 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edgeu-$μ$P: The Unit-Scaled Maximal Update Parametrization
Jul 24, 2024The Maximal Update Parametrization ($\mu$P) aims to make the optimal hyperparameters (HPs) of a model independent of its size, allowing them to be swept using a cheap proxy model rather than the full-size target model. We present a new scheme, u-$\mu$P, which improves upon $\mu$P by combining it with Unit Scaling, a method for designing models that makes them easy to train in low-precision. The two techniques have a natural affinity: $\mu$P ensures that the scale of activations is independent of model size, and Unit Scaling ensures that activations, weights and gradients begin training with a scale of one. This synthesis opens the door to a simpler scheme, whose default values are near-optimal. This in turn facilitates a more efficient sweeping strategy, with u-$\mu$P models reaching a lower loss than comparable $\mu$P models and working out-of-the-box in FP8.
SparQ Attention: Bandwidth-Efficient LLM Inference
Dec 08, 2023Generative large language models (LLMs) have opened up numerous novel possibilities, but due to their significant computational requirements their ubiquitous use remains challenging. Some of the most useful applications require processing large numbers of samples at a time and using long contexts, both significantly increasing the memory communication load of the models. We introduce SparQ Attention, a technique for increasing the inference throughput of LLMs by reducing the memory bandwidth requirements within the attention blocks through selective fetching of the cached history. Our proposed technique can be applied directly to off-the-shelf LLMs during inference, without requiring any modification to the pre-training setup or additional fine-tuning. We show how SparQ Attention can decrease the attention memory bandwidth requirements up to eight times without any loss in accuracy by evaluating Llama 2 and Pythia models on a wide range of downstream tasks.
Training and inference of large language models using 8-bit floating point
Sep 29, 2023



FP8 formats are gaining popularity to boost the computational efficiency for training and inference of large deep learning models. Their main challenge is that a careful choice of scaling is needed to prevent degradation due to the reduced dynamic range compared to higher-precision formats. Although there exists ample literature about selecting such scalings for INT formats, this critical aspect has yet to be addressed for FP8. This paper presents a methodology to select the scalings for FP8 linear layers, based on dynamically updating per-tensor scales for the weights, gradients and activations. We apply this methodology to train and validate large language models of the type of GPT and Llama 2 using FP8, for model sizes ranging from 111M to 70B. To facilitate the understanding of the FP8 dynamics, our results are accompanied by plots of the per-tensor scale distribution for weights, activations and gradients during both training and inference.
Unit Scaling: Out-of-the-Box Low-Precision Training
Mar 20, 2023We present unit scaling, a paradigm for designing deep learning models that simplifies the use of low-precision number formats. Training in FP16 or the recently proposed FP8 formats offers substantial efficiency gains, but can lack sufficient range for out-of-the-box training. Unit scaling addresses this by introducing a principled approach to model numerics: seeking unit variance of all weights, activations and gradients at initialisation. Unlike alternative methods, this approach neither requires multiple training runs to find a suitable scale nor has significant computational overhead. We demonstrate the efficacy of unit scaling across a range of models and optimisers. We further show that existing models can be adapted to be unit-scaled, training BERT-Large in FP16 and then FP8 with no degradation in accuracy.
Snowflake: Scaling GNNs to High-Dimensional Continuous Control via Parameter Freezing
Mar 01, 2021
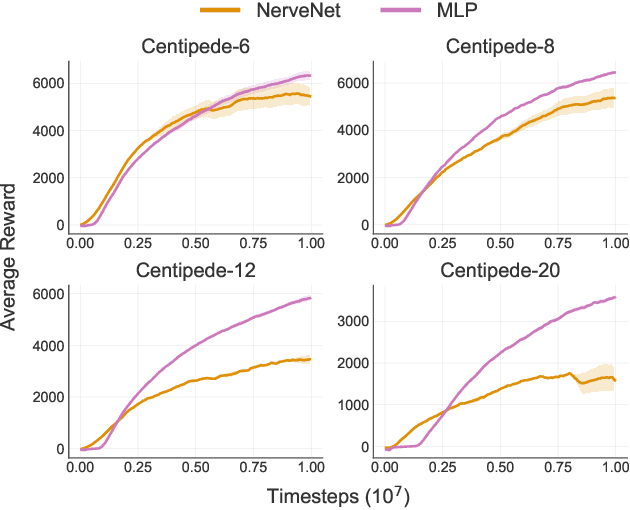
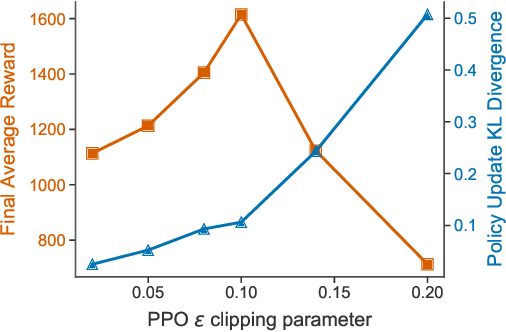
Recent research has shown that Graph Neural Networks (GNNs) can learn policies for locomotion control that are as effective as a typical multi-layer perceptron (MLP), with superior transfer and multi-task performance (Wang et al., 2018; Huang et al., 2020). Results have so far been limited to training on small agents, with the performance of GNNs deteriorating rapidly as the number of sensors and actuators grows. A key motivation for the use of GNNs in the supervised learning setting is their applicability to large graphs, but this benefit has not yet been realised for locomotion control. We identify the weakness with a common GNN architecture that causes this poor scaling: overfitting in the MLPs within the network that encode, decode, and propagate messages. To combat this, we introduce Snowflake, a GNN training method for high-dimensional continuous control that freezes parameters in parts of the network that suffer from overfitting. Snowflake significantly boosts the performance of GNNs for locomotion control on large agents, now matching the performance of MLPs, and with superior transfer properties.
The Winnability of Klondike and Many Other Single-Player Card Games
Jun 28, 2019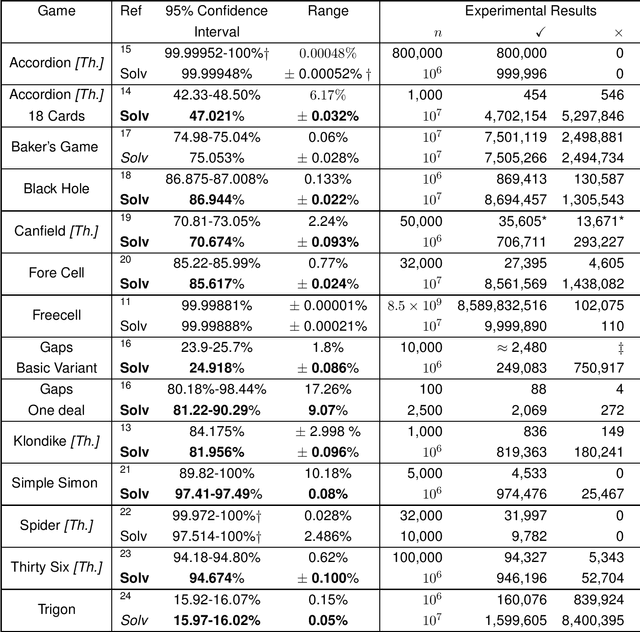
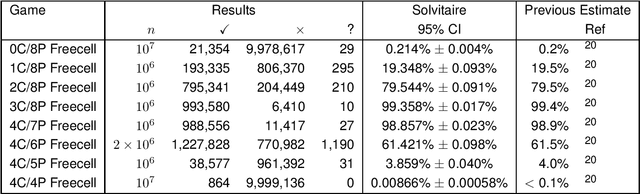
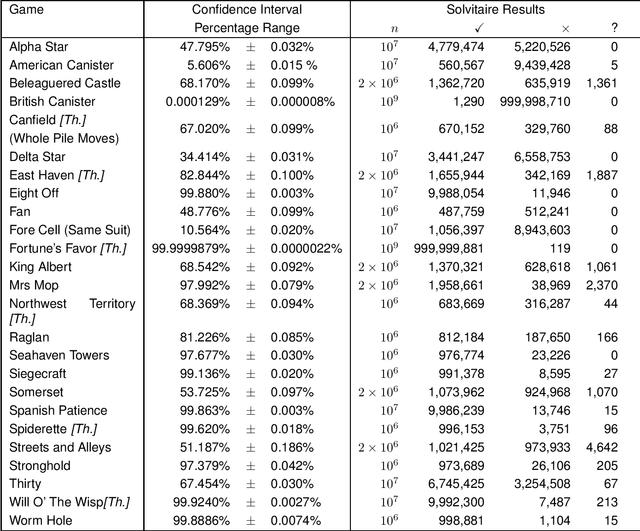
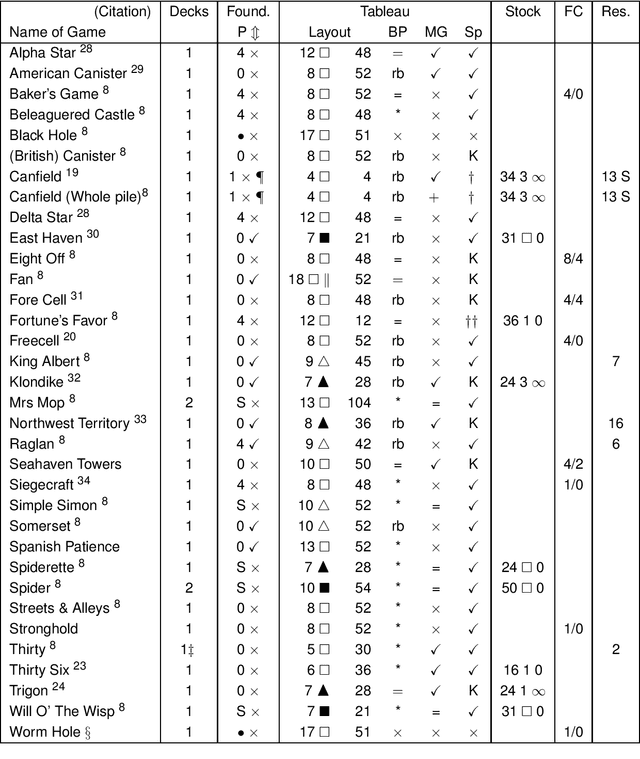
The most famous single-player card game is 'Klondike', but our ignorance of its winnability percentage has been called "one of the embarrassments of applied mathematics". Klondike is just one of many single-player card games, generically called 'patience' or 'solitaire' games, for which players have long wanted to know how likely a particular game is to be winnable for a random deal. A number of different games have been studied empirically in the academic literature and by non-academic enthusiasts. Here we show that a single general purpose Artificial Intelligence program, called "Solvitaire", can be used to determine the winnability percentage of approximately 30 different single-player card games with a 95\% confidence interval of +/- 0.1\% or better. For example, we report the winnability of Klondike as 81.956% +/- 0.096% (in the 'thoughtful' variant where the player knows the location of all cards), a 30-fold reduction in confidence interval over the best previous result. Almost all our results are either entirely new or represent significant improvements on previous knowledge.