion task, while only receiving sparse rewards and images as observations from the environment.
A Framework for Data-Driven Robotics
Sep 26, 2019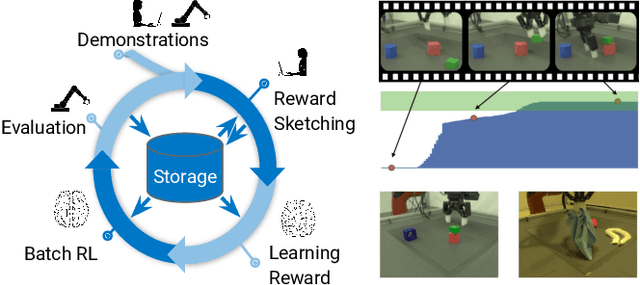
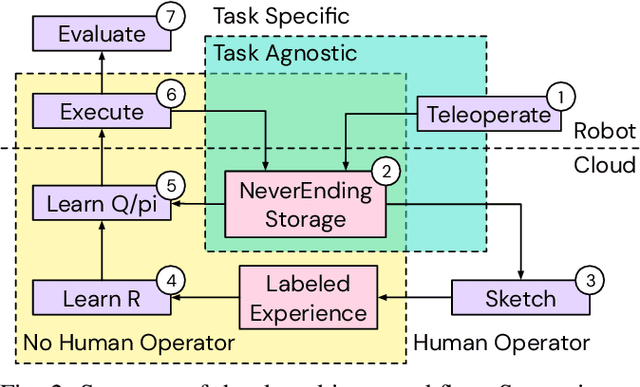
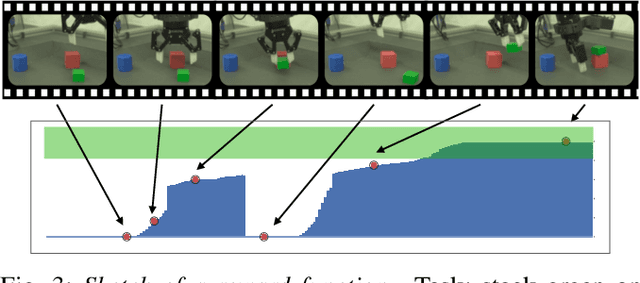
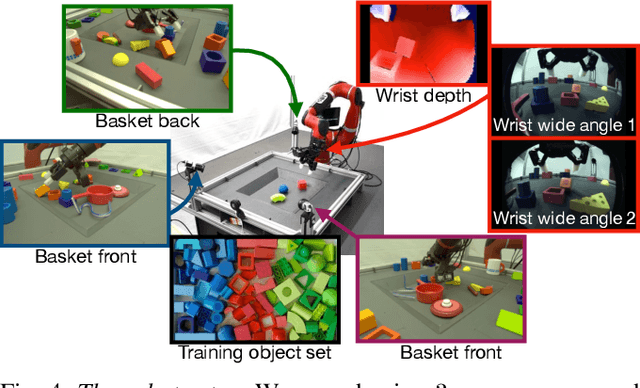
We present a framework for data-driven robotics that makes use of a large dataset of recorded robot experience and scales to several tasks using learned reward functions. We show how to apply this framework to accomplish three different object manipulation tasks on a real robot platform. Given demonstrations of a task together with task-agnostic recorded experience, we use a special form of human annotation as supervision to learn a reward function, which enables us to deal with real-world tasks where the reward signal cannot be acquired directly. Learned rewards are used in combination with a large dataset of experience from different tasks to learn a robot policy offline using batch RL. We show that using our approach it is possible to train agents to perform a variety of challenging manipulation tasks including stacking rigid objects and handling cloth.
Generative predecessor models for sample-efficient imitation learning
Apr 01, 2019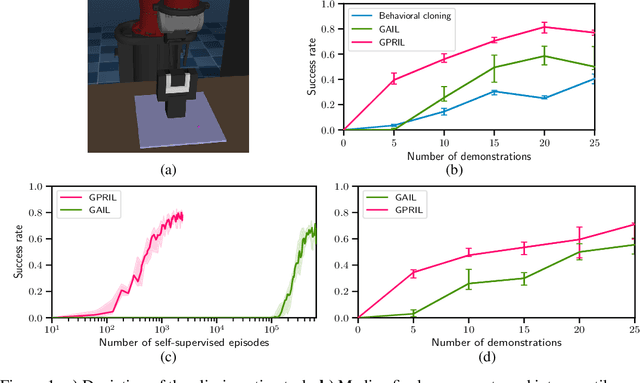
We propose Generative Predecessor Models for Imitation Learning (GPRIL), a novel imitation learning algorithm that matches the state-action distribution to the distribution observed in expert demonstrations, using generative models to reason probabilistically about alternative histories of demonstrated states. We show that this approach allows an agent to learn robust policies using only a small number of expert demonstrations and self-supervised interactions with the environment. We derive this approach from first principles and compare it empirically to a state-of-the-art imitation learning method, showing that it outperforms or matches its performance on two simulated robot manipulation tasks and demonstrate significantly higher sample efficiency by applying the algorithm on a real robot.