 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCrowdsourcing on Sensitive Data with Privacy-Preserving Text Rewriting
Mar 06, 2023



Most tasks in NLP require labeled data. Data labeling is often done on crowdsourcing platforms due to scalability reasons. However, publishing data on public platforms can only be done if no privacy-relevant information is included. Textual data often contains sensitive information like person names or locations. In this work, we investigate how removing personally identifiable information (PII) as well as applying differential privacy (DP) rewriting can enable text with privacy-relevant information to be used for crowdsourcing. We find that DP-rewriting before crowdsourcing can preserve privacy while still leading to good label quality for certain tasks and data. PII-removal led to good label quality in all examined tasks, however, there are no privacy guarantees given.
On the Effect of Sample and Topic Sizes for Argument Mining Datasets
May 23, 2022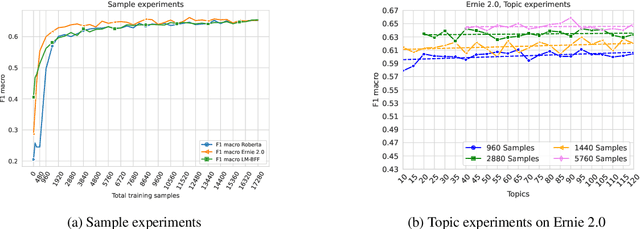
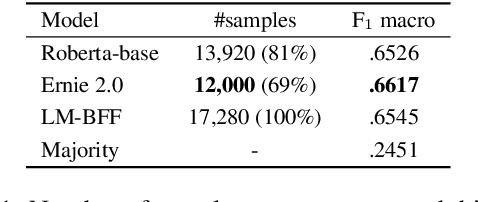
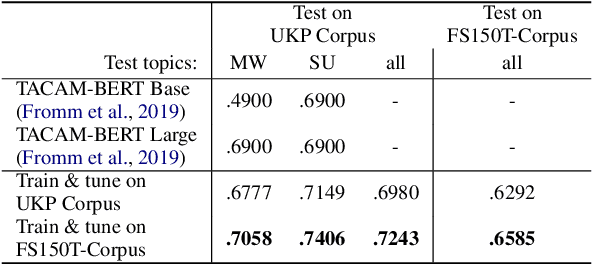
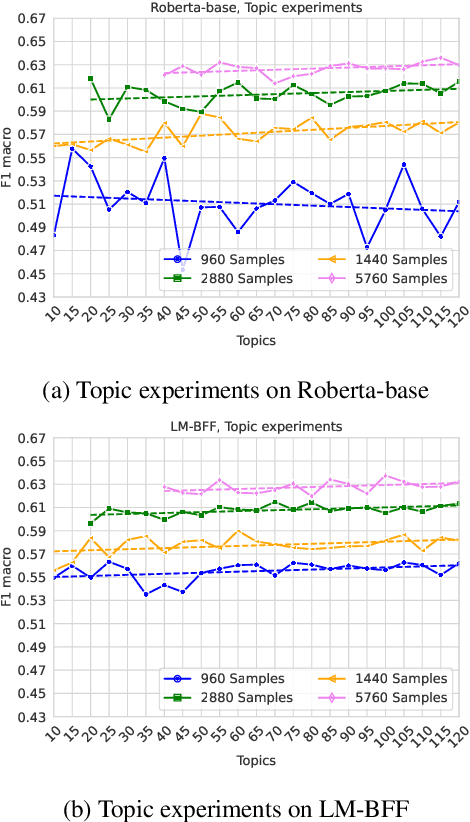
The task of Argument Mining, that is extracting argumentative sentences for a specific topic from large document sources, is an inherently difficult task for machine learning models and humans alike, as large datasets are rare and recognition of argumentative sentences requires expert knowledge. The task becomes even more difficult when it also involves stance detection of retrieved arguments. Recent datasets for the task tend to grow evermore large and hence more costly. In this work, we inquire whether it is necessary for acceptable performance of argument mining to have datasets growing in size or, if not, how smaller datasets have to be composed for optimal performance. We also publish a newly created dataset for future benchmarking.
Augmented SBERT: Data Augmentation Method for Improving Bi-Encoders for Pairwise Sentence Scoring Tasks
Oct 16, 2020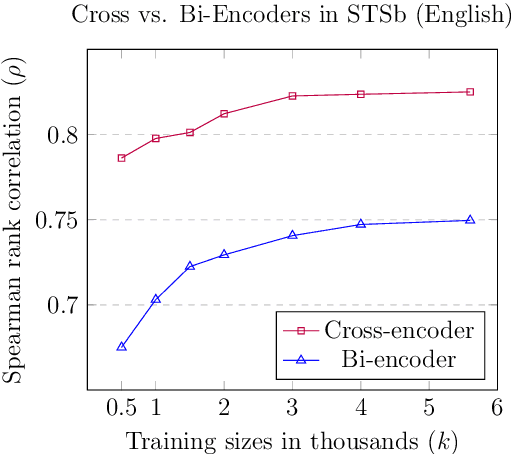

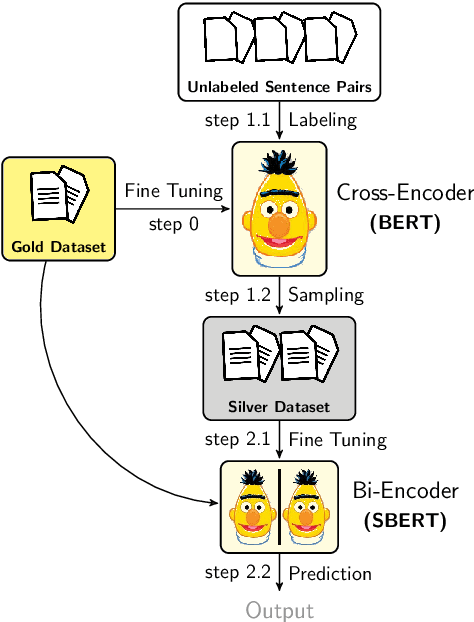

There are two approaches for pairwise sentence scoring: Cross-encoders, which perform full-attention over the input pair, and Bi-encoders, which map each input independently to a dense vector space. While cross-encoders often achieve higher performance, they are too slow for many practical use cases. Bi-encoders, on the other hand, require substantial training data and fine-tuning over the target task to achieve competitive performance. We present a simple yet efficient data augmentation strategy called Augmented SBERT, where we use the cross-encoder to label a larger set of input pairs to augment the training data for the bi-encoder. We show that, in this process, selecting the sentence pairs is non-trivial and crucial for the success of the method. We evaluate our approach on multiple tasks (in-domain) as well as on a domain adaptation task. Augmented SBERT achieves an improvement of up to 6 points for in-domain and of up to 37 points for domain adaptation tasks compared to the original bi-encoder performance.
How to Probe Sentence Embeddings in Low-Resource Languages: On Structural Design Choices for Probing Task Evaluation
Jun 16, 2020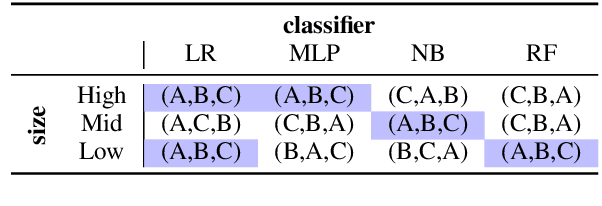
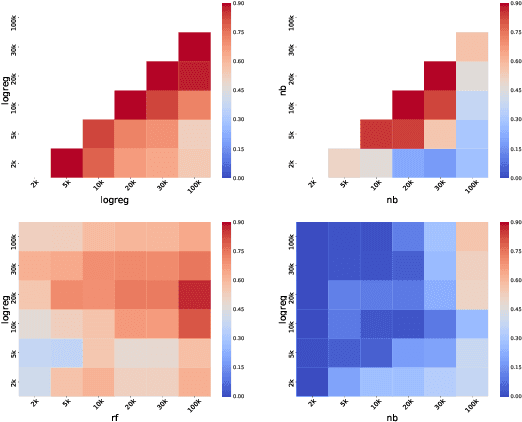
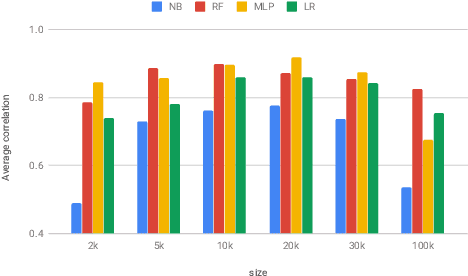
Sentence encoders map sentences to real valued vectors for use in downstream applications. To peek into these representations - e.g., to increase interpretability of their results - probing tasks have been designed which query them for linguistic knowledge. However, designing probing tasks for lesser-resourced languages is tricky, because these often lack large-scale annotated data or (high-quality) dependency parsers as a prerequisite of probing task design in English. To investigate how to probe sentence embeddings in such cases, we investigate sensitivity of probing task results to structural design choices, conducting the first such large scale study. We show that design choices like size of the annotated probing dataset and type of classifier used for evaluation do (sometimes substantially) influence probing outcomes. We then probe embeddings in a multilingual setup with design choices that lie in a 'stable region', as we identify for English, and find that results on English do not transfer to other languages. Fairer and more comprehensive sentence-level probing evaluation should thus be carried out on multiple languages in the future.
Aspect-Controlled Neural Argument Generation
Apr 30, 2020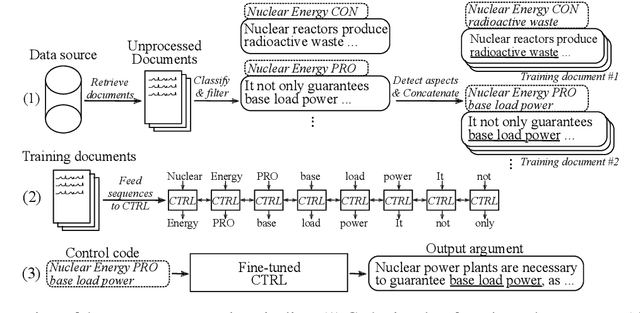
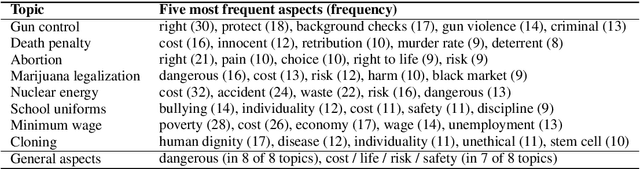

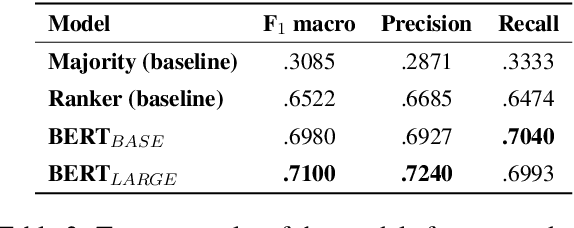
We rely on arguments in our daily lives to deliver our opinions and base them on evidence, making them more convincing in turn. However, finding and formulating arguments can be challenging. In this work, we train a language model for argument generation that can be controlled on a fine-grained level to generate sentence-level arguments for a given topic, stance, and aspect. We define argument aspect detection as a necessary method to allow this fine-granular control and crowdsource a dataset with 5,032 arguments annotated with aspects. Our evaluation shows that our generation model is able to generate high-quality, aspect-specific arguments. Moreover, these arguments can be used to improve the performance of stance detection models via data augmentation and to generate counter-arguments. We publish all datasets and code to fine-tune the language model.
Stance Detection Benchmark: How Robust Is Your Stance Detection?
Jan 06, 2020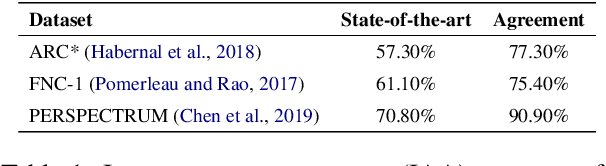
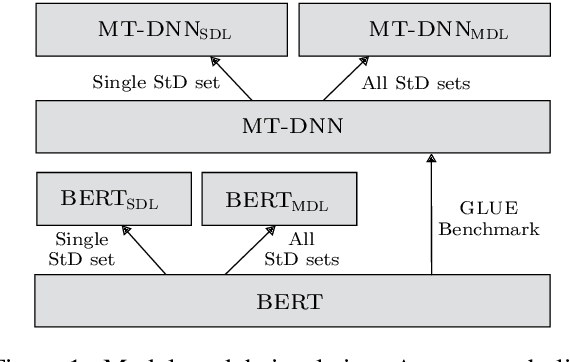
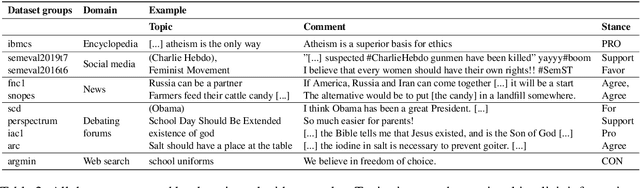
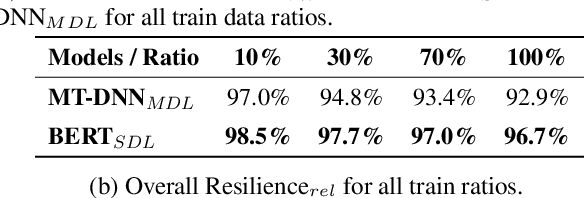
Stance Detection (StD) aims to detect an author's stance towards a certain topic or claim and has become a key component in applications like fake news detection, claim validation, and argument search. However, while stance is easily detected by humans, machine learning models are clearly falling short of this task. Given the major differences in dataset sizes and framing of StD (e.g. number of classes and inputs), we introduce a StD benchmark that learns from ten StD datasets of various domains in a multi-dataset learning (MDL) setting, as well as from related tasks via transfer learning. Within this benchmark setup, we are able to present new state-of-the-art results on five of the datasets. Yet, the models still perform well below human capabilities and even simple adversarial attacks severely hurt the performance of MDL models. Deeper investigation into this phenomenon suggests the existence of biases inherited from multiple datasets by design. Our analysis emphasizes the need of focus on robustness and de-biasing strategies in multi-task learning approaches. The benchmark dataset and code is made available.
Classification and Clustering of Arguments with Contextualized Word Embeddings
Jun 24, 2019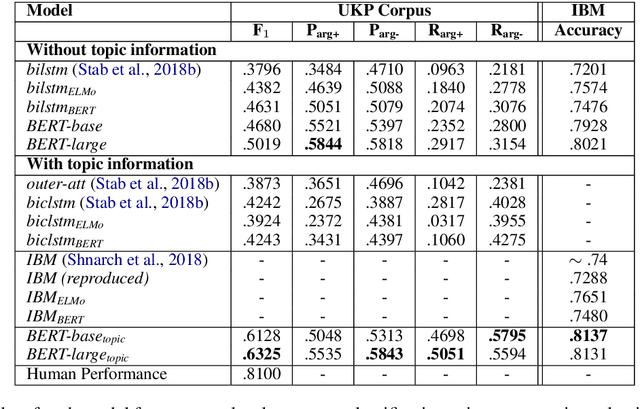
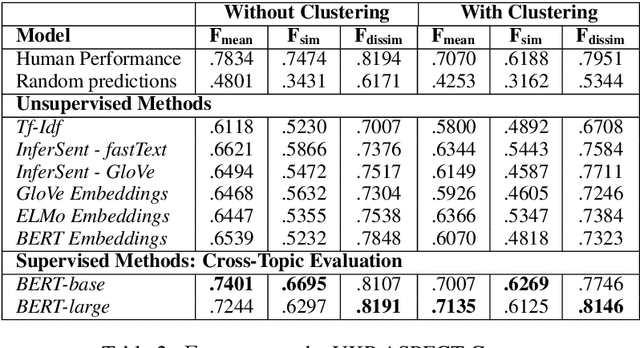
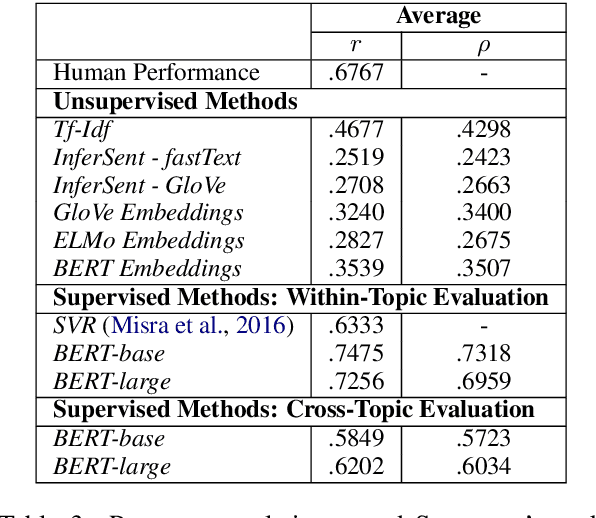
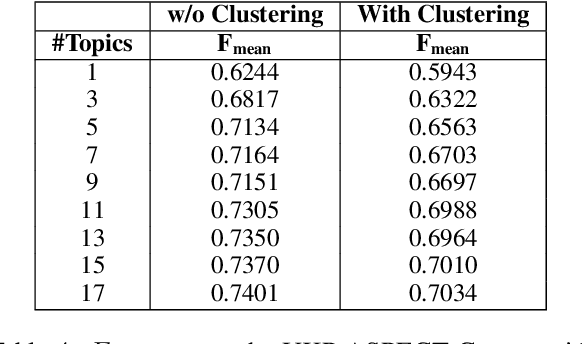
We experiment with two recent contextualized word embedding methods (ELMo and BERT) in the context of open-domain argument search. For the first time, we show how to leverage the power of contextualized word embeddings to classify and cluster topic-dependent arguments, achieving impressive results on both tasks and across multiple datasets. For argument classification, we improve the state-of-the-art for the UKP Sentential Argument Mining Corpus by 20.8 percentage points and for the IBM Debater - Evidence Sentences dataset by 7.4 percentage points. For the understudied task of argument clustering, we propose a pre-training step which improves by 7.8 percentage points over strong baselines on a novel dataset, and by 12.3 percentage points for the Argument Facet Similarity (AFS) Corpus.
Robust Argument Unit Recognition and Classification
Apr 22, 2019
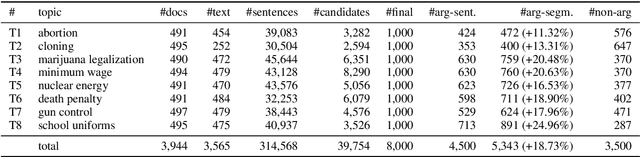
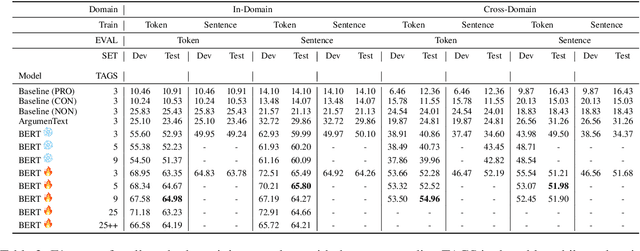
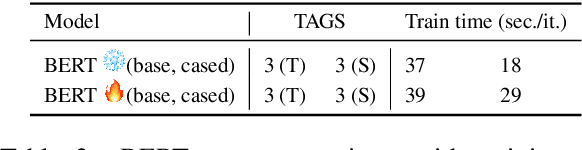
Argument mining is generally performed on the sentence-level -- it is assumed that an entire sentence (not parts of it) corresponds to an argument. In this paper, we introduce the new task of Argument unit Recognition and Classification (ARC). In ARC, an argument is generally a part of a sentence -- a more realistic assumption since several different arguments can occur in one sentence and longer sentences often contain a mix of argumentative and non-argumentative parts. Recognizing and classifying the spans that correspond to arguments makes ARC harder than previously defined argument mining tasks. We release ARC-8, a new benchmark for evaluating the ARC task. We show that token-level annotations for argument units can be gathered using scalable methods. ARC-8 contains 25\% more arguments than a dataset annotated on the sentence-level would. We cast ARC as a sequence labeling task, develop a number of methods for ARC sequence tagging and establish the state of the art for ARC-8. A focus of our work is robustness: both robustness against errors in sentence identification (which are frequent for noisy text) and robustness against divergence in training and test data.
Cross-lingual Argumentation Mining: Machine Translation (and a bit of Projection) is All You Need!
Jul 24, 2018
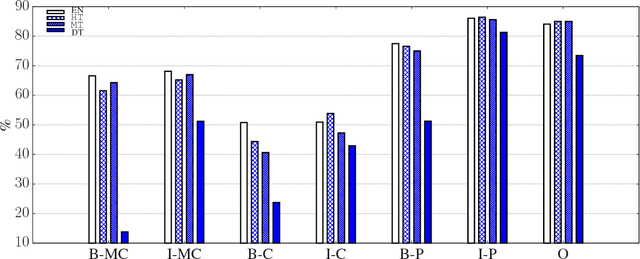


Argumentation mining (AM) requires the identification of complex discourse structures and has lately been applied with success monolingually. In this work, we show that the existing resources are, however, not adequate for assessing cross-lingual AM, due to their heterogeneity or lack of complexity. We therefore create suitable parallel corpora by (human and machine) translating a popular AM dataset consisting of persuasive student essays into German, French, Spanish, and Chinese. We then compare (i) annotation projection and (ii) bilingual word embeddings based direct transfer strategies for cross-lingual AM, finding that the former performs considerably better and almost eliminates the loss from cross-lingual transfer. Moreover, we find that annotation projection works equally well when using either costly human or cheap machine translations. Our code and data are available at \url{http://github.com/UKPLab/coling2018-xling_argument_mining}.
Multi-Task Learning for Argumentation Mining in Low-Resource Settings
May 04, 2018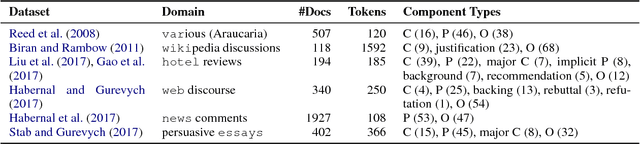
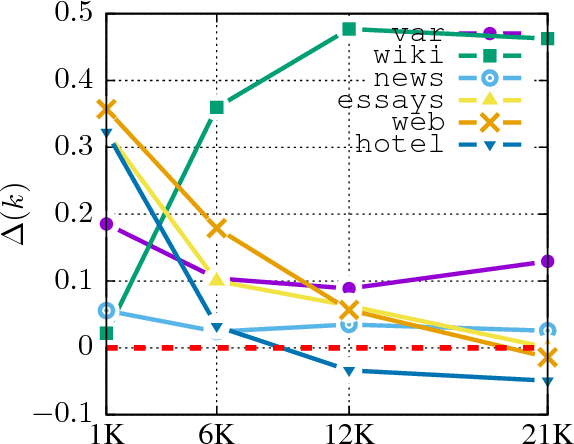
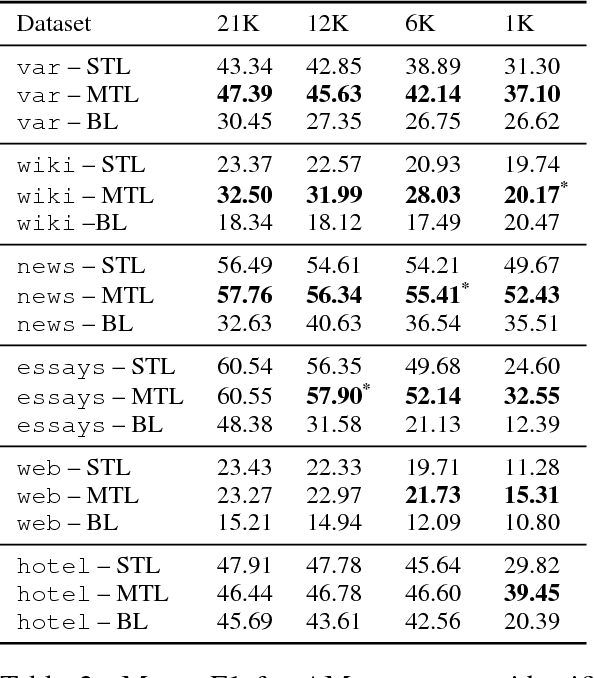
We investigate whether and where multi-task learning (MTL) can improve performance on NLP problems related to argumentation mining (AM), in particular argument component identification. Our results show that MTL performs particularly well (and better than single-task learning) when little training data is available for the main task, a common scenario in AM. Our findings challenge previous assumptions that conceptualizations across AM datasets are divergent and that MTL is difficult for semantic or higher-level tasks.