 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTabPFN-3: Technical Report
May 13, 2026Tabular data underpins most high-value prediction problems in science and industry, and TabPFN has driven the foundation model revolution for this modality. Designed with feedback from our users, TabPFN-3 builds on this foundation to scale state-of-the-art performance to datasets with 1M training rows and substantially reduce training and inference time. Pretrained exclusively on synthetic data from our prior, TabPFN-3 dramatically pushes the frontier of tabular prediction and brings substantial gains on time series, relational, and tabular-text data. On the standard tabular benchmark TabArena, a forward pass of TabPFN-3 outperforms all other models, including tuned and ensembled baselines, by a significant margin, and pareto-dominates the speed/performance frontier. On more diverse datasets, TabPFN-3 ranks first on datasets with many classes, and beats 8-hour-tuned gradient-boosted-tree baselines on datasets up to 1M training rows and 200 features. TabPFN-3 introduces test-time compute scaling to tabular foundation models. Our API offering TabPFN-3-Plus (Thinking) exploits this to beat all non-TabPFN models by over 200 Elo on TabArena, rising to 420 Elo on the largest data subset, and outperforms AutoGluon 1.5 extreme while being 10x faster, without using LLMs, real data, internet search or any other model besides TabPFN. TabPFN-3 extends the capabilities of our models, enabling SOTA prediction on relational data (new SOTA foundation model on RelBenchV1) and tabular-text data (SOTA on TabSTAR via TabPFN-3-Plus); and improves existing integrations: a specialized checkpoint, TabPFN-TS-3, ranks 2nd on the time-series benchmark fev-bench, and SHAP-value computation is up to 120x faster. TabPFN-3 achieves this performance while being up to 20x faster than TabPFN-2.5. In addition, a reduced KV cache and row-chunking scale to 1M rows on one H100 with fast inference speed.
TabPFN-2.5: Advancing the State of the Art in Tabular Foundation Models
Nov 11, 2025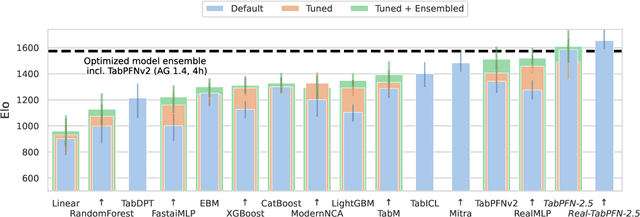
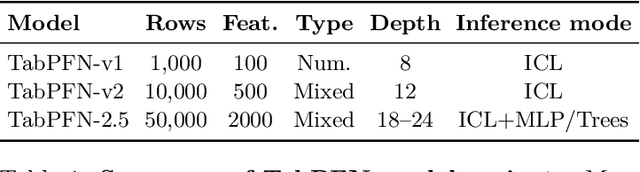
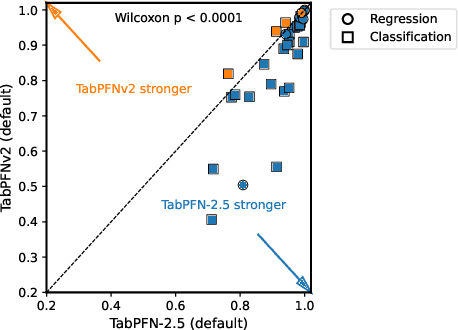
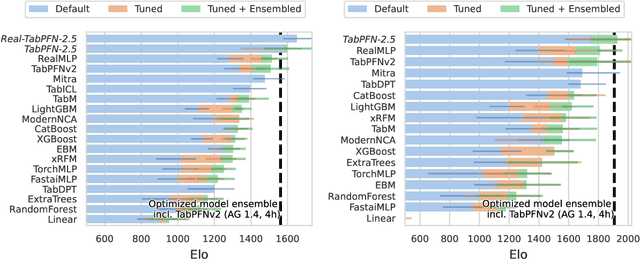
The first tabular foundation model, TabPFN, and its successor TabPFNv2 have impacted tabular AI substantially, with dozens of methods building on it and hundreds of applications across different use cases. This report introduces TabPFN-2.5, the next generation of our tabular foundation model, built for datasets with up to 50,000 data points and 2,000 features, a 20x increase in data cells compared to TabPFNv2. TabPFN-2.5 is now the leading method for the industry standard benchmark TabArena (which contains datasets with up to 100,000 training data points), substantially outperforming tuned tree-based models and matching the accuracy of AutoGluon 1.4, a complex four-hour tuned ensemble that even includes the previous TabPFNv2. Remarkably, default TabPFN-2.5 has a 100% win rate against default XGBoost on small to medium-sized classification datasets (<=10,000 data points, 500 features) and a 87% win rate on larger datasets up to 100K samples and 2K features (85% for regression). For production use cases, we introduce a new distillation engine that converts TabPFN-2.5 into a compact MLP or tree ensemble, preserving most of its accuracy while delivering orders-of-magnitude lower latency and plug-and-play deployment. This new release will immediately strengthen the performance of the many applications and methods already built on the TabPFN ecosystem.
Approximate Top-$k$ for Increased Parallelism
Dec 05, 2024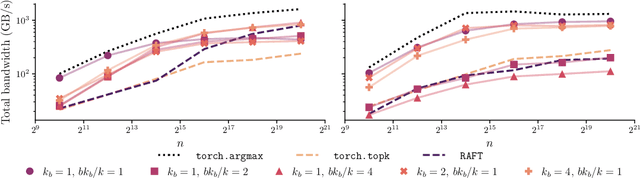
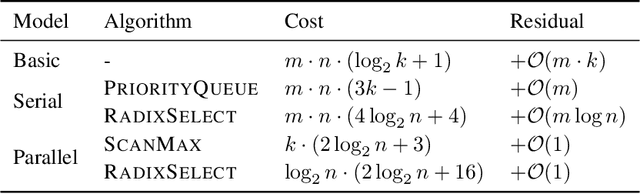
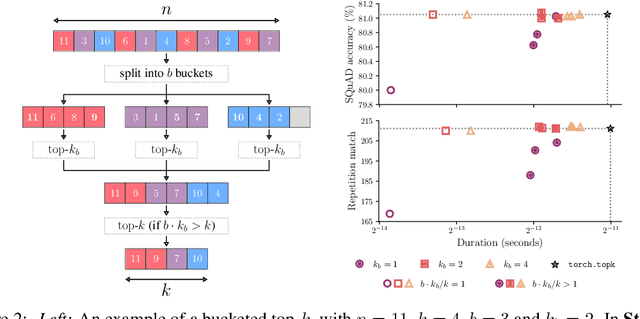
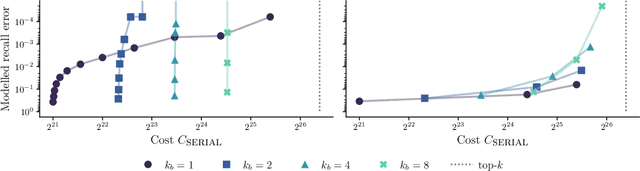
We present an evaluation of bucketed approximate top-$k$ algorithms. Computing top-$k$ exactly suffers from limited parallelism, because the $k$ largest values must be aggregated along the vector, thus is not well suited to computation on highly-parallel machine learning accelerators. By relaxing the requirement that the top-$k$ is exact, bucketed algorithms can dramatically increase the parallelism available by independently computing many smaller top-$k$ operations. We explore the design choices of this class of algorithms using both theoretical analysis and empirical evaluation on downstream tasks. Our motivating examples are sparsity algorithms for language models, which often use top-$k$ to select the most important parameters or activations. We also release a fast bucketed top-$k$ implementation for PyTorch.
Scalable Data Assimilation with Message Passing
Apr 19, 2024



Data assimilation is a core component of numerical weather prediction systems. The large quantity of data processed during assimilation requires the computation to be distributed across increasingly many compute nodes, yet existing approaches suffer from synchronisation overhead in this setting. In this paper, we exploit the formulation of data assimilation as a Bayesian inference problem and apply a message-passing algorithm to solve the spatial inference problem. Since message passing is inherently based on local computations, this approach lends itself to parallel and distributed computation. In combination with a GPU-accelerated implementation, we can scale the algorithm to very large grid sizes while retaining good accuracy and compute and memory requirements.
No Train No Gain: Revisiting Efficient Training Algorithms For Transformer-based Language Models
Jul 26, 2023The computation necessary for training Transformer-based language models has skyrocketed in recent years. This trend has motivated research on efficient training algorithms designed to improve training, validation, and downstream performance faster than standard training. In this work, we revisit three categories of such algorithms: dynamic architectures (layer stacking, layer dropping), batch selection (selective backprop, RHO loss), and efficient optimizers (Lion, Sophia). When pre-training BERT and T5 with a fixed computation budget using such methods, we find that their training, validation, and downstream gains vanish compared to a baseline with a fully-decayed learning rate. We define an evaluation protocol that enables computation to be done on arbitrary machines by mapping all computation time to a reference machine which we call reference system time. We discuss the limitations of our proposed protocol and release our code to encourage rigorous research in efficient training procedures: https://github.com/JeanKaddour/NoTrainNoGain.
Optimally-Weighted Estimators of the Maximum Mean Discrepancy for Likelihood-Free Inference
Jan 30, 2023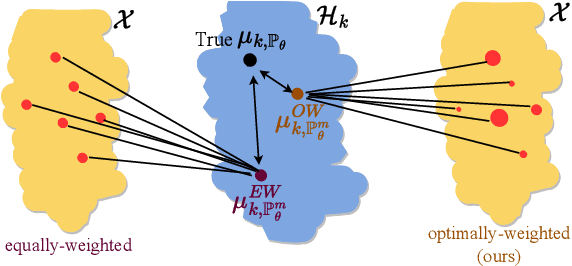

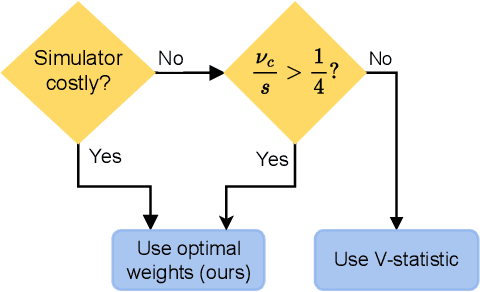
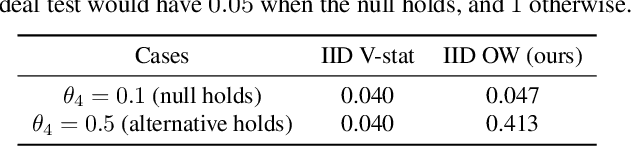
Likelihood-free inference methods typically make use of a distance between simulated and real data. A common example is the maximum mean discrepancy (MMD), which has previously been used for approximate Bayesian computation, minimum distance estimation, generalised Bayesian inference, and within the nonparametric learning framework. The MMD is commonly estimated at a root-$m$ rate, where $m$ is the number of simulated samples. This can lead to significant computational challenges since a large $m$ is required to obtain an accurate estimate, which is crucial for parameter estimation. In this paper, we propose a novel estimator for the MMD with significantly improved sample complexity. The estimator is particularly well suited for computationally expensive smooth simulators with low- to mid-dimensional inputs. This claim is supported through both theoretical results and an extensive simulation study on benchmark simulators.
Towards Healing the Blindness of Score Matching
Sep 15, 2022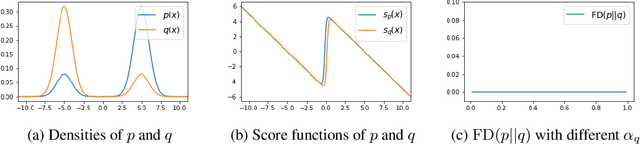
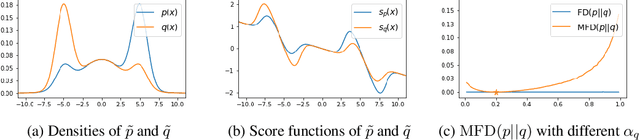
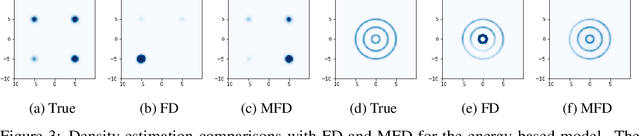
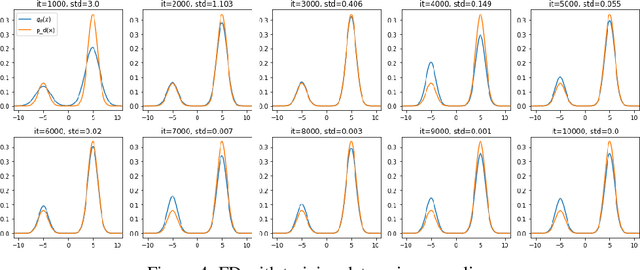
Score-based divergences have been widely used in machine learning and statistics applications. Despite their empirical success, a blindness problem has been observed when using these for multi-modal distributions. In this work, we discuss the blindness problem and propose a new family of divergences that can mitigate the blindness problem. We illustrate our proposed divergence in the context of density estimation and report improved performance compared to traditional approaches.
Composite Goodness-of-fit Tests with Kernels
Nov 19, 2021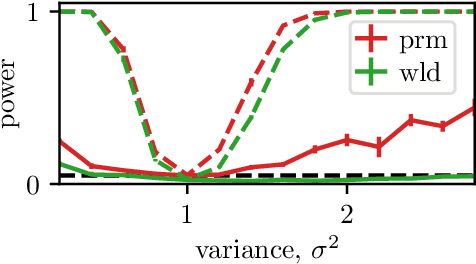

Model misspecification can create significant challenges for the implementation of probabilistic models, and this has led to development of a range of inference methods which directly account for this issue. However, whether these more involved methods are required will depend on whether the model is really misspecified, and there is a lack of generally applicable methods to answer this question. One set of tools which can help are goodness-of-fit tests, where we test whether a dataset could have been generated by a fixed distribution. Kernel-based tests have been developed to for this problem, and these are popular due to their flexibility, strong theoretical guarantees and ease of implementation in a wide range of scenarios. In this paper, we extend this line of work to the more challenging composite goodness-of-fit problem, where we are instead interested in whether the data comes from any distribution in some parametric family. This is equivalent to testing whether a parametric model is well-specified for the data.
Generating Interpretable Counterfactual Explanations By Implicit Minimisation of Epistemic and Aleatoric Uncertainties
Mar 16, 2021
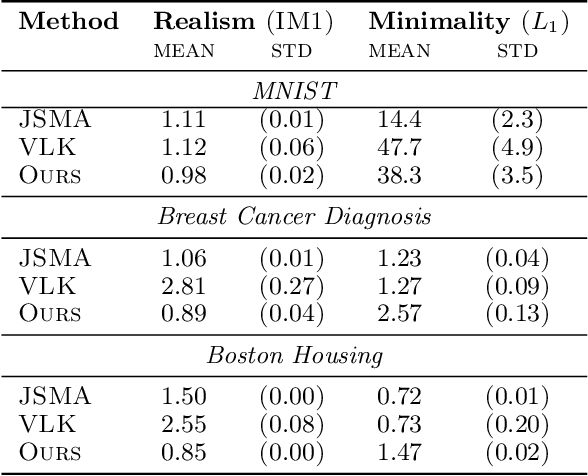


Counterfactual explanations (CEs) are a practical tool for demonstrating why machine learning classifiers make particular decisions. For CEs to be useful, it is important that they are easy for users to interpret. Existing methods for generating interpretable CEs rely on auxiliary generative models, which may not be suitable for complex datasets, and incur engineering overhead. We introduce a simple and fast method for generating interpretable CEs in a white-box setting without an auxiliary model, by using the predictive uncertainty of the classifier. Our experiments show that our proposed algorithm generates more interpretable CEs, according to IM1 scores, than existing methods. Additionally, our approach allows us to estimate the uncertainty of a CE, which may be important in safety-critical applications, such as those in the medical domain.
* 21 pages, 13 Figures
Improving Deterministic Uncertainty Estimation in Deep Learning for Classification and Regression
Feb 22, 2021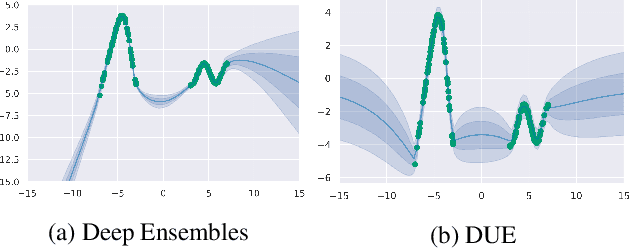

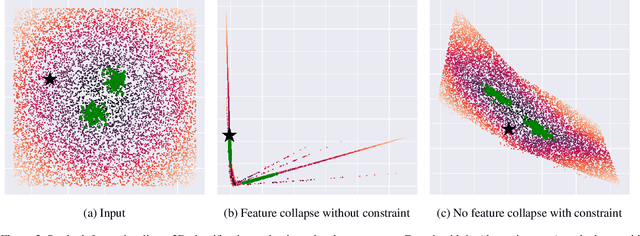
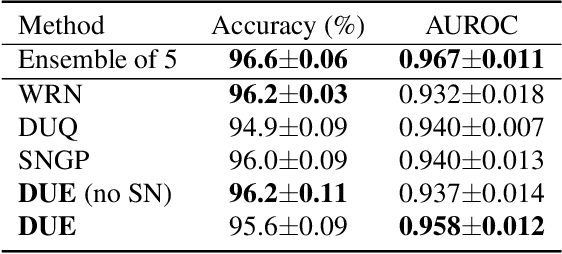
We propose a new model that estimates uncertainty in a single forward pass and works on both classification and regression problems. Our approach combines a bi-Lipschitz feature extractor with an inducing point approximate Gaussian process, offering robust and principled uncertainty estimation. This can be seen as a refinement of Deep Kernel Learning (DKL), with our changes allowing DKL to match softmax neural networks accuracy. Our method overcomes the limitations of previous work addressing deterministic uncertainty quantification, such as the dependence of uncertainty on ad hoc hyper-parameters. Our method matches SotA accuracy, 96.2% on CIFAR-10, while maintaining the speed of softmax models, and provides uncertainty estimates that outperform previous single forward pass uncertainty models. Finally, we demonstrate our method on a recently introduced benchmark for uncertainty in regression: treatment deferral in causal models for personalized medicine.