 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeApproximate Top-$k$ for Increased Parallelism
Dec 05, 2024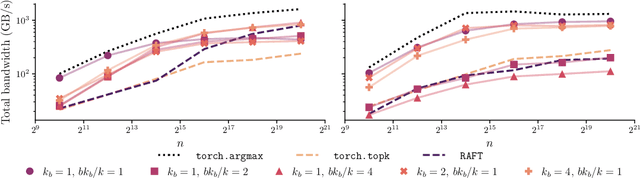
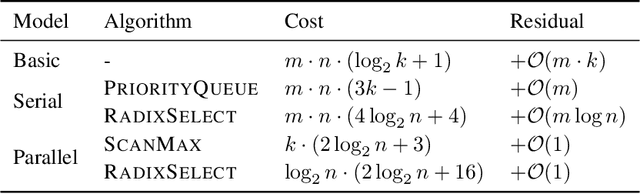
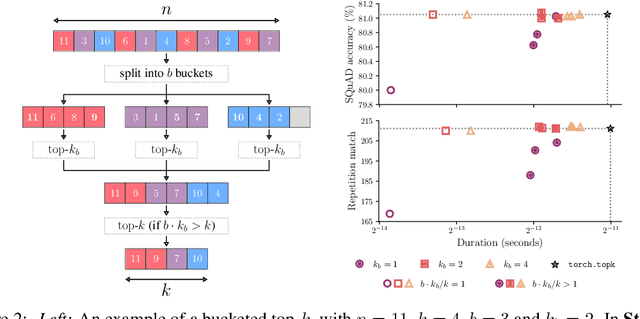
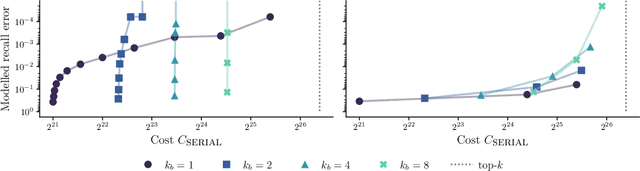
We present an evaluation of bucketed approximate top-$k$ algorithms. Computing top-$k$ exactly suffers from limited parallelism, because the $k$ largest values must be aggregated along the vector, thus is not well suited to computation on highly-parallel machine learning accelerators. By relaxing the requirement that the top-$k$ is exact, bucketed algorithms can dramatically increase the parallelism available by independently computing many smaller top-$k$ operations. We explore the design choices of this class of algorithms using both theoretical analysis and empirical evaluation on downstream tasks. Our motivating examples are sparsity algorithms for language models, which often use top-$k$ to select the most important parameters or activations. We also release a fast bucketed top-$k$ implementation for PyTorch.
SparQ Attention: Bandwidth-Efficient LLM Inference
Dec 08, 2023Generative large language models (LLMs) have opened up numerous novel possibilities, but due to their significant computational requirements their ubiquitous use remains challenging. Some of the most useful applications require processing large numbers of samples at a time and using long contexts, both significantly increasing the memory communication load of the models. We introduce SparQ Attention, a technique for increasing the inference throughput of LLMs by reducing the memory bandwidth requirements within the attention blocks through selective fetching of the cached history. Our proposed technique can be applied directly to off-the-shelf LLMs during inference, without requiring any modification to the pre-training setup or additional fine-tuning. We show how SparQ Attention can decrease the attention memory bandwidth requirements up to eight times without any loss in accuracy by evaluating Llama 2 and Pythia models on a wide range of downstream tasks.