 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Physical Operators using Neural Operators
Feb 26, 2026Neural operators have emerged as promising surrogate models for solving partial differential equations (PDEs), but struggle to generalise beyond training distributions and are often constrained to a fixed temporal discretisation. This work introduces a physics-informed training framework that addresses these limitations by decomposing PDEs using operator splitting methods, training separate neural operators to learn individual non-linear physical operators while approximating linear operators with fixed finite-difference convolutions. This modular mixture-of-experts architecture enables generalisation to novel physical regimes by explicitly encoding the underlying operator structure. We formulate the modelling task as a neural ordinary differential equation (ODE) where these learned operators constitute the right-hand side, enabling continuous-in-time predictions through standard ODE solvers and implicitly enforcing PDE constraints. Demonstrated on incompressible and compressible Navier-Stokes equations, our approach achieves better convergence and superior performance when generalising to unseen physics. The method remains parameter-efficient, enabling temporal extrapolation beyond training horizons, and provides interpretable components whose behaviour can be verified against known physics.
Agentic Uncertainty Reveals Agentic Overconfidence
Feb 06, 2026Can AI agents predict whether they will succeed at a task? We study agentic uncertainty by eliciting success probability estimates before, during, and after task execution. All results exhibit agentic overconfidence: some agents that succeed only 22% of the time predict 77% success. Counterintuitively, pre-execution assessment with strictly less information tends to yield better discrimination than standard post-execution review, though differences are not always significant. Adversarial prompting reframing assessment as bug-finding achieves the best calibration.
Calibrated Physics-Informed Uncertainty Quantification
Feb 06, 2025Neural PDEs offer efficient alternatives to computationally expensive numerical PDE solvers for simulating complex physical systems. However, their lack of robust uncertainty quantification (UQ) limits deployment in critical applications. We introduce a model-agnostic, physics-informed conformal prediction (CP) framework that provides guaranteed uncertainty estimates without requiring labelled data. By utilising a physics-based approach, we are able to quantify and calibrate the model's inconsistencies with the PDE rather than the uncertainty arising from the data. Our approach uses convolutional layers as finite-difference stencils and leverages physics residual errors as nonconformity scores, enabling data-free UQ with marginal and joint coverage guarantees across prediction domains for a range of complex PDEs. We further validate the efficacy of our method on neural PDE models for plasma modelling and shot design in fusion reactors.
When Can Proxies Improve the Sample Complexity of Preference Learning?
Dec 21, 2024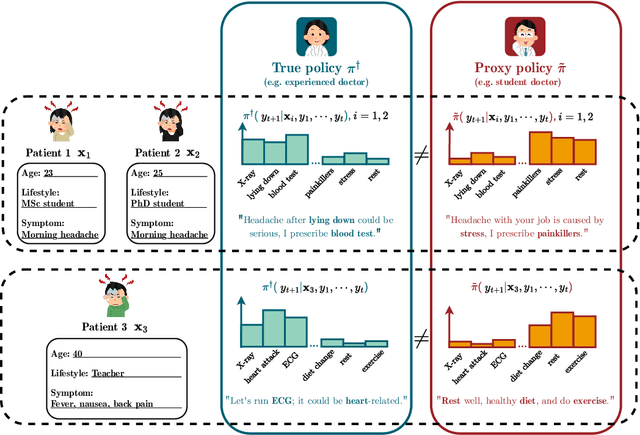
We address the problem of reward hacking, where maximising a proxy reward does not necessarily increase the true reward. This is a key concern for Large Language Models (LLMs), as they are often fine-tuned on human preferences that may not accurately reflect a true objective. Existing work uses various tricks such as regularisation, tweaks to the reward model, and reward hacking detectors, to limit the influence that such proxy preferences have on a model. Luckily, in many contexts such as medicine, education, and law, a sparse amount of expert data is often available. In these cases, it is often unclear whether the addition of proxy data can improve policy learning. We outline a set of sufficient conditions on proxy feedback that, if satisfied, indicate that proxy data can provably improve the sample complexity of learning the ground truth policy. These conditions can inform the data collection process for specific tasks. The result implies a parameterisation for LLMs that achieves this improved sample complexity. We detail how one can adapt existing architectures to yield this improved sample complexity.
An Auditing Test To Detect Behavioral Shift in Language Models
Oct 25, 2024



As language models (LMs) approach human-level performance, a comprehensive understanding of their behavior becomes crucial. This includes evaluating capabilities, biases, task performance, and alignment with societal values. Extensive initial evaluations, including red teaming and diverse benchmarking, can establish a model's behavioral profile. However, subsequent fine-tuning or deployment modifications may alter these behaviors in unintended ways. We present a method for continual Behavioral Shift Auditing (BSA) in LMs. Building on recent work in hypothesis testing, our auditing test detects behavioral shifts solely through model generations. Our test compares model generations from a baseline model to those of the model under scrutiny and provides theoretical guarantees for change detection while controlling false positives. The test features a configurable tolerance parameter that adjusts sensitivity to behavioral changes for different use cases. We evaluate our approach using two case studies: monitoring changes in (a) toxicity and (b) translation performance. We find that the test is able to detect meaningful changes in behavior distributions using just hundreds of examples.
Proxy Methods for Domain Adaptation
Mar 12, 2024We study the problem of domain adaptation under distribution shift, where the shift is due to a change in the distribution of an unobserved, latent variable that confounds both the covariates and the labels. In this setting, neither the covariate shift nor the label shift assumptions apply. Our approach to adaptation employs proximal causal learning, a technique for estimating causal effects in settings where proxies of unobserved confounders are available. We demonstrate that proxy variables allow for adaptation to distribution shift without explicitly recovering or modeling latent variables. We consider two settings, (i) Concept Bottleneck: an additional ''concept'' variable is observed that mediates the relationship between the covariates and labels; (ii) Multi-domain: training data from multiple source domains is available, where each source domain exhibits a different distribution over the latent confounder. We develop a two-stage kernel estimation approach to adapt to complex distribution shifts in both settings. In our experiments, we show that our approach outperforms other methods, notably those which explicitly recover the latent confounder.
Setting the Record Straight on Transformer Oversmoothing
Jan 09, 2024

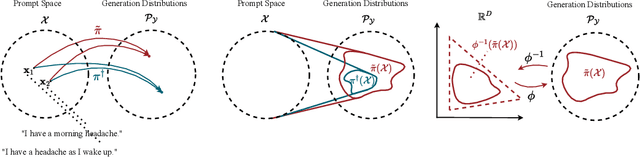
Transformer-based models have recently become wildly successful across a diverse set of domains. At the same time, recent work has shown that Transformers are inherently low-pass filters that gradually oversmooth the inputs, reducing the expressivity of their representations. A natural question is: How can Transformers achieve these successes given this shortcoming? In this work we show that in fact Transformers are not inherently low-pass filters. Instead, whether Transformers oversmooth or not depends on the eigenspectrum of their update equations. Our analysis extends prior work in oversmoothing and in the closely-related phenomenon of rank collapse. We show that many successful Transformer models have attention and weights which satisfy conditions that avoid oversmoothing. Based on this analysis, we derive a simple way to parameterize the weights of the Transformer update equations that allows for control over its spectrum, ensuring that oversmoothing does not occur. Compared to a recent solution for oversmoothing, our approach improves generalization, even when training with more layers, fewer datapoints, and data that is corrupted.
No Train No Gain: Revisiting Efficient Training Algorithms For Transformer-based Language Models
Jul 26, 2023The computation necessary for training Transformer-based language models has skyrocketed in recent years. This trend has motivated research on efficient training algorithms designed to improve training, validation, and downstream performance faster than standard training. In this work, we revisit three categories of such algorithms: dynamic architectures (layer stacking, layer dropping), batch selection (selective backprop, RHO loss), and efficient optimizers (Lion, Sophia). When pre-training BERT and T5 with a fixed computation budget using such methods, we find that their training, validation, and downstream gains vanish compared to a baseline with a fully-decayed learning rate. We define an evaluation protocol that enables computation to be done on arbitrary machines by mapping all computation time to a reference machine which we call reference system time. We discuss the limitations of our proposed protocol and release our code to encourage rigorous research in efficient training procedures: https://github.com/JeanKaddour/NoTrainNoGain.
DAG Learning on the Permutahedron
Feb 10, 2023We propose a continuous optimization framework for discovering a latent directed acyclic graph (DAG) from observational data. Our approach optimizes over the polytope of permutation vectors, the so-called Permutahedron, to learn a topological ordering. Edges can be optimized jointly, or learned conditional on the ordering via a non-differentiable subroutine. Compared to existing continuous optimization approaches our formulation has a number of advantages including: 1. validity: optimizes over exact DAGs as opposed to other relaxations optimizing approximate DAGs; 2. modularity: accommodates any edge-optimization procedure, edge structural parameterization, and optimization loss; 3. end-to-end: either alternately iterates between node-ordering and edge-optimization, or optimizes them jointly. We demonstrate, on real-world data problems in protein-signaling and transcriptional network discovery, that our approach lies on the Pareto frontier of two key metrics, the SID and SHD.
Adapting to Latent Subgroup Shifts via Concepts and Proxies
Dec 21, 2022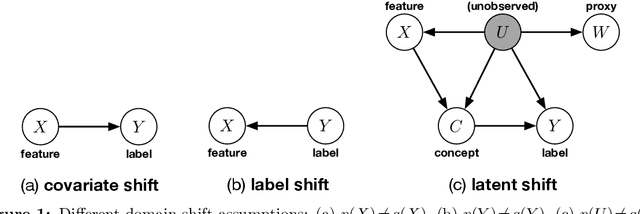

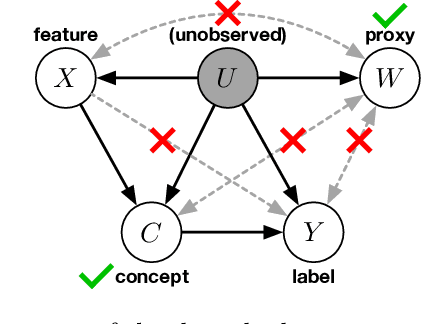
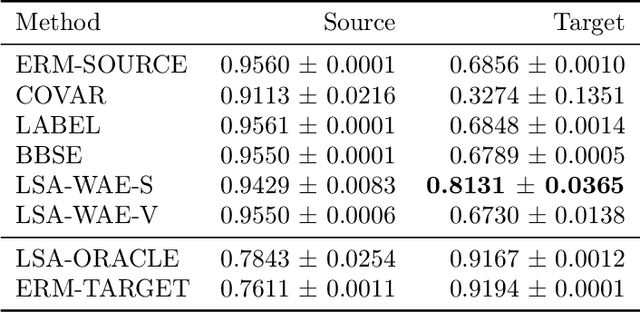
We address the problem of unsupervised domain adaptation when the source domain differs from the target domain because of a shift in the distribution of a latent subgroup. When this subgroup confounds all observed data, neither covariate shift nor label shift assumptions apply. We show that the optimal target predictor can be non-parametrically identified with the help of concept and proxy variables available only in the source domain, and unlabeled data from the target. The identification results are constructive, immediately suggesting an algorithm for estimating the optimal predictor in the target. For continuous observations, when this algorithm becomes impractical, we propose a latent variable model specific to the data generation process at hand. We show how the approach degrades as the size of the shift changes, and verify that it outperforms both covariate and label shift adjustment.