 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRobust Argument Unit Recognition and Classification
Paper and Code

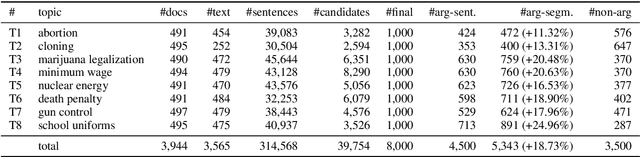
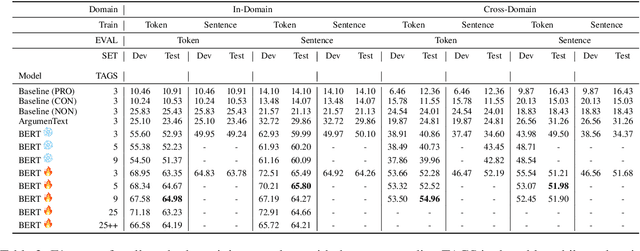
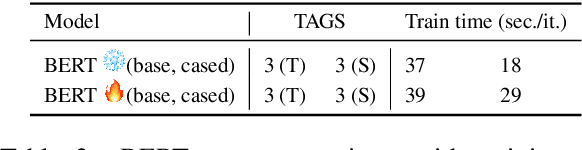
Argument mining is generally performed on the sentence-level -- it is assumed that an entire sentence (not parts of it) corresponds to an argument. In this paper, we introduce the new task of Argument unit Recognition and Classification (ARC). In ARC, an argument is generally a part of a sentence -- a more realistic assumption since several different arguments can occur in one sentence and longer sentences often contain a mix of argumentative and non-argumentative parts. Recognizing and classifying the spans that correspond to arguments makes ARC harder than previously defined argument mining tasks. We release ARC-8, a new benchmark for evaluating the ARC task. We show that token-level annotations for argument units can be gathered using scalable methods. ARC-8 contains 25\% more arguments than a dataset annotated on the sentence-level would. We cast ARC as a sequence labeling task, develop a number of methods for ARC sequence tagging and establish the state of the art for ARC-8. A focus of our work is robustness: both robustness against errors in sentence identification (which are frequent for noisy text) and robustness against divergence in training and test data.