 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Right Model for the Job: An Evaluation of Legal Multi-Label Classification Baselines
Jan 22, 2024Multi-Label Classification (MLC) is a common task in the legal domain, where more than one label may be assigned to a legal document. A wide range of methods can be applied, ranging from traditional ML approaches to the latest Transformer-based architectures. In this work, we perform an evaluation of different MLC methods using two public legal datasets, POSTURE50K and EURLEX57K. By varying the amount of training data and the number of labels, we explore the comparative advantage offered by different approaches in relation to the dataset properties. Our findings highlight DistilRoBERTa and LegalBERT as performing consistently well in legal MLC with reasonable computational demands. T5 also demonstrates comparable performance while offering advantages as a generative model in the presence of changing label sets. Finally, we show that the CrossEncoder exhibits potential for notable macro-F1 score improvements, albeit with increased computational costs.
A Framework for Monitoring and Retraining Language Models in Real-World Applications
Nov 17, 2023

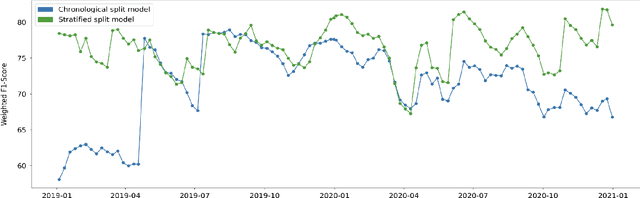
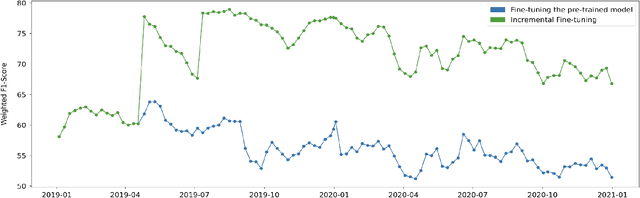
In the Machine Learning (ML) model development lifecycle, training candidate models using an offline holdout dataset and identifying the best model for the given task is only the first step. After the deployment of the selected model, continuous model monitoring and model retraining is required in many real-world applications. There are multiple reasons for retraining, including data or concept drift, which may be reflected on the model performance as monitored by an appropriate metric. Another motivation for retraining is the acquisition of increasing amounts of data over time, which may be used to retrain and improve the model performance even in the absence of drifts. We examine the impact of various retraining decision points on crucial factors, such as model performance and resource utilization, in the context of Multilabel Classification models. We explain our key decision points and propose a reference framework for designing an effective model retraining strategy.
Biomedical Concept Relatedness -- A large EHR-based benchmark
Oct 30, 2020
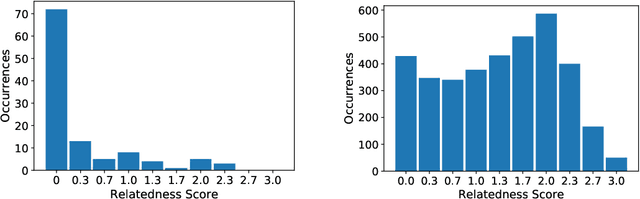
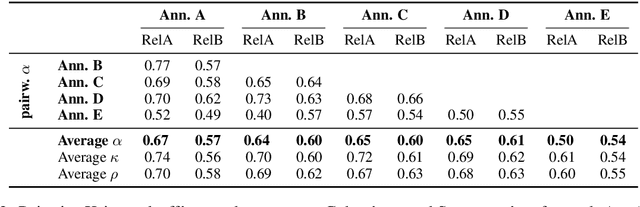
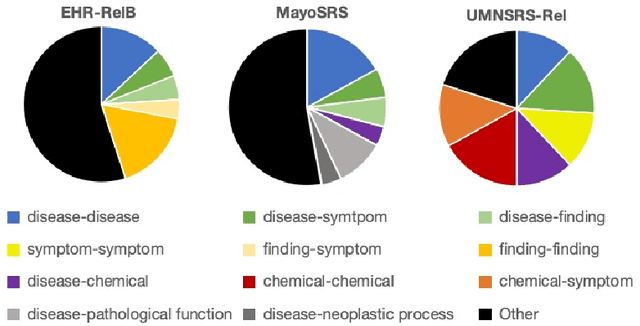
A promising application of AI to healthcare is the retrieval of information from electronic health records (EHRs), e.g. to aid clinicians in finding relevant information for a consultation or to recruit suitable patients for a study. This requires search capabilities far beyond simple string matching, including the retrieval of concepts (diagnoses, symptoms, medications, etc.) related to the one in question. The suitability of AI methods for such applications is tested by predicting the relatedness of concepts with known relatedness scores. However, all existing biomedical concept relatedness datasets are notoriously small and consist of hand-picked concept pairs. We open-source a novel concept relatedness benchmark overcoming these issues: it is six times larger than existing datasets and concept pairs are chosen based on co-occurrence in EHRs, ensuring their relevance for the application of interest. We present an in-depth analysis of our new dataset and compare it to existing ones, highlighting that it is not only larger but also complements existing datasets in terms of the types of concepts included. Initial experiments with state-of-the-art embedding methods show that our dataset is a challenging new benchmark for testing concept relatedness models.
Can Embeddings Adequately Represent Medical Terminology? New Large-Scale Medical Term Similarity Datasets Have the Answer!
Mar 24, 2020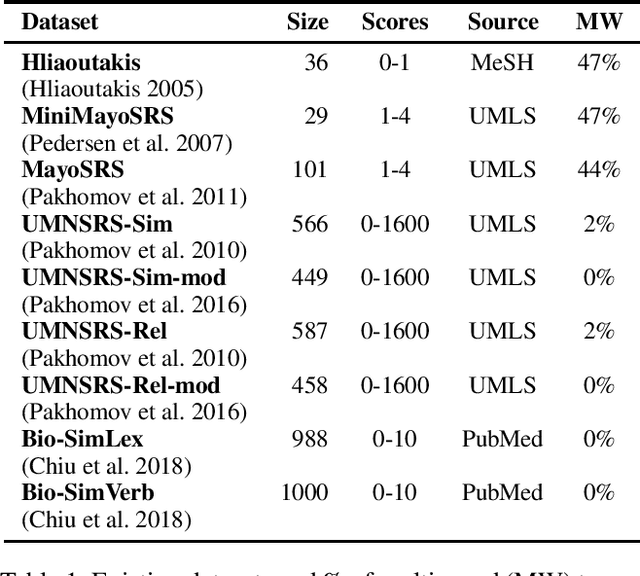
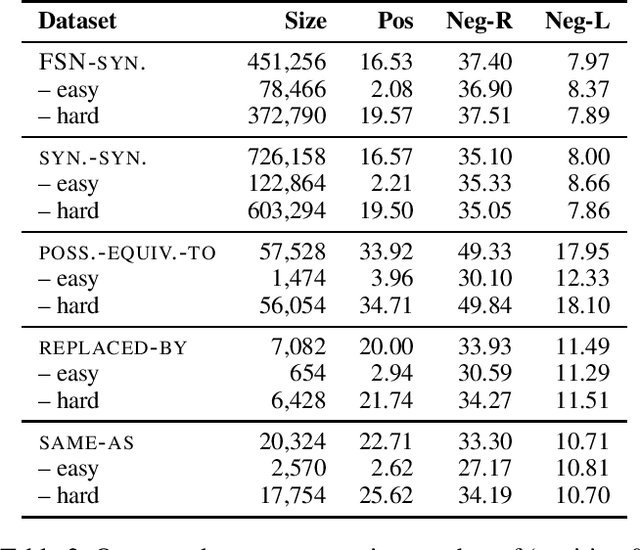
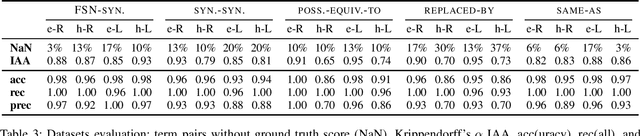
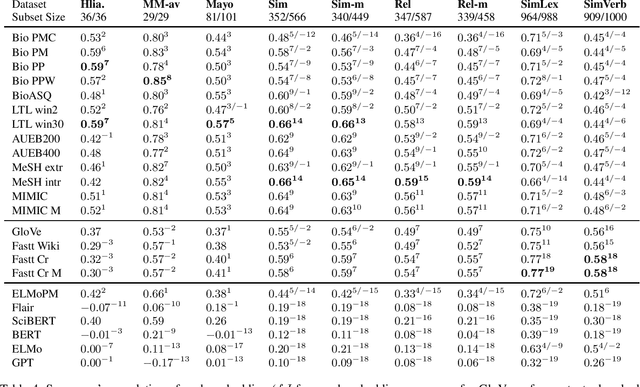
A large number of embeddings trained on medical data have emerged, but it remains unclear how well they represent medical terminology, in particular whether the close relationship of semantically similar medical terms is encoded in these embeddings. To date, only small datasets for testing medical term similarity are available, not allowing to draw conclusions about the generalisability of embeddings to the enormous amount of medical terms used by doctors. We present multiple automatically created large-scale medical term similarity datasets and confirm their high quality in an annotation study with doctors. We evaluate state-of-the-art word and contextual embeddings on our new datasets, comparing multiple vector similarity metrics and word vector aggregation techniques. Our results show that current embeddings are limited in their ability to adequately encode medical terms. The novel datasets thus form a challenging new benchmark for the development of medical embeddings able to accurately represent the whole medical terminology.
A Richly Annotated Corpus for Different Tasks in Automated Fact-Checking
Oct 29, 2019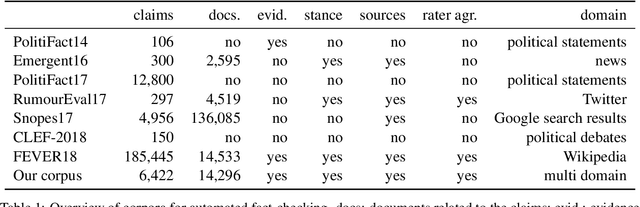
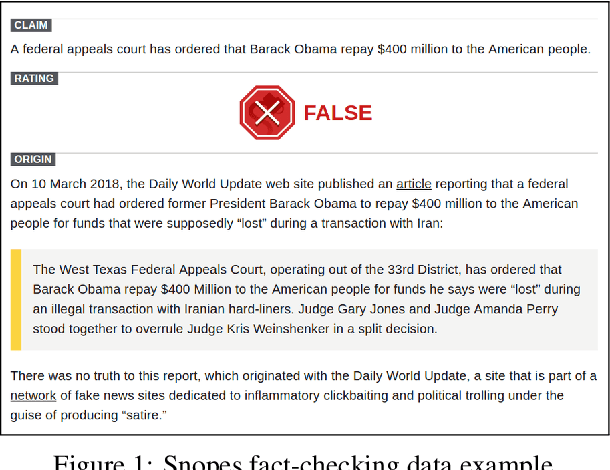
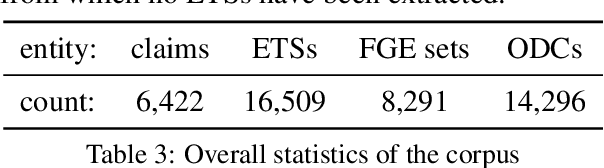
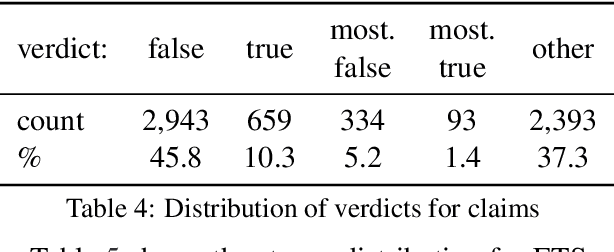
Automated fact-checking based on machine learning is a promising approach to identify false information distributed on the web. In order to achieve satisfactory performance, machine learning methods require a large corpus with reliable annotations for the different tasks in the fact-checking process. Having analyzed existing fact-checking corpora, we found that none of them meets these criteria in full. They are either too small in size, do not provide detailed annotations, or are limited to a single domain. Motivated by this gap, we present a new substantially sized mixed-domain corpus with annotations of good quality for the core fact-checking tasks: document retrieval, evidence extraction, stance detection, and claim validation. To aid future corpus construction, we describe our methodology for corpus creation and annotation, and demonstrate that it results in substantial inter-annotator agreement. As baselines for future research, we perform experiments on our corpus with a number of model architectures that reach high performance in similar problem settings. Finally, to support the development of future models, we provide a detailed error analysis for each of the tasks. Our results show that the realistic, multi-domain setting defined by our data poses new challenges for the existing models, providing opportunities for considerable improvement by future systems.
FAMULUS: Interactive Annotation and Feedback Generation for Teaching Diagnostic Reasoning
Aug 29, 2019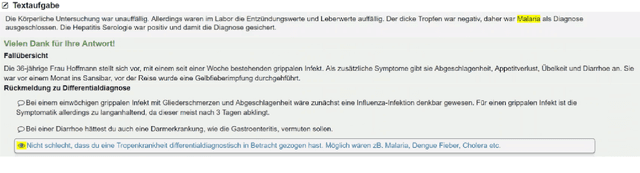

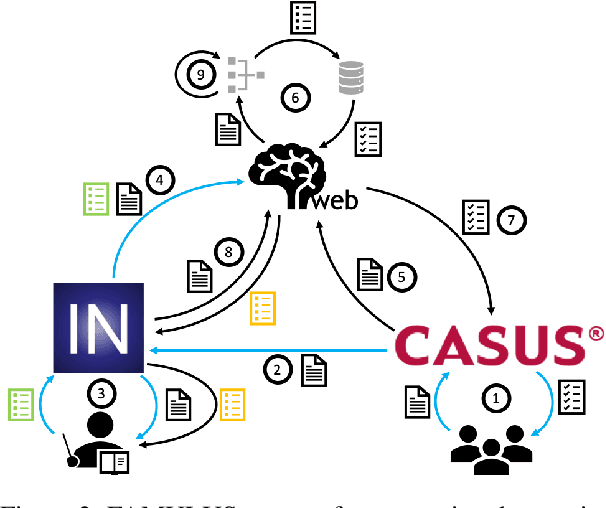
Our proposed system FAMULUS helps students learn to diagnose based on automatic feedback in virtual patient simulations, and it supports instructors in labeling training data. Diagnosing is an exceptionally difficult skill to obtain but vital for many different professions (e.g., medical doctors, teachers). Previous case simulation systems are limited to multiple-choice questions and thus cannot give constructive individualized feedback on a student's diagnostic reasoning process. Given initially only limited data, we leverage a (replaceable) NLP model to both support experts in their further data annotation with automatic suggestions, and we provide automatic feedback for students. We argue that because the central model consistently improves, our interactive approach encourages both students and instructors to recurrently use the tool, and thus accelerate the speed of data creation and annotation. We show results from two user studies on diagnostic reasoning in medicine and teacher education and outline how our system can be extended to further use cases.
Analysis of Automatic Annotation Suggestions for Hard Discourse-Level Tasks in Expert Domains
Jun 06, 2019
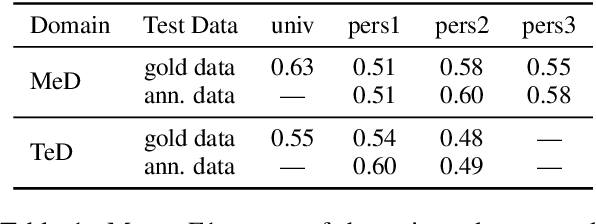
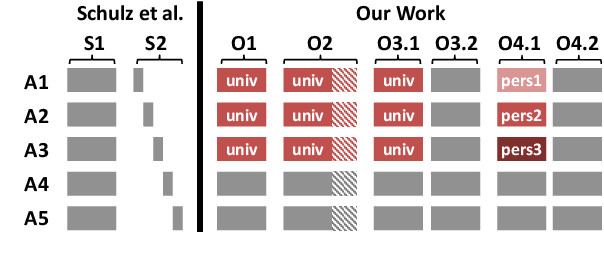
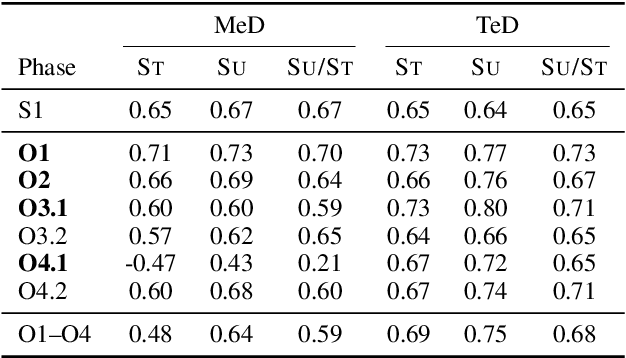
Many complex discourse-level tasks can aid domain experts in their work but require costly expert annotations for data creation. To speed up and ease annotations, we investigate the viability of automatically generated annotation suggestions for such tasks. As an example, we choose a task that is particularly hard for both humans and machines: the segmentation and classification of epistemic activities in diagnostic reasoning texts. We create and publish a new dataset covering two domains and carefully analyse the suggested annotations. We find that suggestions have positive effects on annotation speed and performance, while not introducing noteworthy biases. Envisioning suggestion models that improve with newly annotated texts, we contrast methods for continuous model adjustment and suggest the most effective setup for suggestions in future expert tasks.
Text Processing Like Humans Do: Visually Attacking and Shielding NLP Systems
Mar 27, 2019
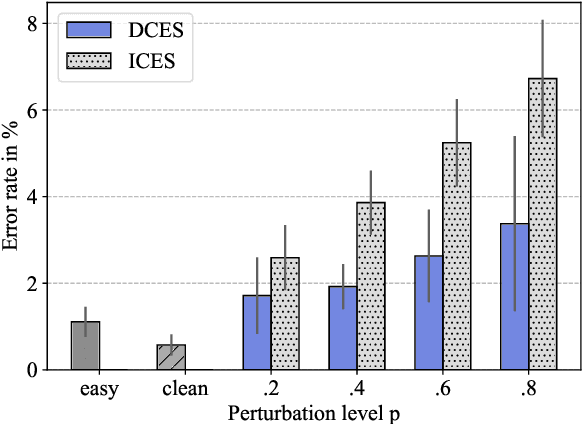

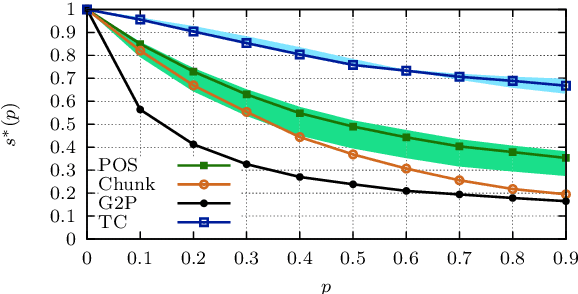
Visual modifications to text are often used to obfuscate offensive comments in social media (e.g., "!d10t") or as a writing style ("1337" in "leet speak"), among other scenarios. We consider this as a new type of adversarial attack in NLP, a setting to which humans are very robust, as our experiments with both simple and more difficult visual input perturbations demonstrate. We then investigate the impact of visual adversarial attacks on current NLP systems on character-, word-, and sentence-level tasks, showing that both neural and non-neural models are, in contrast to humans, extremely sensitive to such attacks, suffering performance decreases of up to 82\%. We then explore three shielding methods---visual character embeddings, adversarial training, and rule-based recovery---which substantially improve the robustness of the models. However, the shielding methods still fall behind performances achieved in non-attack scenarios, which demonstrates the difficulty of dealing with visual attacks.
Challenges in the Automatic Analysis of Students' Diagnostic Reasoning
Nov 26, 2018


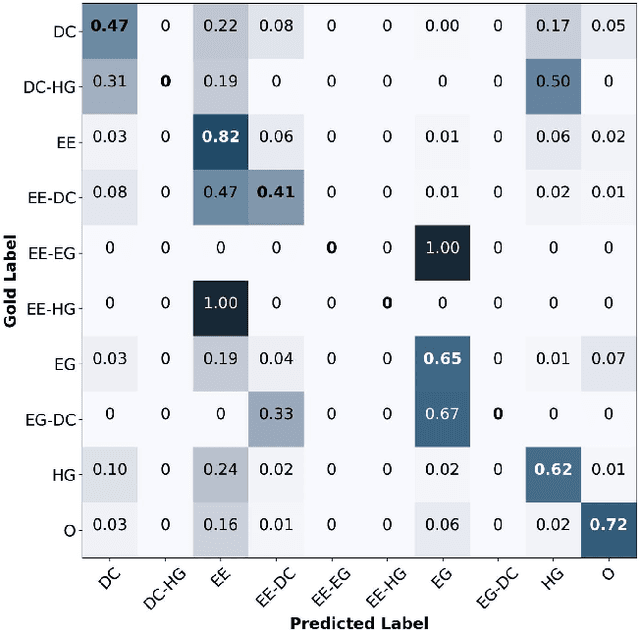
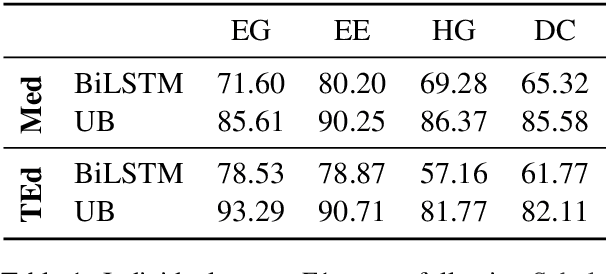
Diagnostic reasoning is a key component of many professions. To improve students' diagnostic reasoning skills, educational psychologists analyse and give feedback on epistemic activities used by these students while diagnosing, in particular, hypothesis generation, evidence generation, evidence evaluation, and drawing conclusions. However, this manual analysis is highly time-consuming. We aim to enable the large-scale adoption of diagnostic reasoning analysis and feedback by automating the epistemic activity identification. We create the first corpus for this task, comprising diagnostic reasoning self-explanations of students from two domains annotated with epistemic activities. Based on insights from the corpus creation and the task's characteristics, we discuss three challenges for the automatic identification of epistemic activities using AI methods: the correct identification of epistemic activity spans, the reliable distinction of similar epistemic activities, and the detection of overlapping epistemic activities. We propose a separate performance metric for each challenge and thus provide an evaluation framework for future research. Indeed, our evaluation of various state-of-the-art recurrent neural network architectures reveals that current techniques fail to address some of these challenges.
Answering the "why" in Answer Set Programming - A Survey of Explanation Approaches
Sep 21, 2018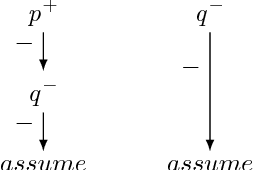
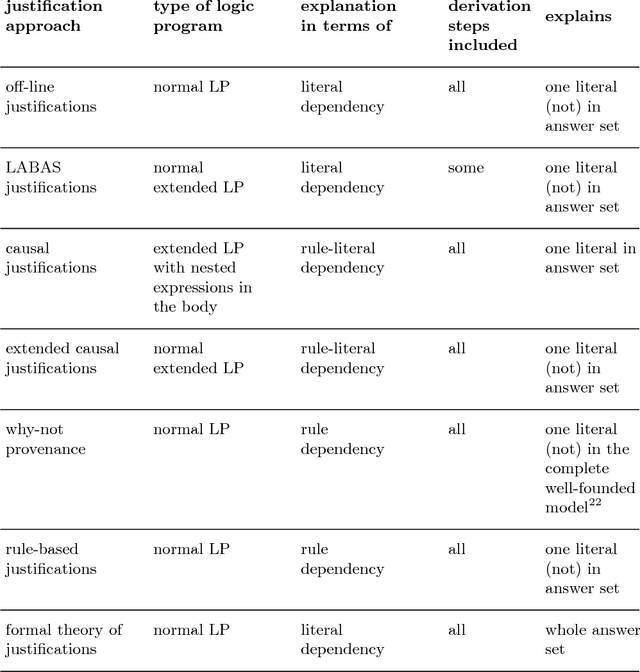

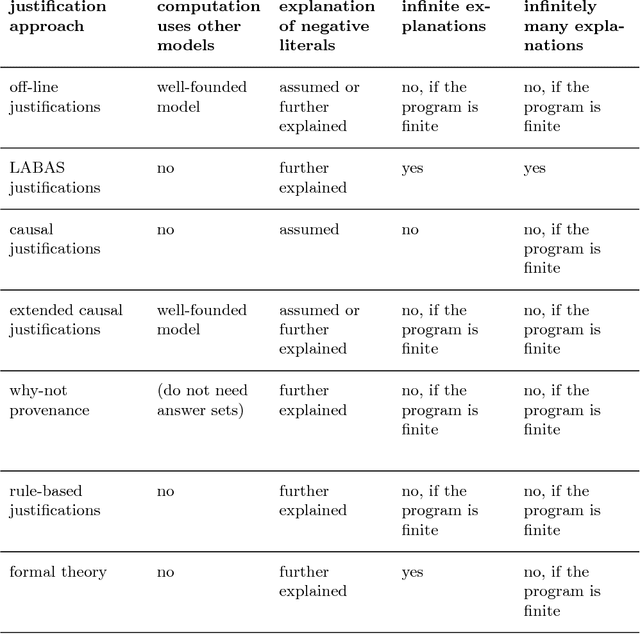
Artificial Intelligence (AI) approaches to problem-solving and decision-making are becoming more and more complex, leading to a decrease in the understandability of solutions. The European Union's new General Data Protection Regulation tries to tackle this problem by stipulating a "right to explanation" for decisions made by AI systems. One of the AI paradigms that may be affected by this new regulation is Answer Set Programming (ASP). Thanks to the emergence of efficient solvers, ASP has recently been used for problem-solving in a variety of domains, including medicine, cryptography, and biology. To ensure the successful application of ASP as a problem-solving paradigm in the future, explanations of ASP solutions are crucial. In this survey, we give an overview of approaches that provide an answer to the question of why an answer set is a solution to a given problem, notably off-line justifications, causal graphs, argumentative explanations and why-not provenance, and highlight their similarities and differences. Moreover, we review methods explaining why a set of literals is not an answer set or why no solution exists at all.