 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTraining and inference of large language models using 8-bit floating point
Sep 29, 2023



FP8 formats are gaining popularity to boost the computational efficiency for training and inference of large deep learning models. Their main challenge is that a careful choice of scaling is needed to prevent degradation due to the reduced dynamic range compared to higher-precision formats. Although there exists ample literature about selecting such scalings for INT formats, this critical aspect has yet to be addressed for FP8. This paper presents a methodology to select the scalings for FP8 linear layers, based on dynamically updating per-tensor scales for the weights, gradients and activations. We apply this methodology to train and validate large language models of the type of GPT and Llama 2 using FP8, for model sizes ranging from 111M to 70B. To facilitate the understanding of the FP8 dynamics, our results are accompanied by plots of the per-tensor scale distribution for weights, activations and gradients during both training and inference.
Biomedical Concept Relatedness -- A large EHR-based benchmark
Oct 30, 2020
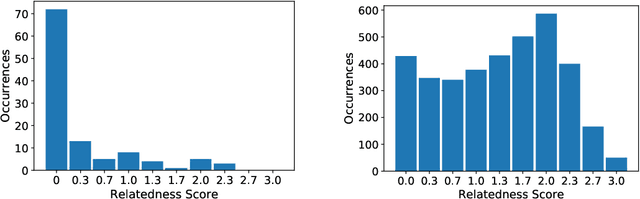
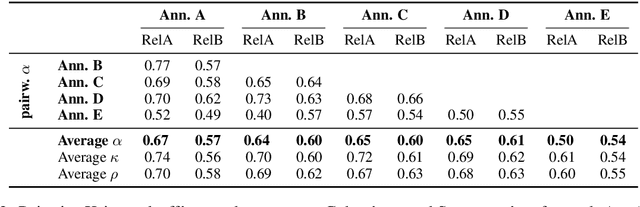
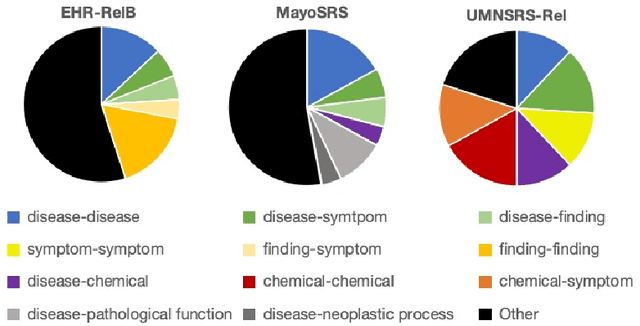
A promising application of AI to healthcare is the retrieval of information from electronic health records (EHRs), e.g. to aid clinicians in finding relevant information for a consultation or to recruit suitable patients for a study. This requires search capabilities far beyond simple string matching, including the retrieval of concepts (diagnoses, symptoms, medications, etc.) related to the one in question. The suitability of AI methods for such applications is tested by predicting the relatedness of concepts with known relatedness scores. However, all existing biomedical concept relatedness datasets are notoriously small and consist of hand-picked concept pairs. We open-source a novel concept relatedness benchmark overcoming these issues: it is six times larger than existing datasets and concept pairs are chosen based on co-occurrence in EHRs, ensuring their relevance for the application of interest. We present an in-depth analysis of our new dataset and compare it to existing ones, highlighting that it is not only larger but also complements existing datasets in terms of the types of concepts included. Initial experiments with state-of-the-art embedding methods show that our dataset is a challenging new benchmark for testing concept relatedness models.
Real-Time Community Detection in Large Social Networks on a Laptop
Sep 04, 2016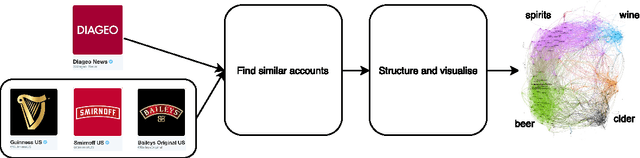


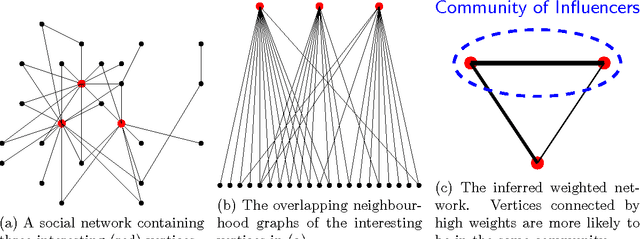
For a broad range of research, governmental and commercial applications it is important to understand the allegiances, communities and structure of key players in society. One promising direction towards extracting this information is to exploit the rich relational data in digital social networks (the social graph). As social media data sets are very large, most approaches make use of distributed computing systems for this purpose. Distributing graph processing requires solving many difficult engineering problems, which has lead some researchers to look at single-machine solutions that are faster and easier to maintain. In this article, we present a single-machine real-time system for large-scale graph processing that allows analysts to interactively explore graph structures. The key idea is that the aggregate actions of large numbers of users can be compressed into a data structure that encapsulates user similarities while being robust to noise and queryable in real-time. We achieve single machine real-time performance by compressing the neighbourhood of each vertex using minhash signatures and facilitate rapid queries through Locality Sensitive Hashing. These techniques reduce query times from hours using industrial desktop machines operating on the full graph to milliseconds on standard laptops. Our method allows exploration of strongly associated regions (i.e. communities) of large graphs in real-time on a laptop. It has been deployed in software that is actively used by social network analysts and offers another channel for media owners to monetise their data, helping them to continue to provide free services that are valued by billions of people globally.