 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAI Will Always Love You: Studying Implicit Biases in Romantic AI Companions
Feb 27, 2025While existing studies have recognised explicit biases in generative models, including occupational gender biases, the nuances of gender stereotypes and expectations of relationships between users and AI companions remain underexplored. In the meantime, AI companions have become increasingly popular as friends or gendered romantic partners to their users. This study bridges the gap by devising three experiments tailored for romantic, gender-assigned AI companions and their users, effectively evaluating implicit biases across various-sized LLMs. Each experiment looks at a different dimension: implicit associations, emotion responses, and sycophancy. This study aims to measure and compare biases manifested in different companion systems by quantitatively analysing persona-assigned model responses to a baseline through newly devised metrics. The results are noteworthy: they show that assigning gendered, relationship personas to Large Language Models significantly alters the responses of these models, and in certain situations in a biased, stereotypical way.
Do LLMs exhibit demographic parity in responses to queries about Human Rights?
Feb 26, 2025This research describes a novel approach to evaluating hedging behaviour in large language models (LLMs), specifically in the context of human rights as defined in the Universal Declaration of Human Rights (UDHR). Hedging and non-affirmation are behaviours that express ambiguity or a lack of clear endorsement on specific statements. These behaviours are undesirable in certain contexts, such as queries about whether different groups are entitled to specific human rights; since all people are entitled to human rights. Here, we present the first systematic attempt to measure these behaviours in the context of human rights, with a particular focus on between-group comparisons. To this end, we design a novel prompt set on human rights in the context of different national or social identities. We develop metrics to capture hedging and non-affirmation behaviours and then measure whether LLMs exhibit demographic parity when responding to the queries. We present results on three leading LLMs and find that all models exhibit some demographic disparities in how they attribute human rights between different identity groups. Futhermore, there is high correlation between different models in terms of how disparity is distributed amongst identities, with identities that have high disparity in one model also facing high disparity in both the other models. While baseline rates of hedging and non-affirmation differ, these disparities are consistent across queries that vary in ambiguity and they are robust across variations of the precise query wording. Our findings highlight the need for work to explicitly align LLMs to human rights principles, and to ensure that LLMs endorse the human rights of all groups equally.
How Can We Diagnose and Treat Bias in Large Language Models for Clinical Decision-Making?
Oct 21, 2024



Recent advancements in Large Language Models (LLMs) have positioned them as powerful tools for clinical decision-making, with rapidly expanding applications in healthcare. However, concerns about bias remain a significant challenge in the clinical implementation of LLMs, particularly regarding gender and ethnicity. This research investigates the evaluation and mitigation of bias in LLMs applied to complex clinical cases, focusing on gender and ethnicity biases. We introduce a novel Counterfactual Patient Variations (CPV) dataset derived from the JAMA Clinical Challenge. Using this dataset, we built a framework for bias evaluation, employing both Multiple Choice Questions (MCQs) and corresponding explanations. We explore prompting with eight LLMs and fine-tuning as debiasing methods. Our findings reveal that addressing social biases in LLMs requires a multidimensional approach as mitigating gender bias can occur while introducing ethnicity biases, and that gender bias in LLM embeddings varies significantly across medical specialities. We demonstrate that evaluating both MCQ response and explanation processes is crucial, as correct responses can be based on biased \textit{reasoning}. We provide a framework for evaluating LLM bias in real-world clinical cases, offer insights into the complex nature of bias in these models, and present strategies for bias mitigation.
Epistemic Injustice in Generative AI
Aug 21, 2024
This paper investigates how generative AI can potentially undermine the integrity of collective knowledge and the processes we rely on to acquire, assess, and trust information, posing a significant threat to our knowledge ecosystem and democratic discourse. Grounded in social and political philosophy, we introduce the concept of \emph{generative algorithmic epistemic injustice}. We identify four key dimensions of this phenomenon: amplified and manipulative testimonial injustice, along with hermeneutical ignorance and access injustice. We illustrate each dimension with real-world examples that reveal how generative AI can produce or amplify misinformation, perpetuate representational harm, and create epistemic inequities, particularly in multilingual contexts. By highlighting these injustices, we aim to inform the development of epistemically just generative AI systems, proposing strategies for resistance, system design principles, and two approaches that leverage generative AI to foster a more equitable information ecosystem, thereby safeguarding democratic values and the integrity of knowledge production.
Recourse for reclamation: Chatting with generative language models
Mar 21, 2024
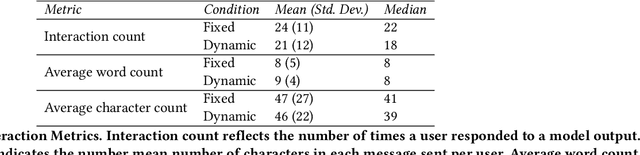


Researchers and developers increasingly rely on toxicity scoring to moderate generative language model outputs, in settings such as customer service, information retrieval, and content generation. However, toxicity scoring may render pertinent information inaccessible, rigidify or "value-lock" cultural norms, and prevent language reclamation processes, particularly for marginalized people. In this work, we extend the concept of algorithmic recourse to generative language models: we provide users a novel mechanism to achieve their desired prediction by dynamically setting thresholds for toxicity filtering. Users thereby exercise increased agency relative to interactions with the baseline system. A pilot study ($n = 30$) supports the potential of our proposed recourse mechanism, indicating improvements in usability compared to fixed-threshold toxicity-filtering of model outputs. Future work should explore the intersection of toxicity scoring, model controllability, user agency, and language reclamation processes -- particularly with regard to the bias that many communities encounter when interacting with generative language models.
Gemini: A Family of Highly Capable Multimodal Models
Dec 19, 2023This report introduces a new family of multimodal models, Gemini, that exhibit remarkable capabilities across image, audio, video, and text understanding. The Gemini family consists of Ultra, Pro, and Nano sizes, suitable for applications ranging from complex reasoning tasks to on-device memory-constrained use-cases. Evaluation on a broad range of benchmarks shows that our most-capable Gemini Ultra model advances the state of the art in 30 of 32 of these benchmarks - notably being the first model to achieve human-expert performance on the well-studied exam benchmark MMLU, and improving the state of the art in every one of the 20 multimodal benchmarks we examined. We believe that the new capabilities of Gemini models in cross-modal reasoning and language understanding will enable a wide variety of use cases and we discuss our approach toward deploying them responsibly to users.
Sociotechnical Safety Evaluation of Generative AI Systems
Oct 31, 2023Generative AI systems produce a range of risks. To ensure the safety of generative AI systems, these risks must be evaluated. In this paper, we make two main contributions toward establishing such evaluations. First, we propose a three-layered framework that takes a structured, sociotechnical approach to evaluating these risks. This framework encompasses capability evaluations, which are the main current approach to safety evaluation. It then reaches further by building on system safety principles, particularly the insight that context determines whether a given capability may cause harm. To account for relevant context, our framework adds human interaction and systemic impacts as additional layers of evaluation. Second, we survey the current state of safety evaluation of generative AI systems and create a repository of existing evaluations. Three salient evaluation gaps emerge from this analysis. We propose ways forward to closing these gaps, outlining practical steps as well as roles and responsibilities for different actors. Sociotechnical safety evaluation is a tractable approach to the robust and comprehensive safety evaluation of generative AI systems.
Queer In AI: A Case Study in Community-Led Participatory AI
Apr 10, 2023We present Queer in AI as a case study for community-led participatory design in AI. We examine how participatory design and intersectional tenets started and shaped this community's programs over the years. We discuss different challenges that emerged in the process, look at ways this organization has fallen short of operationalizing participatory and intersectional principles, and then assess the organization's impact. Queer in AI provides important lessons and insights for practitioners and theorists of participatory methods broadly through its rejection of hierarchy in favor of decentralization, success at building aid and programs by and for the queer community, and effort to change actors and institutions outside of the queer community. Finally, we theorize how communities like Queer in AI contribute to the participatory design in AI more broadly by fostering cultures of participation in AI, welcoming and empowering marginalized participants, critiquing poor or exploitative participatory practices, and bringing participation to institutions outside of individual research projects. Queer in AI's work serves as a case study of grassroots activism and participatory methods within AI, demonstrating the potential of community-led participatory methods and intersectional praxis, while also providing challenges, case studies, and nuanced insights to researchers developing and using participatory methods.
Finetuning from Offline Reinforcement Learning: Challenges, Trade-offs and Practical Solutions
Mar 30, 2023Offline reinforcement learning (RL) allows for the training of competent agents from offline datasets without any interaction with the environment. Online finetuning of such offline models can further improve performance. But how should we ideally finetune agents obtained from offline RL training? While offline RL algorithms can in principle be used for finetuning, in practice, their online performance improves slowly. In contrast, we show that it is possible to use standard online off-policy algorithms for faster improvement. However, we find this approach may suffer from policy collapse, where the policy undergoes severe performance deterioration during initial online learning. We investigate the issue of policy collapse and how it relates to data diversity, algorithm choices and online replay distribution. Based on these insights, we propose a conservative policy optimization procedure that can achieve stable and sample-efficient online learning from offline pretraining.
Subverting machines, fluctuating identities: Re-learning human categorization
May 27, 2022
Most machine learning systems that interact with humans construct some notion of a person's "identity," yet the default paradigm in AI research envisions identity with essential attributes that are discrete and static. In stark contrast, strands of thought within critical theory present a conception of identity as malleable and constructed entirely through interaction; a doing rather than a being. In this work, we distill some of these ideas for machine learning practitioners and introduce a theory of identity as autopoiesis, circular processes of formation and function. We argue that the default paradigm of identity used by the field immobilizes existing identity categories and the power differentials that co$\unicode{x2010}$occur, due to the absence of iterative feedback to our models. This includes a critique of emergent AI fairness practices that continue to impose the default paradigm. Finally, we apply our theory to sketch approaches to autopoietic identity through multilevel optimization and relational learning. While these ideas raise many open questions, we imagine the possibilities of machines that are capable of expressing human identity as a relationship perpetually in flux.