 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTraining and inference of large language models using 8-bit floating point
Sep 29, 2023



FP8 formats are gaining popularity to boost the computational efficiency for training and inference of large deep learning models. Their main challenge is that a careful choice of scaling is needed to prevent degradation due to the reduced dynamic range compared to higher-precision formats. Although there exists ample literature about selecting such scalings for INT formats, this critical aspect has yet to be addressed for FP8. This paper presents a methodology to select the scalings for FP8 linear layers, based on dynamically updating per-tensor scales for the weights, gradients and activations. We apply this methodology to train and validate large language models of the type of GPT and Llama 2 using FP8, for model sizes ranging from 111M to 70B. To facilitate the understanding of the FP8 dynamics, our results are accompanied by plots of the per-tensor scale distribution for weights, activations and gradients during both training and inference.
Enhancement of damaged-image prediction through Cahn-Hilliard Image Inpainting
Jul 21, 2020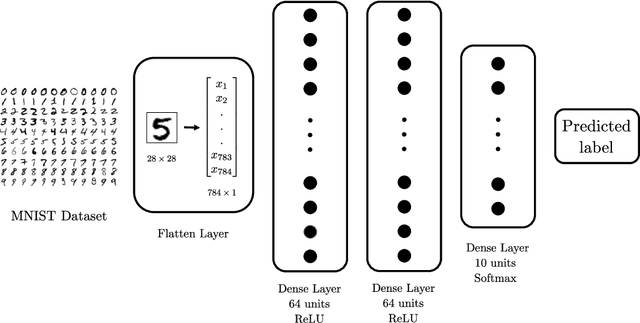
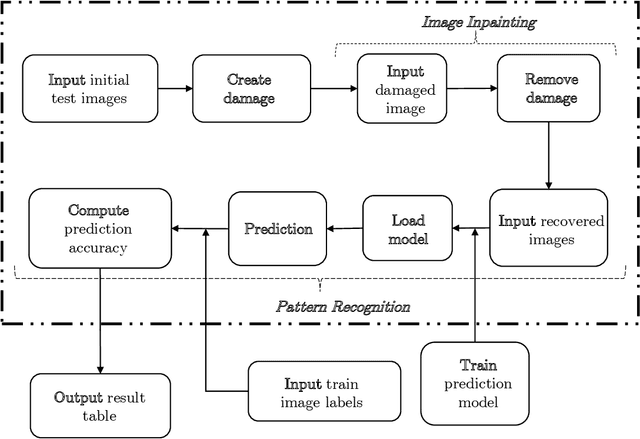

We assess the benefit of including an image inpainting filter before passing damaged images into a classification neural network. For this we employ a modified Cahn-Hilliard equation as an image inpainting filter, which is solved via a finite volume scheme with reduced computational cost and adequate properties for energy stability and boundedness. The benchmark dataset employed here is the MNIST dataset, which consists in binary images of digits. We train a neural network based of dense layers with the training set of MNIST, and subsequently we contaminate the test set with damage of different types and intensities. We then compare the prediction accuracy of the neural network with and without applying the Cahn-Hilliard filter to the damaged images test. Our results quantify the significant improvement of damaged-image prediction due to applying the Cahn-Hilliard filter, which for specific damages can increase up to 50% and is in general advantageous for low to moderate damage.