 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Richly Annotated Corpus for Different Tasks in Automated Fact-Checking
Oct 29, 2019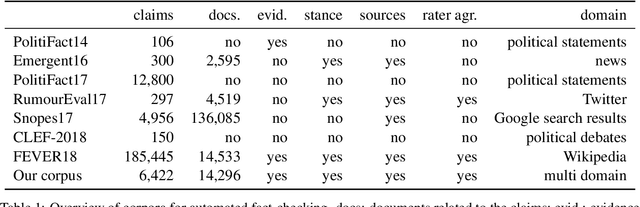
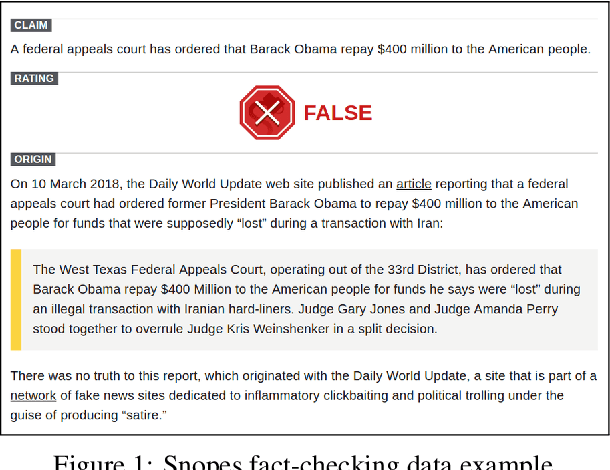
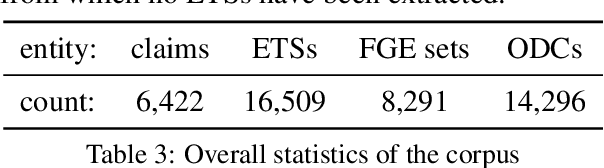
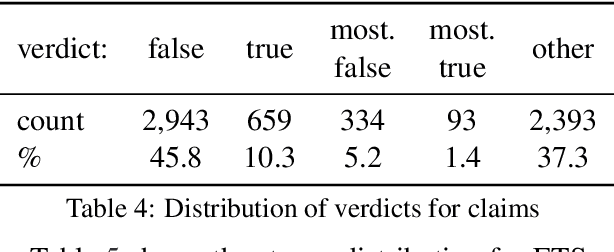
Automated fact-checking based on machine learning is a promising approach to identify false information distributed on the web. In order to achieve satisfactory performance, machine learning methods require a large corpus with reliable annotations for the different tasks in the fact-checking process. Having analyzed existing fact-checking corpora, we found that none of them meets these criteria in full. They are either too small in size, do not provide detailed annotations, or are limited to a single domain. Motivated by this gap, we present a new substantially sized mixed-domain corpus with annotations of good quality for the core fact-checking tasks: document retrieval, evidence extraction, stance detection, and claim validation. To aid future corpus construction, we describe our methodology for corpus creation and annotation, and demonstrate that it results in substantial inter-annotator agreement. As baselines for future research, we perform experiments on our corpus with a number of model architectures that reach high performance in similar problem settings. Finally, to support the development of future models, we provide a detailed error analysis for each of the tasks. Our results show that the realistic, multi-domain setting defined by our data poses new challenges for the existing models, providing opportunities for considerable improvement by future systems.
Classification and Clustering of Arguments with Contextualized Word Embeddings
Jun 24, 2019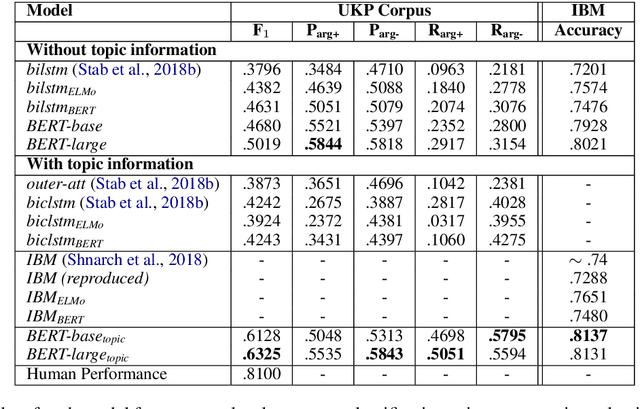
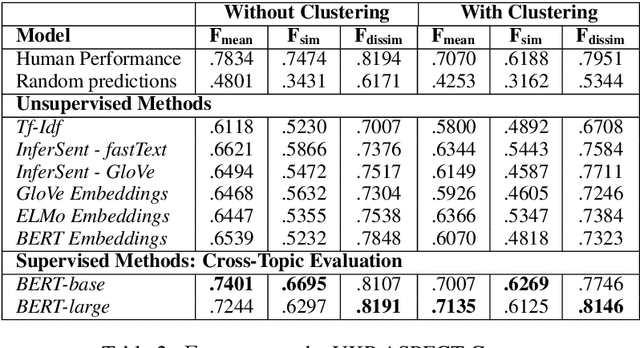
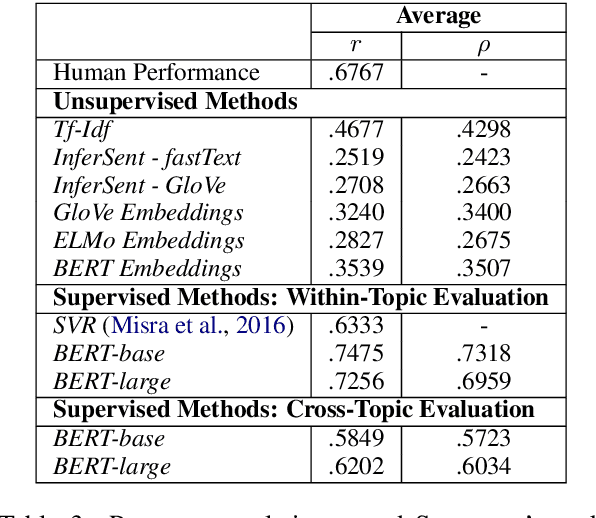
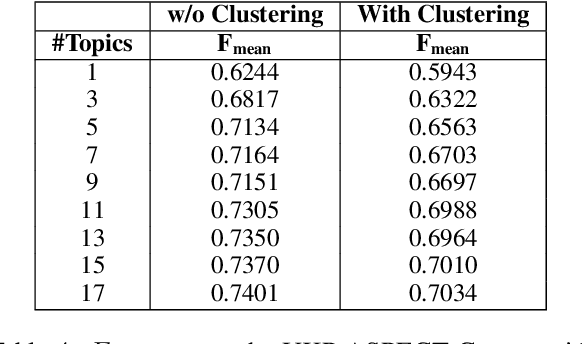
We experiment with two recent contextualized word embedding methods (ELMo and BERT) in the context of open-domain argument search. For the first time, we show how to leverage the power of contextualized word embeddings to classify and cluster topic-dependent arguments, achieving impressive results on both tasks and across multiple datasets. For argument classification, we improve the state-of-the-art for the UKP Sentential Argument Mining Corpus by 20.8 percentage points and for the IBM Debater - Evidence Sentences dataset by 7.4 percentage points. For the understudied task of argument clustering, we propose a pre-training step which improves by 7.8 percentage points over strong baselines on a novel dataset, and by 12.3 percentage points for the Argument Facet Similarity (AFS) Corpus.
Robust Argument Unit Recognition and Classification
Apr 22, 2019
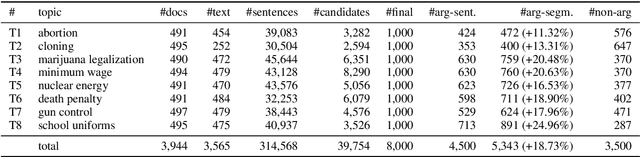
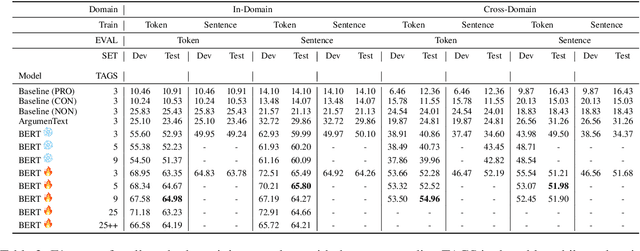
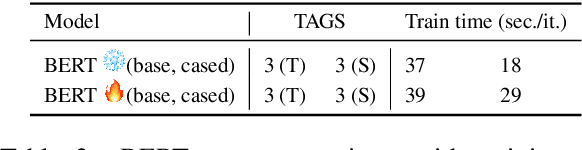
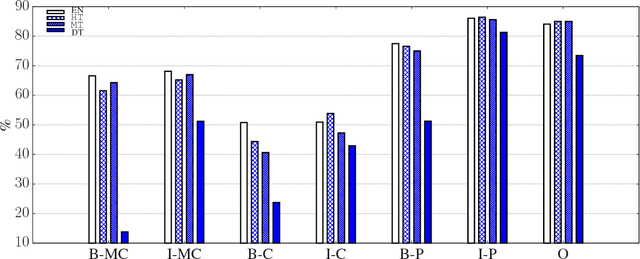
Argument mining is generally performed on the sentence-level -- it is assumed that an entire sentence (not parts of it) corresponds to an argument. In this paper, we introduce the new task of Argument unit Recognition and Classification (ARC). In ARC, an argument is generally a part of a sentence -- a more realistic assumption since several different arguments can occur in one sentence and longer sentences often contain a mix of argumentative and non-argumentative parts. Recognizing and classifying the spans that correspond to arguments makes ARC harder than previously defined argument mining tasks. We release ARC-8, a new benchmark for evaluating the ARC task. We show that token-level annotations for argument units can be gathered using scalable methods. ARC-8 contains 25\% more arguments than a dataset annotated on the sentence-level would. We cast ARC as a sequence labeling task, develop a number of methods for ARC sequence tagging and establish the state of the art for ARC-8. A focus of our work is robustness: both robustness against errors in sentence identification (which are frequent for noisy text) and robustness against divergence in training and test data.
Cross-lingual Argumentation Mining: Machine Translation (and a bit of Projection) is All You Need!
Jul 24, 2018


Argumentation mining (AM) requires the identification of complex discourse structures and has lately been applied with success monolingually. In this work, we show that the existing resources are, however, not adequate for assessing cross-lingual AM, due to their heterogeneity or lack of complexity. We therefore create suitable parallel corpora by (human and machine) translating a popular AM dataset consisting of persuasive student essays into German, French, Spanish, and Chinese. We then compare (i) annotation projection and (ii) bilingual word embeddings based direct transfer strategies for cross-lingual AM, finding that the former performs considerably better and almost eliminates the loss from cross-lingual transfer. Moreover, we find that annotation projection works equally well when using either costly human or cheap machine translations. Our code and data are available at \url{http://github.com/UKPLab/coling2018-xling_argument_mining}.
Cross-topic Argument Mining from Heterogeneous Sources Using Attention-based Neural Networks
Feb 15, 2018
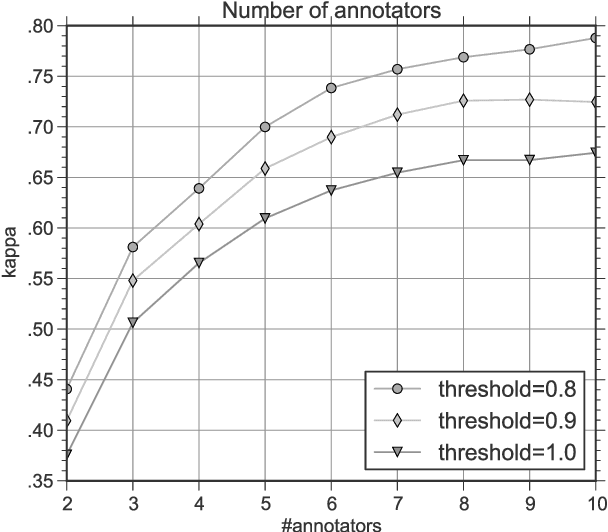
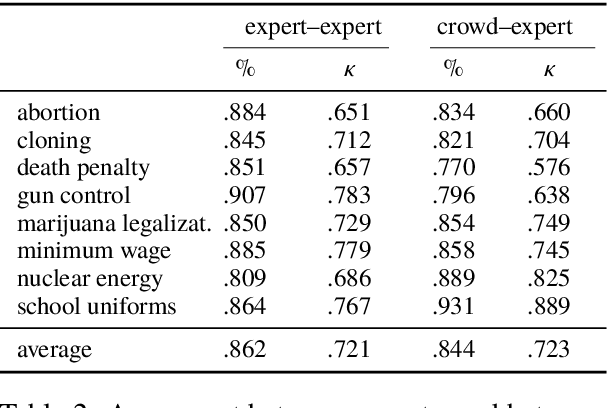
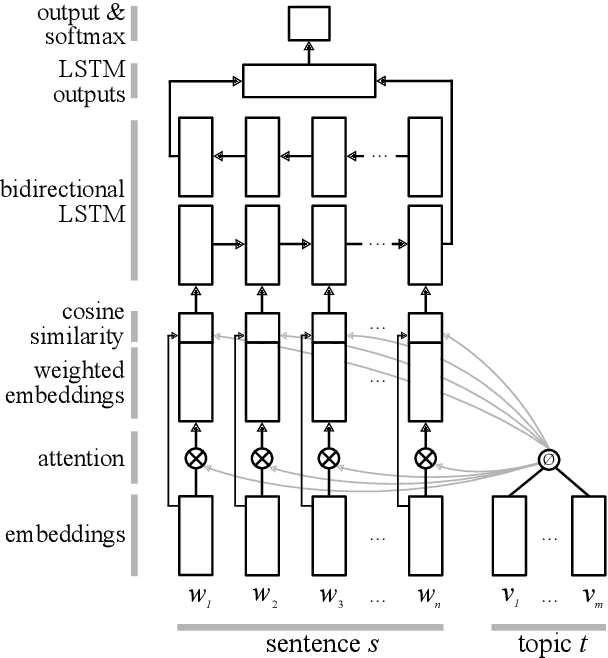
Argument mining is a core technology for automating argument search in large document collections. Despite its usefulness for this task, most current approaches to argument mining are designed for use only with specific text types and fall short when applied to heterogeneous texts. In this paper, we propose a new sentential annotation scheme that is reliably applicable by crowd workers to arbitrary Web texts. We source annotations for over 25,000 instances covering eight controversial topics. The results of cross-topic experiments show that our attention-based neural network generalizes best to unseen topics and outperforms vanilla BiLSTM models by 6% in accuracy and 11% in F-score.
What is the Essence of a Claim? Cross-Domain Claim Identification
Sep 13, 2017
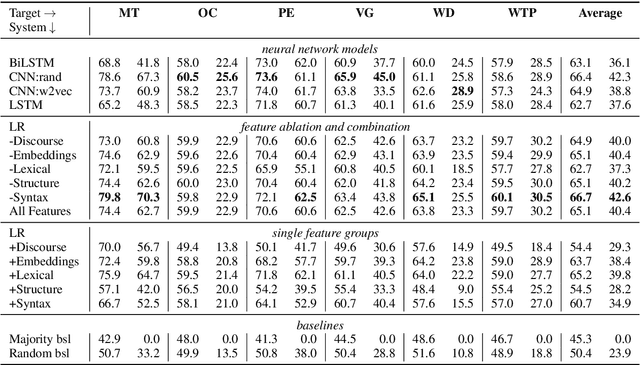
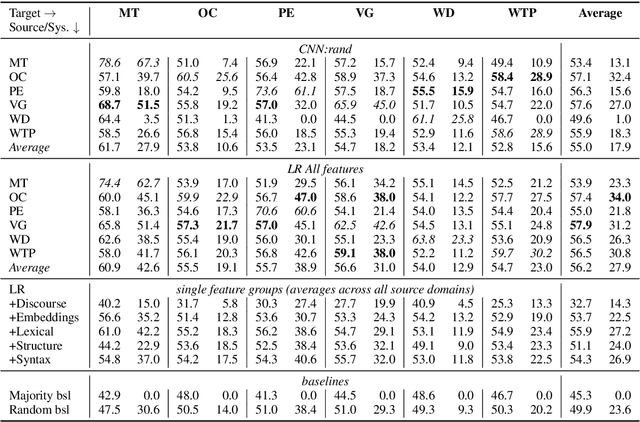

Argument mining has become a popular research area in NLP. It typically includes the identification of argumentative components, e.g. claims, as the central component of an argument. We perform a qualitative analysis across six different datasets and show that these appear to conceptualize claims quite differently. To learn about the consequences of such different conceptualizations of claim for practical applications, we carried out extensive experiments using state-of-the-art feature-rich and deep learning systems, to identify claims in a cross-domain fashion. While the divergent perception of claims in different datasets is indeed harmful to cross-domain classification, we show that there are shared properties on the lexical level as well as system configurations that can help to overcome these gaps.
Parsing Argumentation Structures in Persuasive Essays
Jul 22, 2016In this article, we present a novel approach for parsing argumentation structures. We identify argument components using sequence labeling at the token level and apply a new joint model for detecting argumentation structures. The proposed model globally optimizes argument component types and argumentative relations using integer linear programming. We show that our model considerably improves the performance of base classifiers and significantly outperforms challenging heuristic baselines. Moreover, we introduce a novel corpus of persuasive essays annotated with argumentation structures. We show that our annotation scheme and annotation guidelines successfully guide human annotators to substantial agreement. This corpus and the annotation guidelines are freely available for ensuring reproducibility and to encourage future research in computational argumentation.