 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnderstanding challenges to the interpretation of disaggregated evaluations of algorithmic fairness
Jun 04, 2025Disaggregated evaluation across subgroups is critical for assessing the fairness of machine learning models, but its uncritical use can mislead practitioners. We show that equal performance across subgroups is an unreliable measure of fairness when data are representative of the relevant populations but reflective of real-world disparities. Furthermore, when data are not representative due to selection bias, both disaggregated evaluation and alternative approaches based on conditional independence testing may be invalid without explicit assumptions regarding the bias mechanism. We use causal graphical models to predict metric stability across subgroups under different data generating processes. Our framework suggests complementing disaggregated evaluations with explicit causal assumptions and analysis to control for confounding and distribution shift, including conditional independence testing and weighted performance estimation. These findings have broad implications for how practitioners design and interpret model assessments given the ubiquity of disaggregated evaluation.
Measurement to Meaning: A Validity-Centered Framework for AI Evaluation
May 13, 2025While the capabilities and utility of AI systems have advanced, rigorous norms for evaluating these systems have lagged. Grand claims, such as models achieving general reasoning capabilities, are supported with model performance on narrow benchmarks, like performance on graduate-level exam questions, which provide a limited and potentially misleading assessment. We provide a structured approach for reasoning about the types of evaluative claims that can be made given the available evidence. For instance, our framework helps determine whether performance on a mathematical benchmark is an indication of the ability to solve problems on math tests or instead indicates a broader ability to reason. Our framework is well-suited for the contemporary paradigm in machine learning, where various stakeholders provide measurements and evaluations that downstream users use to validate their claims and decisions. At the same time, our framework also informs the construction of evaluations designed to speak to the validity of the relevant claims. By leveraging psychometrics' breakdown of validity, evaluations can prioritize the most critical facets for a given claim, improving empirical utility and decision-making efficacy. We illustrate our framework through detailed case studies of vision and language model evaluations, highlighting how explicitly considering validity strengthens the connection between evaluation evidence and the claims being made.
Are Domain Generalization Benchmarks with Accuracy on the Line Misspecified?
Mar 31, 2025Spurious correlations are unstable statistical associations that hinder robust decision-making. Conventional wisdom suggests that models relying on such correlations will fail to generalize out-of-distribution (OOD), especially under strong distribution shifts. However, empirical evidence challenges this view as naive in-distribution empirical risk minimizers often achieve the best OOD accuracy across popular OOD generalization benchmarks. In light of these results, we propose a different perspective: many widely used benchmarks for evaluating robustness to spurious correlations are misspecified. Specifically, they fail to include shifts in spurious correlations that meaningfully impact OOD generalization, making them unsuitable for evaluating the benefit of removing such correlations. We establish conditions under which a distribution shift can reliably assess a model's reliance on spurious correlations. Crucially, under these conditions, we should not observe a strong positive correlation between in-distribution and OOD accuracy, often called "accuracy on the line." Yet, most state-of-the-art benchmarks exhibit this pattern, suggesting they do not effectively assess robustness. Our findings expose a key limitation in current benchmarks used to evaluate domain generalization algorithms, that is, models designed to avoid spurious correlations. We highlight the need to rethink how robustness to spurious correlations is assessed, identify well-specified benchmarks the field should prioritize, and enumerate strategies for designing future benchmarks that meaningfully reflect robustness under distribution shift.
Toward an Evaluation Science for Generative AI Systems
Mar 07, 2025There is an increasing imperative to anticipate and understand the performance and safety of generative AI systems in real-world deployment contexts. However, the current evaluation ecosystem is insufficient: Commonly used static benchmarks face validity challenges, and ad hoc case-by-case audits rarely scale. In this piece, we advocate for maturing an evaluation science for generative AI systems. While generative AI creates unique challenges for system safety engineering and measurement science, the field can draw valuable insights from the development of safety evaluation practices in other fields, including transportation, aerospace, and pharmaceutical engineering. In particular, we present three key lessons: Evaluation metrics must be applicable to real-world performance, metrics must be iteratively refined, and evaluation institutions and norms must be established. Applying these insights, we outline a concrete path toward a more rigorous approach for evaluating generative AI systems.
What's in a Query: Polarity-Aware Distribution-Based Fair Ranking
Feb 17, 2025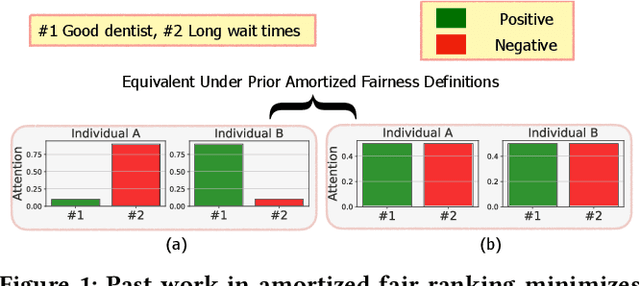
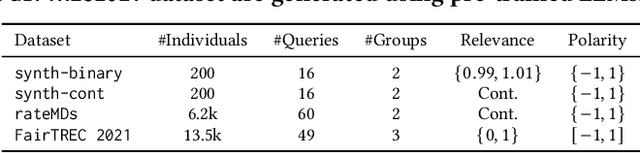
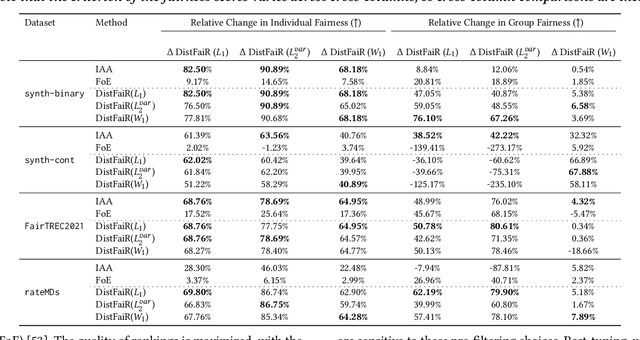
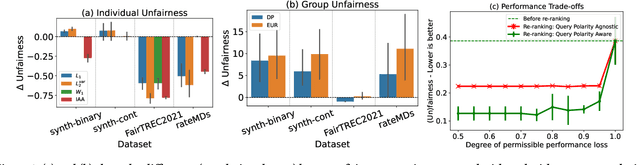
Machine learning-driven rankings, where individuals (or items) are ranked in response to a query, mediate search exposure or attention in a variety of safety-critical settings. Thus, it is important to ensure that such rankings are fair. Under the goal of equal opportunity, attention allocated to an individual on a ranking interface should be proportional to their relevance across search queries. In this work, we examine amortized fair ranking -- where relevance and attention are cumulated over a sequence of user queries to make fair ranking more feasible in practice. Unlike prior methods that operate on expected amortized attention for each individual, we define new divergence-based measures for attention distribution-based fairness in ranking (DistFaiR), characterizing unfairness as the divergence between the distribution of attention and relevance corresponding to an individual over time. This allows us to propose new definitions of unfairness, which are more reliable at test time. Second, we prove that group fairness is upper-bounded by individual fairness under this definition for a useful class of divergence measures, and experimentally show that maximizing individual fairness through an integer linear programming-based optimization is often beneficial to group fairness. Lastly, we find that prior research in amortized fair ranking ignores critical information about queries, potentially leading to a fairwashing risk in practice by making rankings appear more fair than they actually are.
Causally Inspired Regularization Enables Domain General Representations
Apr 25, 2024Given a causal graph representing the data-generating process shared across different domains/distributions, enforcing sufficient graph-implied conditional independencies can identify domain-general (non-spurious) feature representations. For the standard input-output predictive setting, we categorize the set of graphs considered in the literature into two distinct groups: (i) those in which the empirical risk minimizer across training domains gives domain-general representations and (ii) those where it does not. For the latter case (ii), we propose a novel framework with regularizations, which we demonstrate are sufficient for identifying domain-general feature representations without a priori knowledge (or proxies) of the spurious features. Empirically, our proposed method is effective for both (semi) synthetic and real-world data, outperforming other state-of-the-art methods in average and worst-domain transfer accuracy.
ImageNot: A contrast with ImageNet preserves model rankings
Apr 02, 2024We introduce ImageNot, a dataset designed to match the scale of ImageNet while differing drastically in other aspects. We show that key model architectures developed for ImageNet over the years rank identically when trained and evaluated on ImageNot to how they rank on ImageNet. This is true when training models from scratch or fine-tuning them. Moreover, the relative improvements of each model over earlier models strongly correlate in both datasets. We further give evidence that ImageNot has a similar utility as ImageNet for transfer learning purposes. Our work demonstrates a surprising degree of external validity in the relative performance of image classification models. This stands in contrast with absolute accuracy numbers that typically drop sharply even under small changes to a dataset.
Proxy Methods for Domain Adaptation
Mar 12, 2024We study the problem of domain adaptation under distribution shift, where the shift is due to a change in the distribution of an unobserved, latent variable that confounds both the covariates and the labels. In this setting, neither the covariate shift nor the label shift assumptions apply. Our approach to adaptation employs proximal causal learning, a technique for estimating causal effects in settings where proxies of unobserved confounders are available. We demonstrate that proxy variables allow for adaptation to distribution shift without explicitly recovering or modeling latent variables. We consider two settings, (i) Concept Bottleneck: an additional ''concept'' variable is observed that mediates the relationship between the covariates and labels; (ii) Multi-domain: training data from multiple source domains is available, where each source domain exhibits a different distribution over the latent confounder. We develop a two-stage kernel estimation approach to adapt to complex distribution shifts in both settings. In our experiments, we show that our approach outperforms other methods, notably those which explicitly recover the latent confounder.
Target Conditioned Representation Independence (TCRI); From Domain-Invariant to Domain-General Representations
Dec 21, 2022



We propose a Target Conditioned Representation Independence (TCRI) objective for domain generalization. TCRI addresses the limitations of existing domain generalization methods due to incomplete constraints. Specifically, TCRI implements regularizers motivated by conditional independence constraints that are sufficient to strictly learn complete sets of invariant mechanisms, which we show are necessary and sufficient for domain generalization. Empirically, we show that TCRI is effective on both synthetic and real-world data. TCRI is competitive with baselines in average accuracy while outperforming them in worst-domain accuracy, indicating desired cross-domain stability.
Adapting to Latent Subgroup Shifts via Concepts and Proxies
Dec 21, 2022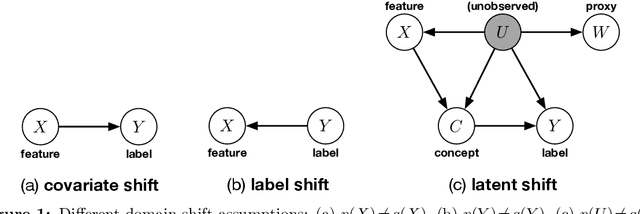

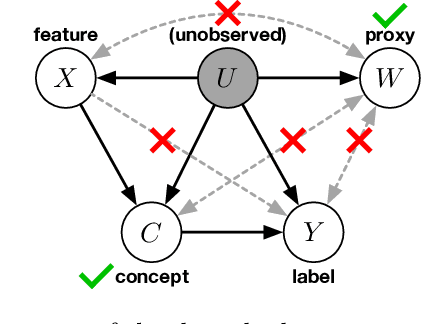
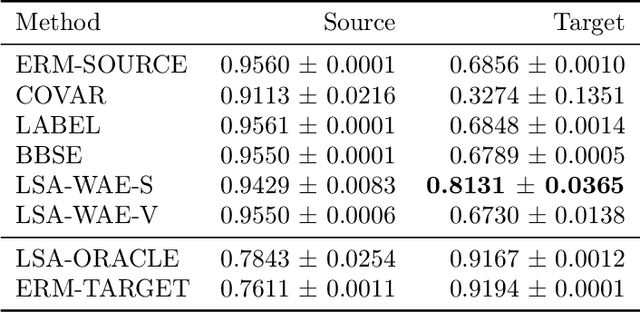
We address the problem of unsupervised domain adaptation when the source domain differs from the target domain because of a shift in the distribution of a latent subgroup. When this subgroup confounds all observed data, neither covariate shift nor label shift assumptions apply. We show that the optimal target predictor can be non-parametrically identified with the help of concept and proxy variables available only in the source domain, and unlabeled data from the target. The identification results are constructive, immediately suggesting an algorithm for estimating the optimal predictor in the target. For continuous observations, when this algorithm becomes impractical, we propose a latent variable model specific to the data generation process at hand. We show how the approach degrades as the size of the shift changes, and verify that it outperforms both covariate and label shift adjustment.