 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGRITHopper: Decomposition-Free Multi-Hop Dense Retrieval
Mar 10, 2025Decomposition-based multi-hop retrieval methods rely on many autoregressive steps to break down complex queries, which breaks end-to-end differentiability and is computationally expensive. Decomposition-free methods tackle this, but current decomposition-free approaches struggle with longer multi-hop problems and generalization to out-of-distribution data. To address these challenges, we introduce GRITHopper-7B, a novel multi-hop dense retrieval model that achieves state-of-the-art performance on both in-distribution and out-of-distribution benchmarks. GRITHopper combines generative and representational instruction tuning by integrating causal language modeling with dense retrieval training. Through controlled studies, we find that incorporating additional context after the retrieval process, referred to as post-retrieval language modeling, enhances dense retrieval performance. By including elements such as final answers during training, the model learns to better contextualize and retrieve relevant information. GRITHopper-7B offers a robust, scalable, and generalizable solution for multi-hop dense retrieval, and we release it to the community for future research and applications requiring multi-hop reasoning and retrieval capabilities.
Triple-Encoders: Representations That Fire Together, Wire Together
Feb 19, 2024



Search-based dialog models typically re-encode the dialog history at every turn, incurring high cost. Curved Contrastive Learning, a representation learning method that encodes relative distances between utterances into the embedding space via a bi-encoder, has recently shown promising results for dialog modeling at far superior efficiency. While high efficiency is achieved through independently encoding utterances, this ignores the importance of contextualization. To overcome this issue, this study introduces triple-encoders, which efficiently compute distributed utterance mixtures from these independently encoded utterances through a novel hebbian inspired co-occurrence learning objective without using any weights. Empirically, we find that triple-encoders lead to a substantial improvement over bi-encoders, and even to better zero-shot generalization than single-vector representation models without requiring re-encoding. Our code/model is publicly available.
DAPR: A Benchmark on Document-Aware Passage Retrieval
May 23, 2023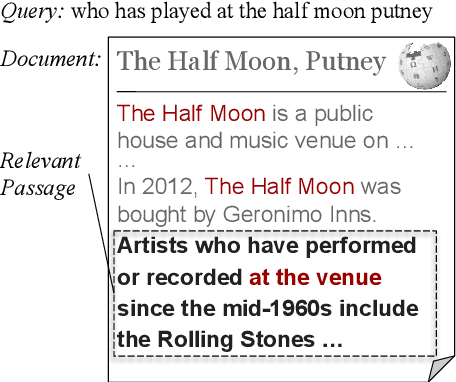


Recent neural retrieval mainly focuses on ranking short texts and is challenged with long documents. Existing work mainly evaluates either ranking passages or whole documents. However, there are many cases where the users want to find a relevant passage within a long document from a huge corpus, e.g. legal cases, research papers, etc. In this scenario, the passage often provides little document context and thus challenges the current approaches to finding the correct document and returning accurate results. To fill this gap, we propose and name this task Document-Aware Passage Retrieval (DAPR) and build a benchmark including multiple datasets from various domains, covering both DAPR and whole-document retrieval. In experiments, we extend the state-of-the-art neural passage retrievers with document-level context via different approaches including prepending document summary, pooling over passage representations, and hybrid retrieval with BM25. The hybrid-retrieval systems, the overall best, can only improve on the DAPR tasks marginally while significantly improving on the document-retrieval tasks. This motivates further research in developing better retrieval systems for the new task. The code and the data are available at https://github.com/kwang2049/dapr
Incorporating Relevance Feedback for Information-Seeking Retrieval using Few-Shot Document Re-Ranking
Oct 19, 2022
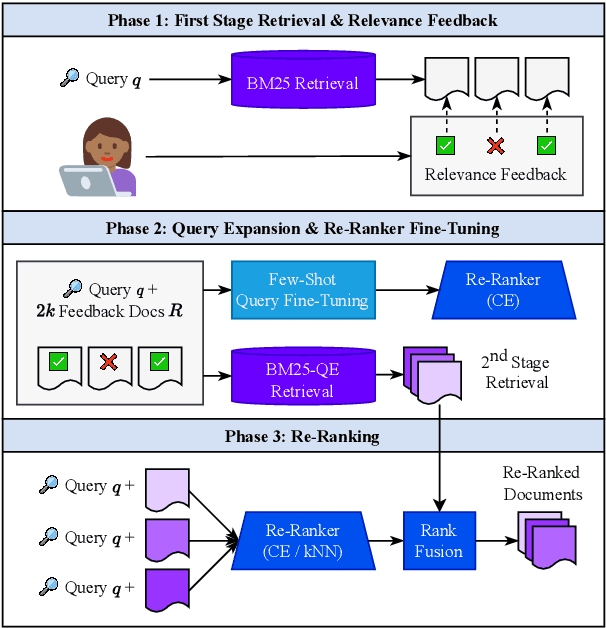
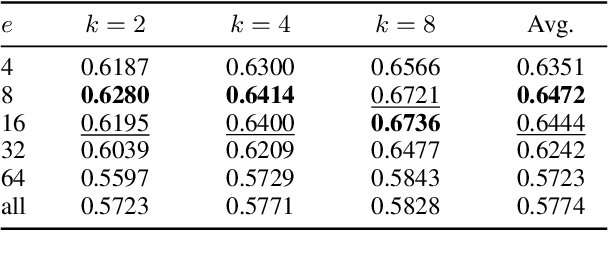
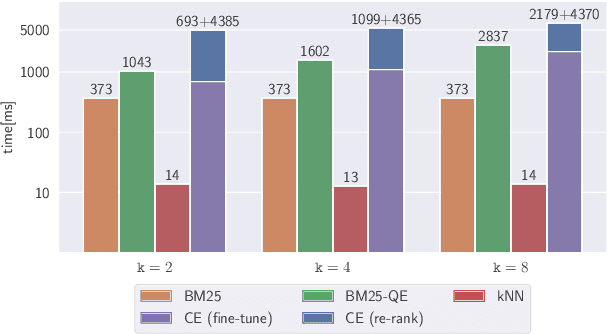
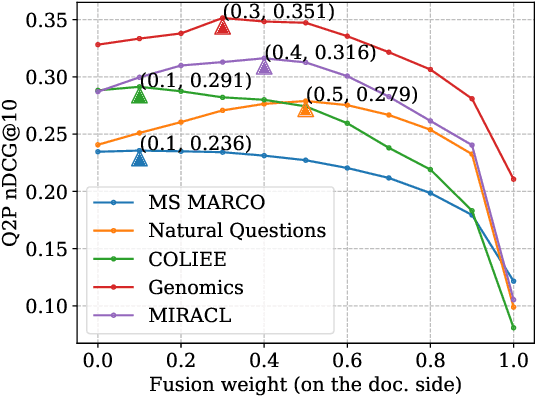
Pairing a lexical retriever with a neural re-ranking model has set state-of-the-art performance on large-scale information retrieval datasets. This pipeline covers scenarios like question answering or navigational queries, however, for information-seeking scenarios, users often provide information on whether a document is relevant to their query in form of clicks or explicit feedback. Therefore, in this work, we explore how relevance feedback can be directly integrated into neural re-ranking models by adopting few-shot and parameter-efficient learning techniques. Specifically, we introduce a kNN approach that re-ranks documents based on their similarity with the query and the documents the user considers relevant. Further, we explore Cross-Encoder models that we pre-train using meta-learning and subsequently fine-tune for each query, training only on the feedback documents. To evaluate our different integration strategies, we transform four existing information retrieval datasets into the relevance feedback scenario. Extensive experiments demonstrate that integrating relevance feedback directly in neural re-ranking models improves their performance, and fusing lexical ranking with our best performing neural re-ranker outperforms all other methods by 5.2 nDCG@20.
MTEB: Massive Text Embedding Benchmark
Oct 13, 2022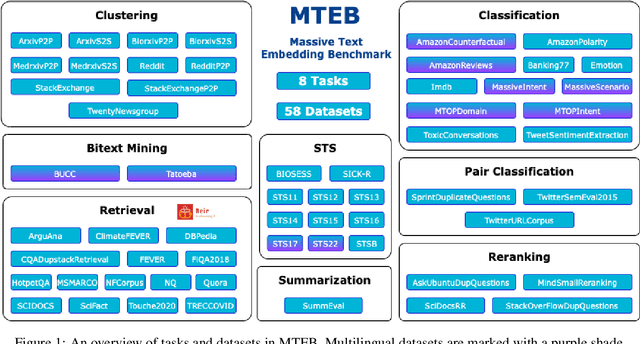
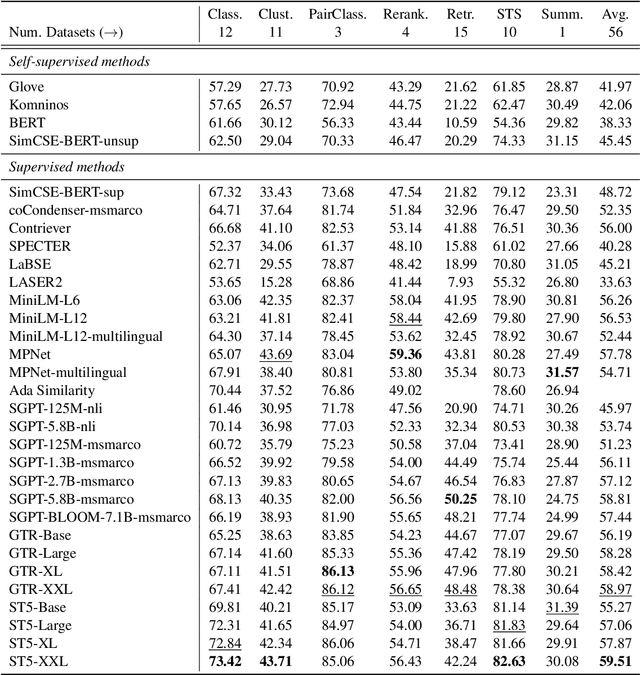
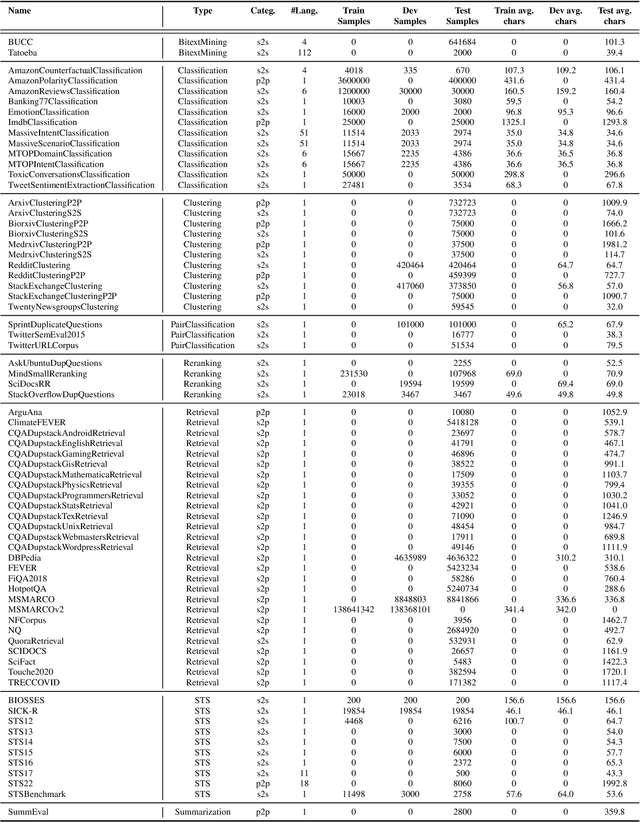
Text embeddings are commonly evaluated on a small set of datasets from a single task not covering their possible applications to other tasks. It is unclear whether state-of-the-art embeddings on semantic textual similarity (STS) can be equally well applied to other tasks like clustering or reranking. This makes progress in the field difficult to track, as various models are constantly being proposed without proper evaluation. To solve this problem, we introduce the Massive Text Embedding Benchmark (MTEB). MTEB spans 8 embedding tasks covering a total of 56 datasets and 112 languages. Through the benchmarking of 33 models on MTEB, we establish the most comprehensive benchmark of text embeddings to date. We find that no particular text embedding method dominates across all tasks. This suggests that the field has yet to converge on a universal text embedding method and scale it up sufficiently to provide state-of-the-art results on all embedding tasks. MTEB comes with open-source code and a public leaderboard at https://huggingface.co/spaces/mteb/leaderboard.
Efficient Few-Shot Learning Without Prompts
Sep 22, 2022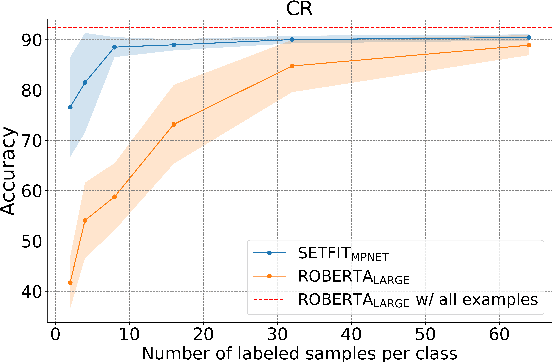

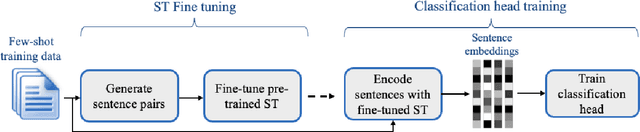
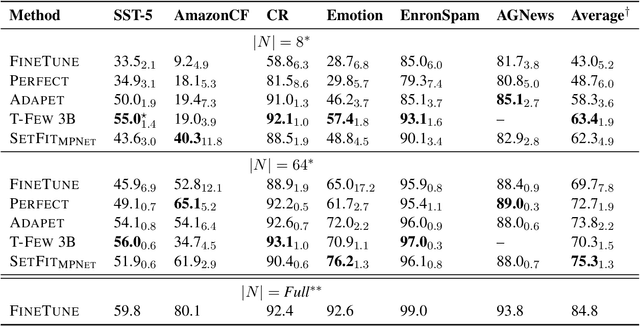
Recent few-shot methods, such as parameter-efficient fine-tuning (PEFT) and pattern exploiting training (PET), have achieved impressive results in label-scarce settings. However, they are difficult to employ since they are subject to high variability from manually crafted prompts, and typically require billion-parameter language models to achieve high accuracy. To address these shortcomings, we propose SetFit (Sentence Transformer Fine-tuning), an efficient and prompt-free framework for few-shot fine-tuning of Sentence Transformers (ST). SetFit works by first fine-tuning a pretrained ST on a small number of text pairs, in a contrastive Siamese manner. The resulting model is then used to generate rich text embeddings, which are used to train a classification head. This simple framework requires no prompts or verbalizers, and achieves high accuracy with orders of magnitude less parameters than existing techniques. Our experiments show that SetFit obtains comparable results with PEFT and PET techniques, while being an order of magnitude faster to train. We also show that SetFit can be applied in multilingual settings by simply switching the ST body. Our code is available at https://github.com/huggingface/setfit and our datasets at https://huggingface.co/setfit .
Domain Adaptation for Memory-Efficient Dense Retrieval
May 23, 2022
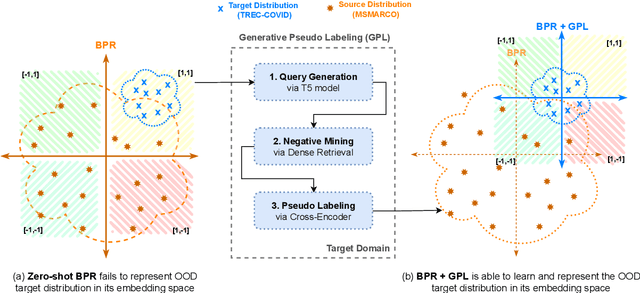


Dense retrievers encode documents into fixed dimensional embeddings. However, storing all the document embeddings within an index produces bulky indexes which are expensive to serve. Recently, BPR (Yamada et al., 2021) and JPQ (Zhan et al., 2021a) have been proposed which train the model to produce binary document vectors, which reduce the index 32x and more. The authors showed these binary embedding models significantly outperform more traditional index compression techniques like Product Quantization (PQ). Previous work evaluated these approaches just in-domain, i.e. the methods were evaluated on tasks for which training data is available. In practice, retrieval models are often used in an out-of-domain setting, where they have been trained on a publicly available dataset, like MS MARCO, but are then used for some custom dataset for which no training data is available. In this work, we show that binary embedding models like BPR and JPQ can perform significantly worse than baselines once there is a domain-shift involved. We propose a modification to the training procedure of BPR and JPQ and combine it with a corpus specific generative procedure which allow the adaptation of BPR and JPQ to any corpus without requiring labeled training data. Our domain-adapted strategy known as GPL is model agnostic, achieves an improvement by up-to 19.3 and 11.6 points in nDCG@10 across the BEIR benchmark in comparison to BPR and JPQ while maintaining its 32x memory efficiency. JPQ+GPL even outperforms our upper baseline: uncompressed TAS-B model on average by 2.0 points.
UKP-SQUARE: An Online Platform for Question Answering Research
Mar 28, 2022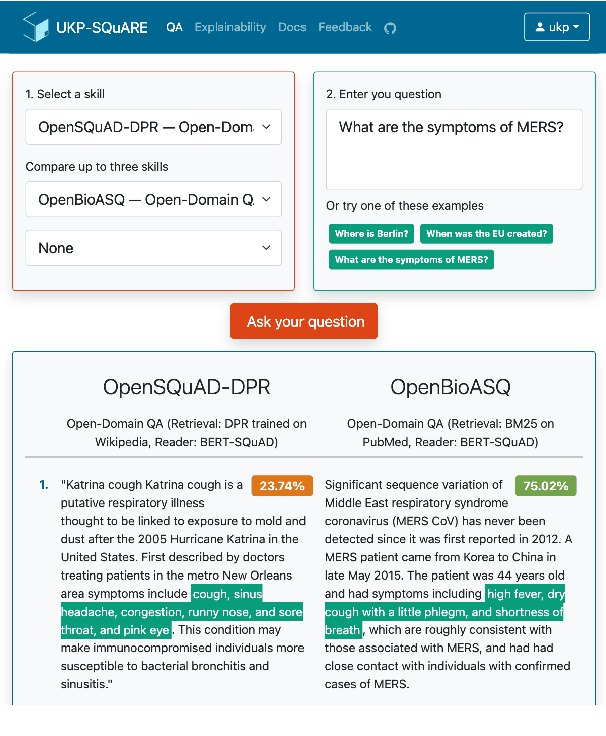

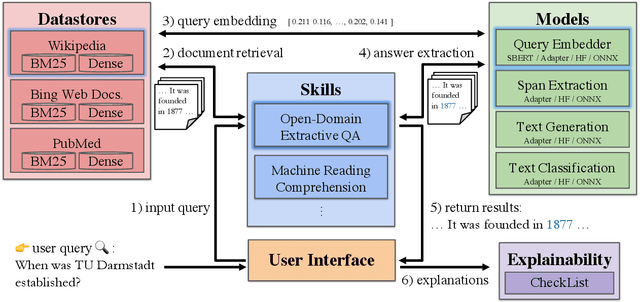
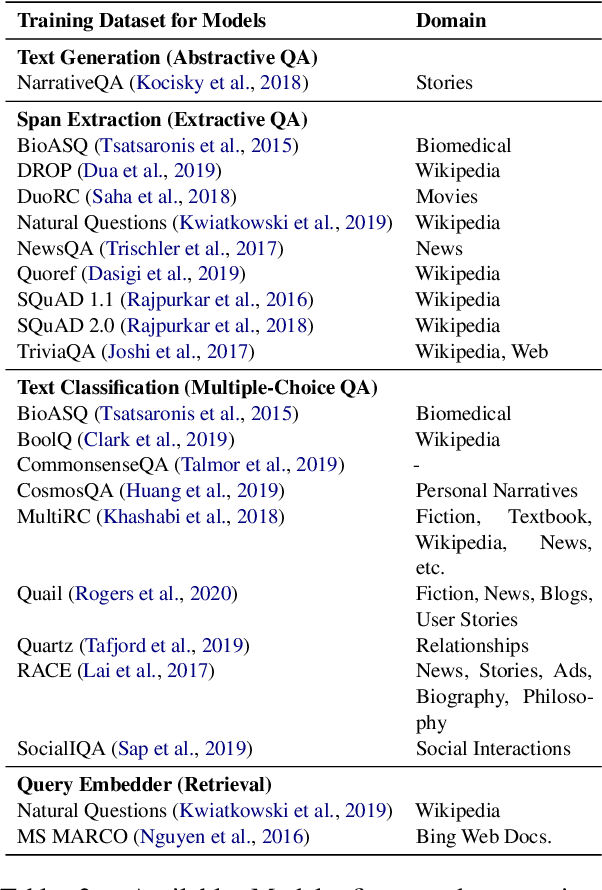
Recent advances in NLP and information retrieval have given rise to a diverse set of question answering tasks that are of different formats (e.g., extractive, abstractive), require different model architectures (e.g., generative, discriminative), and setups (e.g., with or without retrieval). Despite having a large number of powerful, specialized QA pipelines (which we refer to as Skills) that consider a single domain, model or setup, there exists no framework where users can easily explore and compare such pipelines and can extend them according to their needs. To address this issue, we present UKP-SQUARE, an extensible online QA platform for researchers which allows users to query and analyze a large collection of modern Skills via a user-friendly web interface and integrated behavioural tests. In addition, QA researchers can develop, manage, and share their custom Skills using our microservices that support a wide range of models (Transformers, Adapters, ONNX), datastores and retrieval techniques (e.g., sparse and dense). UKP-SQUARE is available on https://square.ukp-lab.de.
GPL: Generative Pseudo Labeling for Unsupervised Domain Adaptation of Dense Retrieval
Dec 14, 2021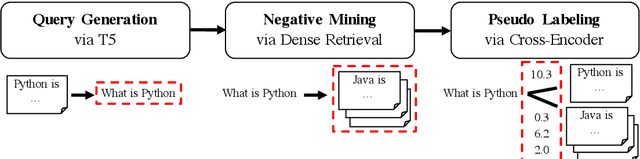
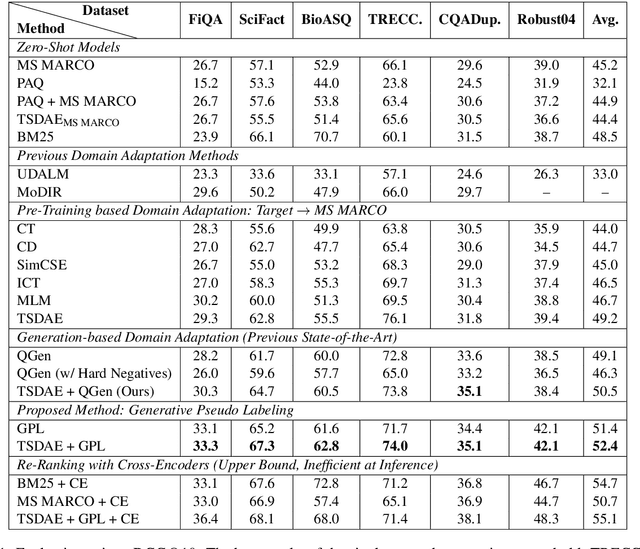

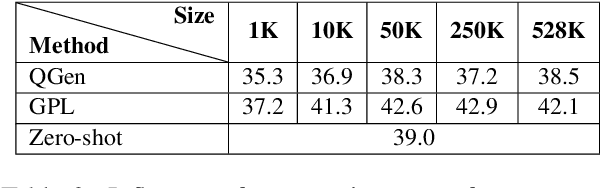
Dense retrieval approaches can overcome the lexical gap and lead to significantly improved search results. However, they require large amounts of training data which is not available for most domains. As shown in previous work (Thakur et al., 2021b), the performance of dense retrievers severely degrades under a domain shift. This limits the usage of dense retrieval approaches to only a few domains with large training datasets. In this paper, we propose the novel unsupervised domain adaptation method Generative Pseudo Labeling (GPL), which combines a query generator with pseudo labeling from a cross-encoder. On six representative domain-specialized datasets, we find the proposed GPL can outperform an out-of-the-box state-of-the-art dense retrieval approach by up to 8.9 points nDCG@10. GPL requires less (unlabeled) data from the target domain and is more robust in its training than previous methods. We further investigate the role of six recent pre-training methods in the scenario of domain adaptation for retrieval tasks, where only three could yield improved results. The best approach, TSDAE (Wang et al., 2021) can be combined with GPL, yielding another average improvement of 1.0 points nDCG@10 across the six tasks.
BEIR: A Heterogenous Benchmark for Zero-shot Evaluation of Information Retrieval Models
Apr 28, 2021
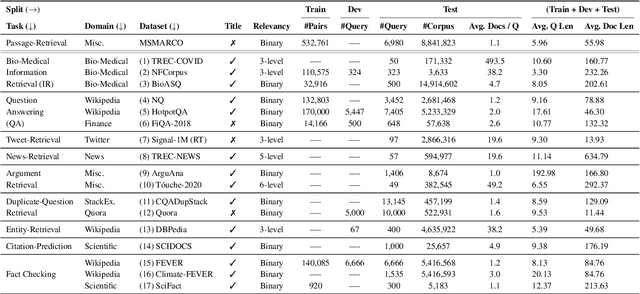


Neural IR models have often been studied in homogeneous and narrow settings, which has considerably limited insights into their generalization capabilities. To address this, and to allow researchers to more broadly establish the effectiveness of their models, we introduce BEIR (Benchmarking IR), a heterogeneous benchmark for information retrieval. We leverage a careful selection of 17 datasets for evaluation spanning diverse retrieval tasks including open-domain datasets as well as narrow expert domains. We study the effectiveness of nine state-of-the-art retrieval models in a zero-shot evaluation setup on BEIR, finding that performing well consistently across all datasets is challenging. Our results show BM25 is a robust baseline and Reranking-based models overall achieve the best zero-shot performances, however, at high computational costs. In contrast, Dense-retrieval models are computationally more efficient but often underperform other approaches, highlighting the considerable room for improvement in their generalization capabilities. In this work, we extensively analyze different retrieval models and provide several suggestions that we believe may be useful for future work. BEIR datasets and code are available at https://github.com/UKPLab/beir.