 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Template Is All You Meme
Nov 11, 2023Memes are a modern form of communication and meme templates possess a base semantics that is customizable by whomever posts it on social media. Machine learning systems struggle with memes, which is likely due to such systems having insufficient context to understand memes, as there is more to memes than the obvious image and text. Here, to aid understanding of memes, we release a knowledge base of memes and information found on www.knowyourmeme.com, which we call the Know Your Meme Knowledge Base (KYMKB), composed of more than 54,000 images. The KYMKB includes popular meme templates, examples of each template, and detailed information about the template. We hypothesize that meme templates can be used to inject models with the context missing from previous approaches. To test our hypothesis, we create a non-parametric majority-based classifier, which we call Template-Label Counter (TLC). We find TLC more effective than or competitive with fine-tuned baselines. To demonstrate the power of meme templates and the value of both our knowledge base and method, we conduct thorough classification experiments and exploratory data analysis in the context of five meme analysis tasks.
Lessons Learned from a Citizen Science Project for Natural Language Processing
Apr 25, 2023



Many Natural Language Processing (NLP) systems use annotated corpora for training and evaluation. However, labeled data is often costly to obtain and scaling annotation projects is difficult, which is why annotation tasks are often outsourced to paid crowdworkers. Citizen Science is an alternative to crowdsourcing that is relatively unexplored in the context of NLP. To investigate whether and how well Citizen Science can be applied in this setting, we conduct an exploratory study into engaging different groups of volunteers in Citizen Science for NLP by re-annotating parts of a pre-existing crowdsourced dataset. Our results show that this can yield high-quality annotations and attract motivated volunteers, but also requires considering factors such as scalability, participation over time, and legal and ethical issues. We summarize lessons learned in the form of guidelines and provide our code and data to aid future work on Citizen Science.
Like a Good Nearest Neighbor: Practical Content Moderation with Sentence Transformers
Mar 02, 2023Modern text classification systems have impressive capabilities but are infeasible to deploy and use reliably due to their dependence on prompting and billion-parameter language models. SetFit (Tunstall et al., 2022) is a recent, practical approach that fine-tunes a Sentence Transformer under a contrastive learning paradigm and achieves similar results to more unwieldy systems. Text classification is important for addressing the problem of domain drift in detecting harmful content, which plagues all social media platforms. Here, we propose Like a Good Nearest Neighbor (LaGoNN), an inexpensive modification to SetFit that requires no additional parameters or hyperparameters but modifies input with information about its nearest neighbor, for example, the label and text, in the training data, making novel data appear similar to an instance on which the model was optimized. LaGoNN is effective at the task of detecting harmful content and generally improves performance compared to SetFit. To demonstrate the value of our system, we conduct a thorough study of text classification systems in the context of content moderation under four label distributions.
Efficient Few-Shot Learning Without Prompts
Sep 22, 2022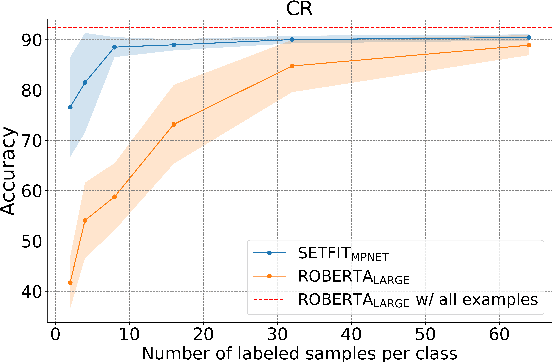

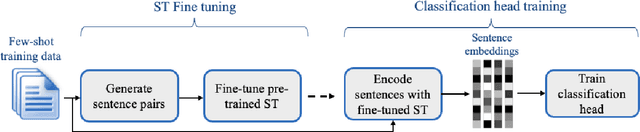
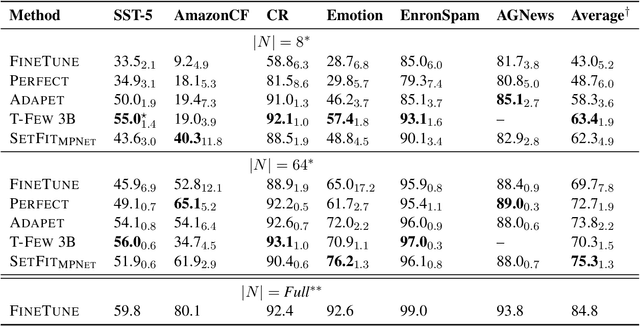
Recent few-shot methods, such as parameter-efficient fine-tuning (PEFT) and pattern exploiting training (PET), have achieved impressive results in label-scarce settings. However, they are difficult to employ since they are subject to high variability from manually crafted prompts, and typically require billion-parameter language models to achieve high accuracy. To address these shortcomings, we propose SetFit (Sentence Transformer Fine-tuning), an efficient and prompt-free framework for few-shot fine-tuning of Sentence Transformers (ST). SetFit works by first fine-tuning a pretrained ST on a small number of text pairs, in a contrastive Siamese manner. The resulting model is then used to generate rich text embeddings, which are used to train a classification head. This simple framework requires no prompts or verbalizers, and achieves high accuracy with orders of magnitude less parameters than existing techniques. Our experiments show that SetFit obtains comparable results with PEFT and PET techniques, while being an order of magnitude faster to train. We also show that SetFit can be applied in multilingual settings by simply switching the ST body. Our code is available at https://github.com/huggingface/setfit and our datasets at https://huggingface.co/setfit .