 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAre Domain Generalization Benchmarks with Accuracy on the Line Misspecified?
Mar 31, 2025Spurious correlations are unstable statistical associations that hinder robust decision-making. Conventional wisdom suggests that models relying on such correlations will fail to generalize out-of-distribution (OOD), especially under strong distribution shifts. However, empirical evidence challenges this view as naive in-distribution empirical risk minimizers often achieve the best OOD accuracy across popular OOD generalization benchmarks. In light of these results, we propose a different perspective: many widely used benchmarks for evaluating robustness to spurious correlations are misspecified. Specifically, they fail to include shifts in spurious correlations that meaningfully impact OOD generalization, making them unsuitable for evaluating the benefit of removing such correlations. We establish conditions under which a distribution shift can reliably assess a model's reliance on spurious correlations. Crucially, under these conditions, we should not observe a strong positive correlation between in-distribution and OOD accuracy, often called "accuracy on the line." Yet, most state-of-the-art benchmarks exhibit this pattern, suggesting they do not effectively assess robustness. Our findings expose a key limitation in current benchmarks used to evaluate domain generalization algorithms, that is, models designed to avoid spurious correlations. We highlight the need to rethink how robustness to spurious correlations is assessed, identify well-specified benchmarks the field should prioritize, and enumerate strategies for designing future benchmarks that meaningfully reflect robustness under distribution shift.
Proxy Methods for Domain Adaptation
Mar 12, 2024We study the problem of domain adaptation under distribution shift, where the shift is due to a change in the distribution of an unobserved, latent variable that confounds both the covariates and the labels. In this setting, neither the covariate shift nor the label shift assumptions apply. Our approach to adaptation employs proximal causal learning, a technique for estimating causal effects in settings where proxies of unobserved confounders are available. We demonstrate that proxy variables allow for adaptation to distribution shift without explicitly recovering or modeling latent variables. We consider two settings, (i) Concept Bottleneck: an additional ''concept'' variable is observed that mediates the relationship between the covariates and labels; (ii) Multi-domain: training data from multiple source domains is available, where each source domain exhibits a different distribution over the latent confounder. We develop a two-stage kernel estimation approach to adapt to complex distribution shifts in both settings. In our experiments, we show that our approach outperforms other methods, notably those which explicitly recover the latent confounder.
Adapting to Latent Subgroup Shifts via Concepts and Proxies
Dec 21, 2022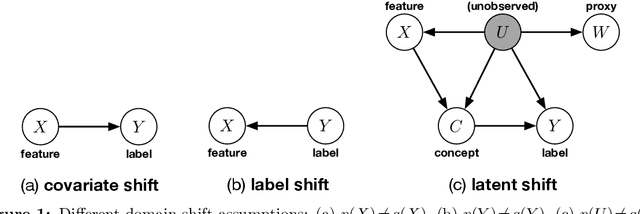

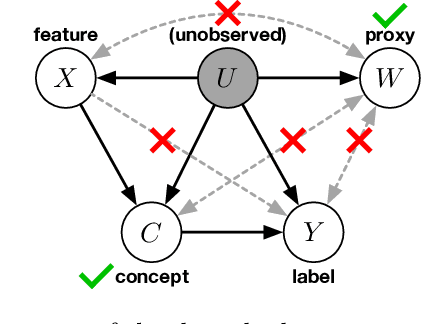
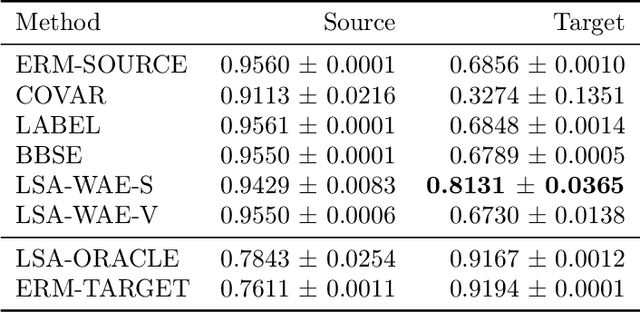
We address the problem of unsupervised domain adaptation when the source domain differs from the target domain because of a shift in the distribution of a latent subgroup. When this subgroup confounds all observed data, neither covariate shift nor label shift assumptions apply. We show that the optimal target predictor can be non-parametrically identified with the help of concept and proxy variables available only in the source domain, and unlabeled data from the target. The identification results are constructive, immediately suggesting an algorithm for estimating the optimal predictor in the target. For continuous observations, when this algorithm becomes impractical, we propose a latent variable model specific to the data generation process at hand. We show how the approach degrades as the size of the shift changes, and verify that it outperforms both covariate and label shift adjustment.