 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOptimal Formats for Weight Quantisation
May 19, 2025Weight quantisation is an essential technique for enabling efficient training and deployment of modern deep learning models. However, the recipe book of quantisation formats is large and the formats are often chosen empirically. In this paper, we propose a framework for systematic design and analysis of quantisation formats. By connecting the question of format design with the classical quantisation theory, we show that the strong practical performance of popular formats comes from their ability to represent values using variable-length codes. Framing the optimisation problem as minimising the KL divergence between the original and quantised model outputs, the objective is aligned with minimising the squared quantisation error of the model parameters. We therefore develop and evaluate squared-error-optimal formats for known distributions, observing significant improvement of variable-length codes over fixed-length codes. Uniform quantisation followed by lossless compression with a variable-length code is shown to be optimal. However, we find that commonly used block formats and sparse outlier formats also outperform fixed-length codes, implying they also exploit variable-length encoding. Finally, by using the relationship between the Fisher information and KL divergence, we derive the optimal allocation of bit-widths to individual parameter tensors across the model's layers, saving up to 0.25 bits per parameter when tested with direct-cast quantisation of language models.
Approximate Top-$k$ for Increased Parallelism
Dec 05, 2024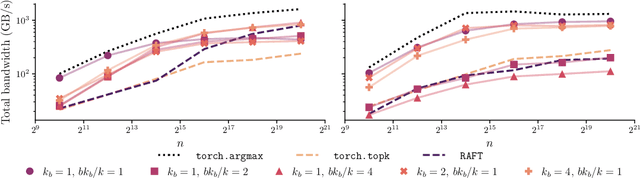
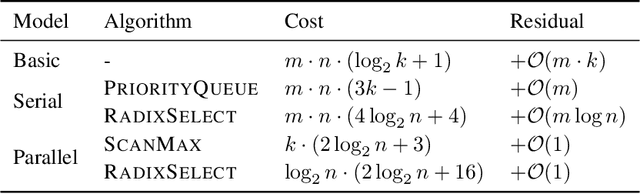
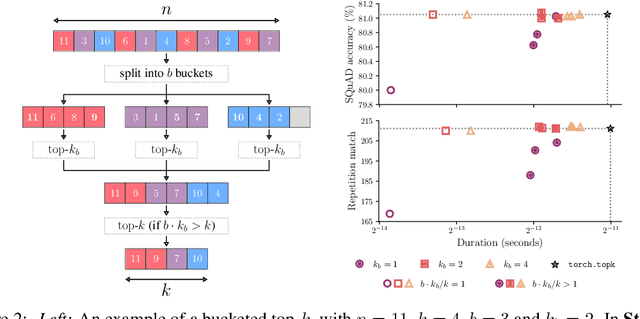
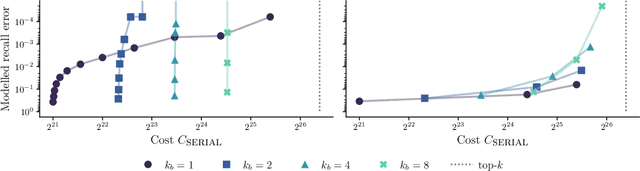
We present an evaluation of bucketed approximate top-$k$ algorithms. Computing top-$k$ exactly suffers from limited parallelism, because the $k$ largest values must be aggregated along the vector, thus is not well suited to computation on highly-parallel machine learning accelerators. By relaxing the requirement that the top-$k$ is exact, bucketed algorithms can dramatically increase the parallelism available by independently computing many smaller top-$k$ operations. We explore the design choices of this class of algorithms using both theoretical analysis and empirical evaluation on downstream tasks. Our motivating examples are sparsity algorithms for language models, which often use top-$k$ to select the most important parameters or activations. We also release a fast bucketed top-$k$ implementation for PyTorch.
SparQ Attention: Bandwidth-Efficient LLM Inference
Dec 08, 2023Generative large language models (LLMs) have opened up numerous novel possibilities, but due to their significant computational requirements their ubiquitous use remains challenging. Some of the most useful applications require processing large numbers of samples at a time and using long contexts, both significantly increasing the memory communication load of the models. We introduce SparQ Attention, a technique for increasing the inference throughput of LLMs by reducing the memory bandwidth requirements within the attention blocks through selective fetching of the cached history. Our proposed technique can be applied directly to off-the-shelf LLMs during inference, without requiring any modification to the pre-training setup or additional fine-tuning. We show how SparQ Attention can decrease the attention memory bandwidth requirements up to eight times without any loss in accuracy by evaluating Llama 2 and Pythia models on a wide range of downstream tasks.
Reliability of Event Timing in Silicon Neurons
Dec 28, 2021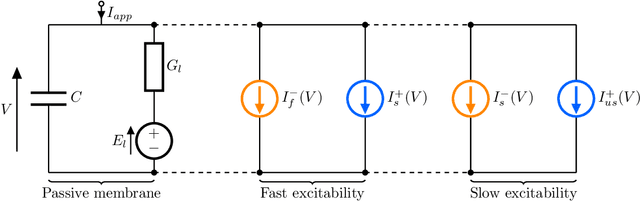
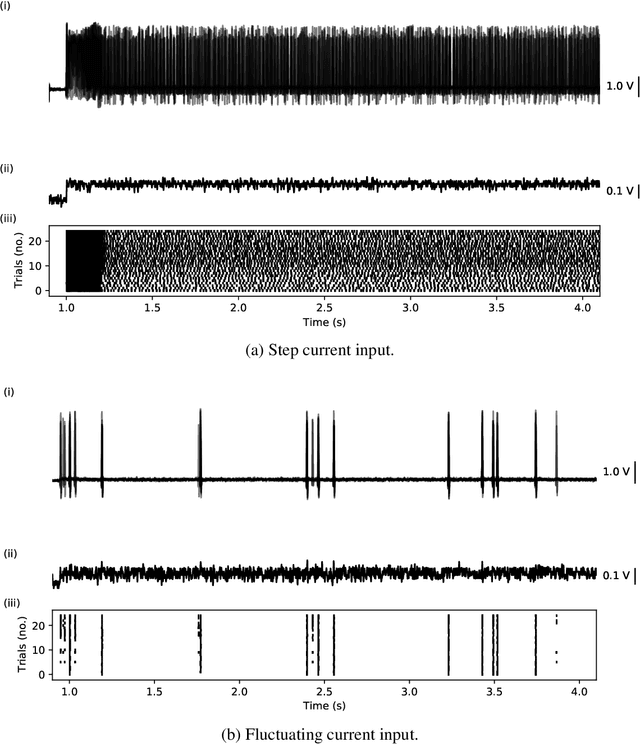
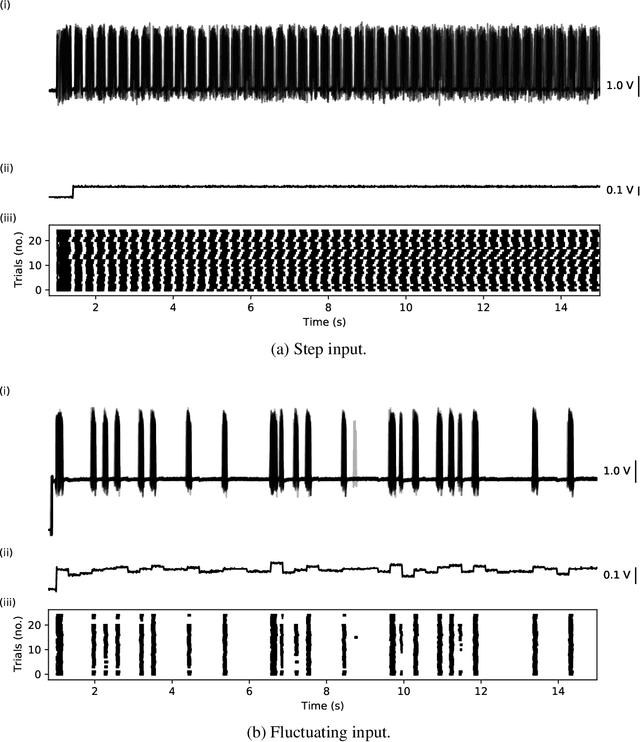
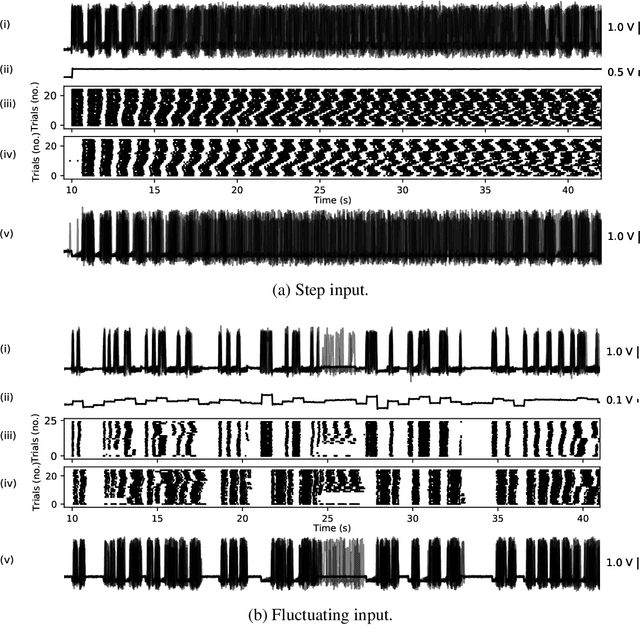
Analog, low-voltage electronics show great promise in producing silicon neurons (SiNs) with unprecedented levels of energy efficiency. Yet, their inherently high susceptibility to process, voltage and temperature (PVT) variations, and noise has long been recognised as a major bottleneck in developing effective neuromorphic solutions. Inspired by spike transmission studies in biophysical, neocortical neurons, we demonstrate that the inherent noise and variability can coexist with reliable spike transmission in analog SiNs, similarly to biological neurons. We illustrate this property on a recent neuromorphic model of a bursting neuron by showcasing three different relevant types of reliable event transmission: single spike transmission, burst transmission, and the on-off control of a half-centre oscillator (HCO) network.