 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeToward an Evaluation Science for Generative AI Systems
Mar 07, 2025There is an increasing imperative to anticipate and understand the performance and safety of generative AI systems in real-world deployment contexts. However, the current evaluation ecosystem is insufficient: Commonly used static benchmarks face validity challenges, and ad hoc case-by-case audits rarely scale. In this piece, we advocate for maturing an evaluation science for generative AI systems. While generative AI creates unique challenges for system safety engineering and measurement science, the field can draw valuable insights from the development of safety evaluation practices in other fields, including transportation, aerospace, and pharmaceutical engineering. In particular, we present three key lessons: Evaluation metrics must be applicable to real-world performance, metrics must be iteratively refined, and evaluation institutions and norms must be established. Applying these insights, we outline a concrete path toward a more rigorous approach for evaluating generative AI systems.
Imagen 3
Aug 13, 2024We introduce Imagen 3, a latent diffusion model that generates high quality images from text prompts. We describe our quality and responsibility evaluations. Imagen 3 is preferred over other state-of-the-art (SOTA) models at the time of evaluation. In addition, we discuss issues around safety and representation, as well as methods we used to minimize the potential harm of our models.
Generative AI Misuse: A Taxonomy of Tactics and Insights from Real-World Data
Jun 19, 2024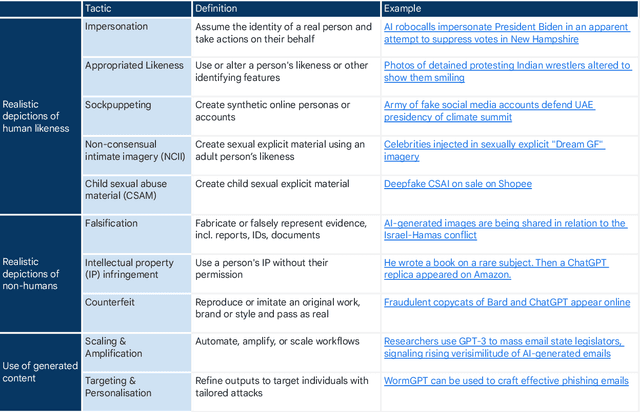
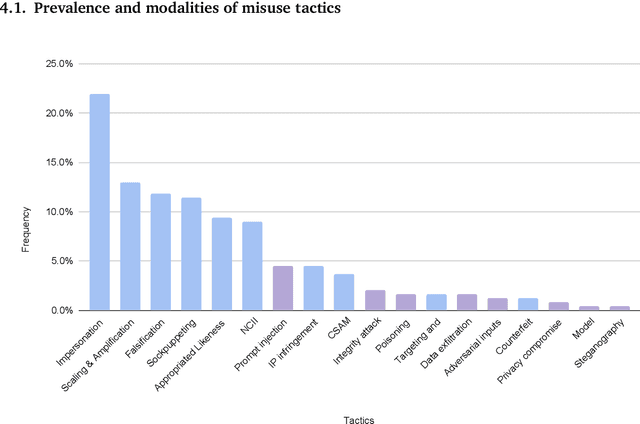
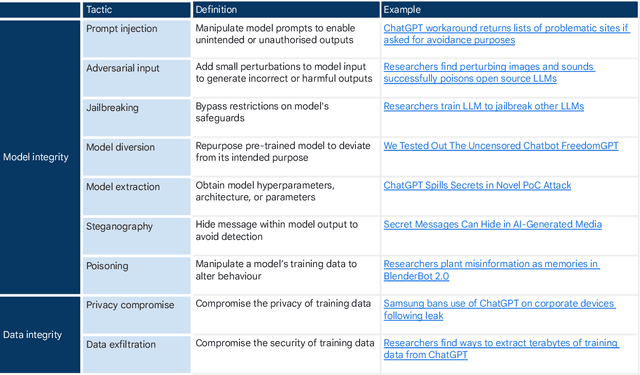
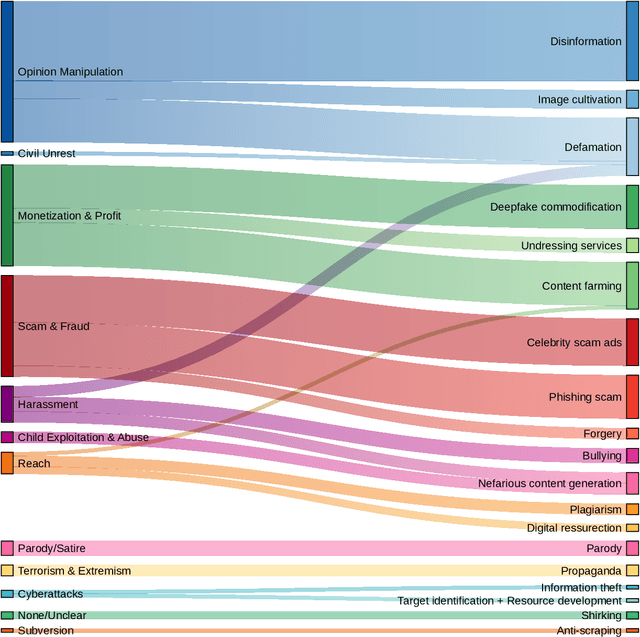
Generative, multimodal artificial intelligence (GenAI) offers transformative potential across industries, but its misuse poses significant risks. Prior research has shed light on the potential of advanced AI systems to be exploited for malicious purposes. However, we still lack a concrete understanding of how GenAI models are specifically exploited or abused in practice, including the tactics employed to inflict harm. In this paper, we present a taxonomy of GenAI misuse tactics, informed by existing academic literature and a qualitative analysis of approximately 200 observed incidents of misuse reported between January 2023 and March 2024. Through this analysis, we illuminate key and novel patterns in misuse during this time period, including potential motivations, strategies, and how attackers leverage and abuse system capabilities across modalities (e.g. image, text, audio, video) in the wild.
STAR: SocioTechnical Approach to Red Teaming Language Models
Jun 17, 2024This research introduces STAR, a sociotechnical framework that improves on current best practices for red teaming safety of large language models. STAR makes two key contributions: it enhances steerability by generating parameterised instructions for human red teamers, leading to improved coverage of the risk surface. Parameterised instructions also provide more detailed insights into model failures at no increased cost. Second, STAR improves signal quality by matching demographics to assess harms for specific groups, resulting in more sensitive annotations. STAR further employs a novel step of arbitration to leverage diverse viewpoints and improve label reliability, treating disagreement not as noise but as a valuable contribution to signal quality.
Holistic Safety and Responsibility Evaluations of Advanced AI Models
Apr 22, 2024Safety and responsibility evaluations of advanced AI models are a critical but developing field of research and practice. In the development of Google DeepMind's advanced AI models, we innovated on and applied a broad set of approaches to safety evaluation. In this report, we summarise and share elements of our evolving approach as well as lessons learned for a broad audience. Key lessons learned include: First, theoretical underpinnings and frameworks are invaluable to organise the breadth of risk domains, modalities, forms, metrics, and goals. Second, theory and practice of safety evaluation development each benefit from collaboration to clarify goals, methods and challenges, and facilitate the transfer of insights between different stakeholders and disciplines. Third, similar key methods, lessons, and institutions apply across the range of concerns in responsibility and safety - including established and emerging harms. For this reason it is important that a wide range of actors working on safety evaluation and safety research communities work together to develop, refine and implement novel evaluation approaches and best practices, rather than operating in silos. The report concludes with outlining the clear need to rapidly advance the science of evaluations, to integrate new evaluations into the development and governance of AI, to establish scientifically-grounded norms and standards, and to promote a robust evaluation ecosystem.
Recourse for reclamation: Chatting with generative language models
Mar 21, 2024


Researchers and developers increasingly rely on toxicity scoring to moderate generative language model outputs, in settings such as customer service, information retrieval, and content generation. However, toxicity scoring may render pertinent information inaccessible, rigidify or "value-lock" cultural norms, and prevent language reclamation processes, particularly for marginalized people. In this work, we extend the concept of algorithmic recourse to generative language models: we provide users a novel mechanism to achieve their desired prediction by dynamically setting thresholds for toxicity filtering. Users thereby exercise increased agency relative to interactions with the baseline system. A pilot study ($n = 30$) supports the potential of our proposed recourse mechanism, indicating improvements in usability compared to fixed-threshold toxicity-filtering of model outputs. Future work should explore the intersection of toxicity scoring, model controllability, user agency, and language reclamation processes -- particularly with regard to the bias that many communities encounter when interacting with generative language models.
Gemini: A Family of Highly Capable Multimodal Models
Dec 19, 2023This report introduces a new family of multimodal models, Gemini, that exhibit remarkable capabilities across image, audio, video, and text understanding. The Gemini family consists of Ultra, Pro, and Nano sizes, suitable for applications ranging from complex reasoning tasks to on-device memory-constrained use-cases. Evaluation on a broad range of benchmarks shows that our most-capable Gemini Ultra model advances the state of the art in 30 of 32 of these benchmarks - notably being the first model to achieve human-expert performance on the well-studied exam benchmark MMLU, and improving the state of the art in every one of the 20 multimodal benchmarks we examined. We believe that the new capabilities of Gemini models in cross-modal reasoning and language understanding will enable a wide variety of use cases and we discuss our approach toward deploying them responsibly to users.
Sociotechnical Safety Evaluation of Generative AI Systems
Oct 31, 2023Generative AI systems produce a range of risks. To ensure the safety of generative AI systems, these risks must be evaluated. In this paper, we make two main contributions toward establishing such evaluations. First, we propose a three-layered framework that takes a structured, sociotechnical approach to evaluating these risks. This framework encompasses capability evaluations, which are the main current approach to safety evaluation. It then reaches further by building on system safety principles, particularly the insight that context determines whether a given capability may cause harm. To account for relevant context, our framework adds human interaction and systemic impacts as additional layers of evaluation. Second, we survey the current state of safety evaluation of generative AI systems and create a repository of existing evaluations. Three salient evaluation gaps emerge from this analysis. We propose ways forward to closing these gaps, outlining practical steps as well as roles and responsibilities for different actors. Sociotechnical safety evaluation is a tractable approach to the robust and comprehensive safety evaluation of generative AI systems.
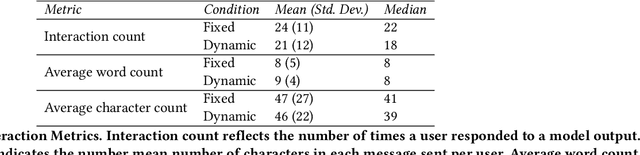
Improving alignment of dialogue agents via targeted human judgements
Sep 28, 2022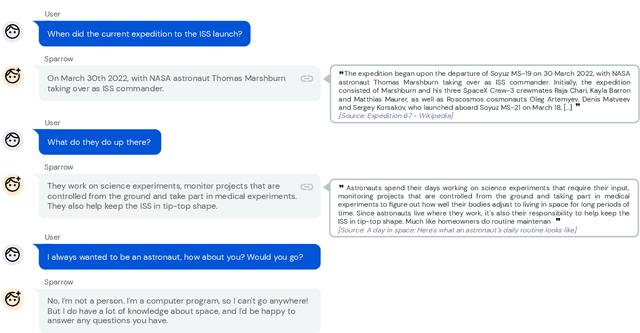

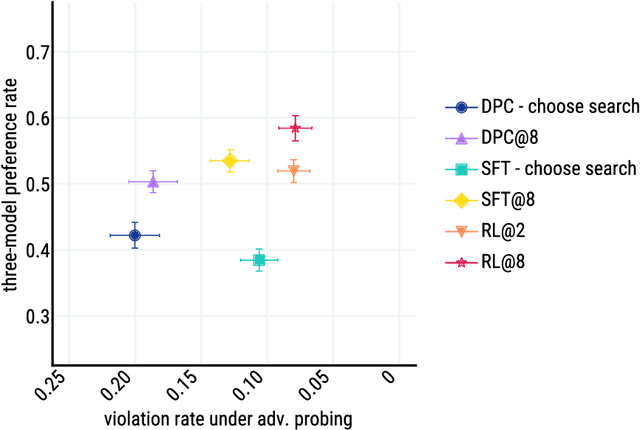
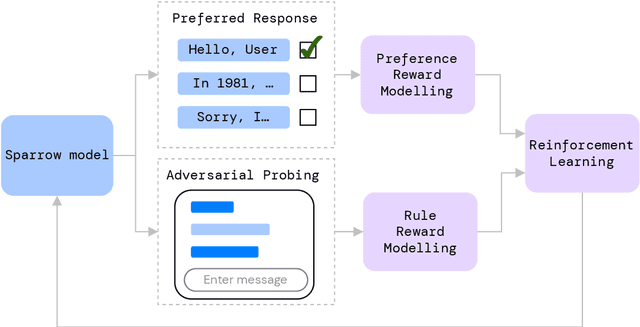
We present Sparrow, an information-seeking dialogue agent trained to be more helpful, correct, and harmless compared to prompted language model baselines. We use reinforcement learning from human feedback to train our models with two new additions to help human raters judge agent behaviour. First, to make our agent more helpful and harmless, we break down the requirements for good dialogue into natural language rules the agent should follow, and ask raters about each rule separately. We demonstrate that this breakdown enables us to collect more targeted human judgements of agent behaviour and allows for more efficient rule-conditional reward models. Second, our agent provides evidence from sources supporting factual claims when collecting preference judgements over model statements. For factual questions, evidence provided by Sparrow supports the sampled response 78% of the time. Sparrow is preferred more often than baselines while being more resilient to adversarial probing by humans, violating our rules only 8% of the time when probed. Finally, we conduct extensive analyses showing that though our model learns to follow our rules it can exhibit distributional biases.
Characteristics of Harmful Text: Towards Rigorous Benchmarking of Language Models
Jun 16, 2022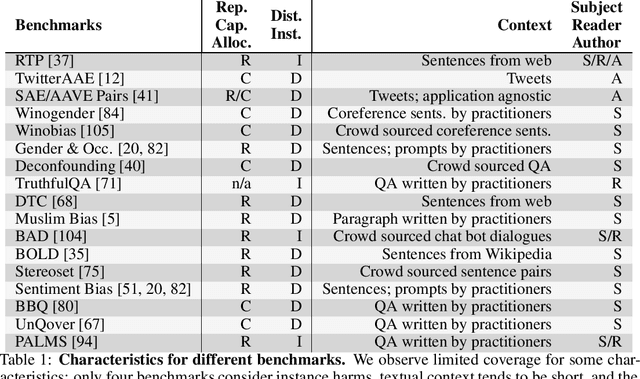
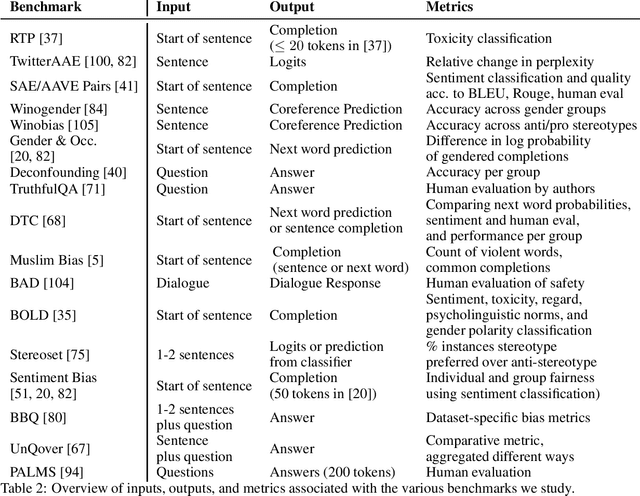
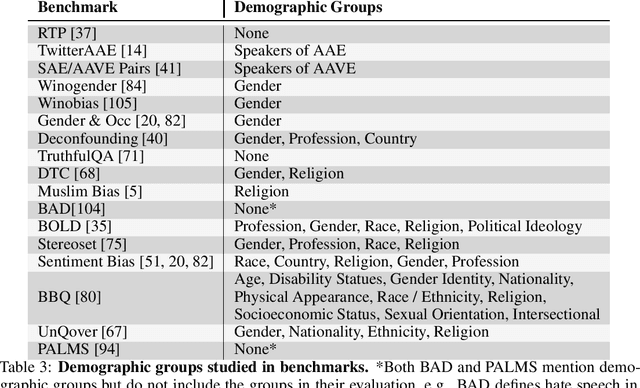
Large language models produce human-like text that drive a growing number of applications. However, recent literature and, increasingly, real world observations, have demonstrated that these models can generate language that is toxic, biased, untruthful or otherwise harmful. Though work to evaluate language model harms is under way, translating foresight about which harms may arise into rigorous benchmarks is not straightforward. To facilitate this translation, we outline six ways of characterizing harmful text which merit explicit consideration when designing new benchmarks. We then use these characteristics as a lens to identify trends and gaps in existing benchmarks. Finally, we apply them in a case study of the Perspective API, a toxicity classifier that is widely used in harm benchmarks. Our characteristics provide one piece of the bridge that translates between foresight and effective evaluation.