 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLarge Vision-Language Models for Knowledge-Grounded Data Annotation of Memes
Jan 23, 2025Memes have emerged as a powerful form of communication, integrating visual and textual elements to convey humor, satire, and cultural messages. Existing research has focused primarily on aspects such as emotion classification, meme generation, propagation, interpretation, figurative language, and sociolinguistics, but has often overlooked deeper meme comprehension and meme-text retrieval. To address these gaps, this study introduces ClassicMemes-50-templates (CM50), a large-scale dataset consisting of over 33,000 memes, centered around 50 popular meme templates. We also present an automated knowledge-grounded annotation pipeline leveraging large vision-language models to produce high-quality image captions, meme captions, and literary device labels overcoming the labor intensive demands of manual annotation. Additionally, we propose a meme-text retrieval CLIP model (mtrCLIP) that utilizes cross-modal embedding to enhance meme analysis, significantly improving retrieval performance. Our contributions include:(1) a novel dataset for large-scale meme study, (2) a scalable meme annotation framework, and (3) a fine-tuned CLIP for meme-text retrieval, all aimed at advancing the understanding and analysis of memes at scale.
A Template Is All You Meme
Nov 11, 2023Memes are a modern form of communication and meme templates possess a base semantics that is customizable by whomever posts it on social media. Machine learning systems struggle with memes, which is likely due to such systems having insufficient context to understand memes, as there is more to memes than the obvious image and text. Here, to aid understanding of memes, we release a knowledge base of memes and information found on www.knowyourmeme.com, which we call the Know Your Meme Knowledge Base (KYMKB), composed of more than 54,000 images. The KYMKB includes popular meme templates, examples of each template, and detailed information about the template. We hypothesize that meme templates can be used to inject models with the context missing from previous approaches. To test our hypothesis, we create a non-parametric majority-based classifier, which we call Template-Label Counter (TLC). We find TLC more effective than or competitive with fine-tuned baselines. To demonstrate the power of meme templates and the value of both our knowledge base and method, we conduct thorough classification experiments and exploratory data analysis in the context of five meme analysis tasks.
Prompt, Condition, and Generate: Classification of Unsupported Claims with In-Context Learning
Sep 19, 2023



Unsupported and unfalsifiable claims we encounter in our daily lives can influence our view of the world. Characterizing, summarizing, and -- more generally -- making sense of such claims, however, can be challenging. In this work, we focus on fine-grained debate topics and formulate a new task of distilling, from such claims, a countable set of narratives. We present a crowdsourced dataset of 12 controversial topics, comprising more than 120k arguments, claims, and comments from heterogeneous sources, each annotated with a narrative label. We further investigate how large language models (LLMs) can be used to synthesise claims using In-Context Learning. We find that generated claims with supported evidence can be used to improve the performance of narrative classification models and, additionally, that the same model can infer the stance and aspect using a few training examples. Such a model can be useful in applications which rely on narratives , e.g. fact-checking.
Assessing Neural Network Robustness via Adversarial Pivotal Tuning
Nov 17, 2022The ability to assess the robustness of image classifiers to a diverse set of manipulations is essential to their deployment in the real world. Recently, semantic manipulations of real images have been considered for this purpose, as they may not arise using standard adversarial settings. However, such semantic manipulations are often limited to style, color or attribute changes. While expressive, these manipulations do not consider the full capacity of a pretrained generator to affect adversarial image manipulations. In this work, we aim at leveraging the full capacity of a pretrained image generator to generate highly detailed, diverse and photorealistic image manipulations. Inspired by recent GAN-based image inversion methods, we propose a method called Adversarial Pivotal Tuning (APT). APT first finds a pivot latent space input to a pretrained generator that best reconstructs an input image. It then adjusts the weights of the generator to create small, but semantic, manipulations which fool a pretrained classifier. Crucially, APT changes both the input and the weights of the pretrained generator, while preserving its expressive latent editing capability, thus allowing the use of its full capacity in creating semantic adversarial manipulations. We demonstrate that APT generates a variety of semantic image manipulations, which preserve the input image class, but which fool a variety of pretrained classifiers. We further demonstrate that classifiers trained to be robust to other robustness benchmarks, are not robust to our generated manipulations and propose an approach to improve the robustness towards our generated manipulations. Code available at: https://captaine.github.io/apt/
Volumetric Disentanglement for 3D Scene Manipulation
Jun 06, 2022
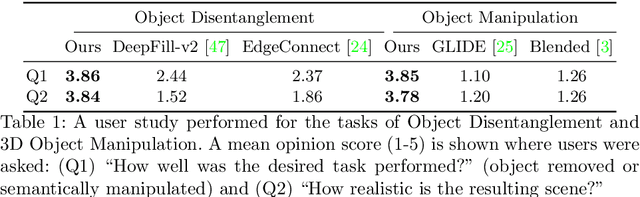
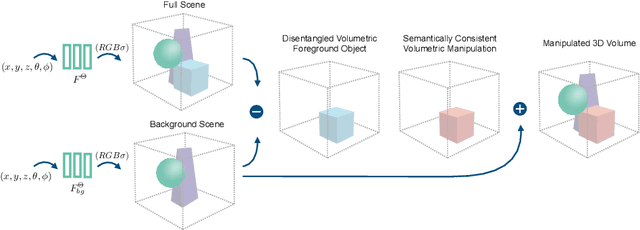
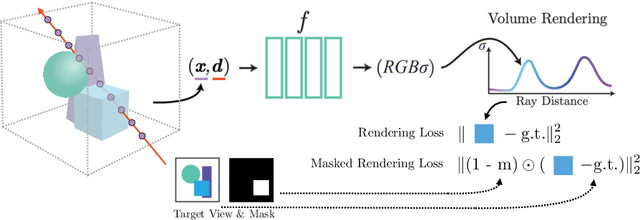
Recently, advances in differential volumetric rendering enabled significant breakthroughs in the photo-realistic and fine-detailed reconstruction of complex 3D scenes, which is key for many virtual reality applications. However, in the context of augmented reality, one may also wish to effect semantic manipulations or augmentations of objects within a scene. To this end, we propose a volumetric framework for (i) disentangling or separating, the volumetric representation of a given foreground object from the background, and (ii) semantically manipulating the foreground object, as well as the background. Our framework takes as input a set of 2D masks specifying the desired foreground object for training views, together with the associated 2D views and poses, and produces a foreground-background disentanglement that respects the surrounding illumination, reflections, and partial occlusions, which can be applied to both training and novel views. Our method enables the separate control of pixel color and depth as well as 3D similarity transformations of both the foreground and background objects. We subsequently demonstrate the applicability of our framework on a number of downstream manipulation tasks including object camouflage, non-negative 3D object inpainting, 3D object translation, 3D object inpainting, and 3D text-based object manipulation. Full results are given in our project webpage at https://sagiebenaim.github.io/volumetric-disentanglement/
Synthesize, Execute and Debug: Learning to Repair for Neural Program Synthesis
Jul 16, 2020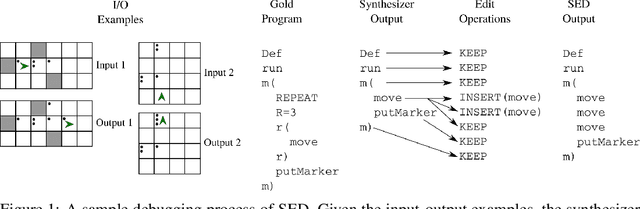

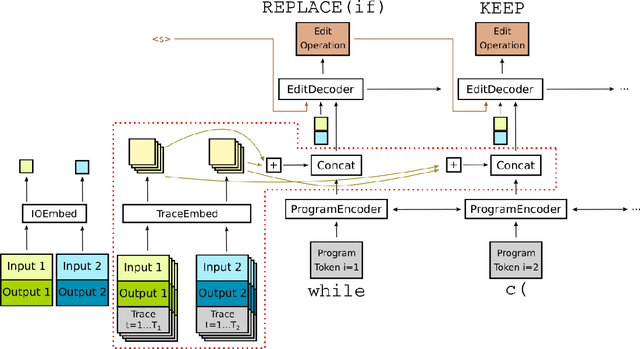
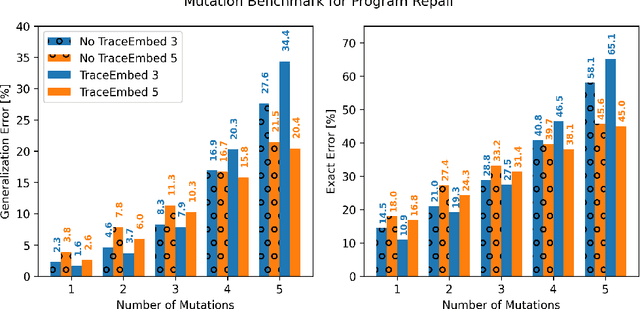
The use of deep learning techniques has achieved significant progress for program synthesis from input-output examples. However, when the program semantics become more complex, it still remains a challenge to synthesize programs consistent with the specification. In this work, we propose SED, a neural program generation framework that incorporates synthesis, execution, and debugging stages. Instead of purely relying on the neural program synthesizer to generate the final program, SED first produces initial programs using the neural program synthesizer component, then utilizes a neural program debugger to iteratively repair the generated programs. The integration of the debugger component enables SED to modify the programs based on the execution results and specification, which resembles the coding process of human programmers. On Karel, a challenging input-output program synthesis benchmark, SED reduces the error rate of the neural program synthesizer itself by at least 7.5%, and outperforms the standard beam search for decoding.
Autoencoding undirected molecular graphs with neural networks
Nov 26, 2019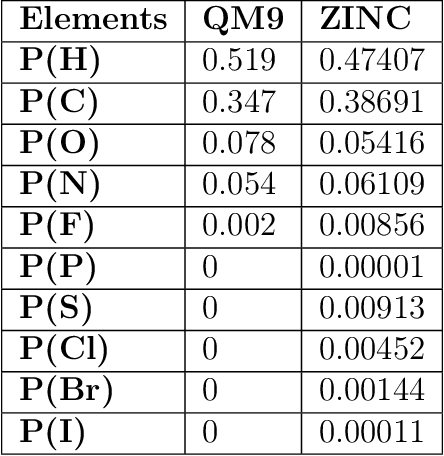
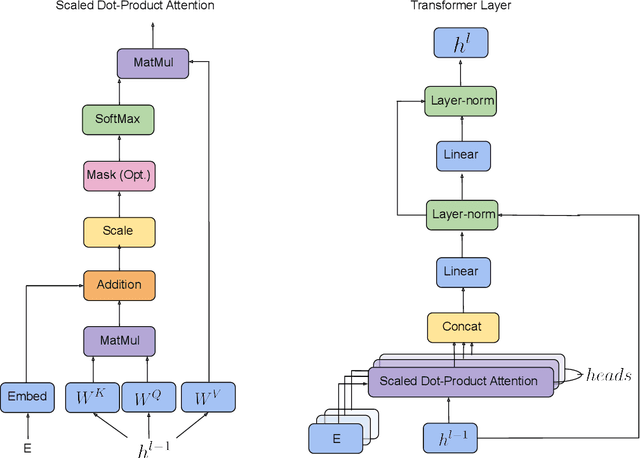

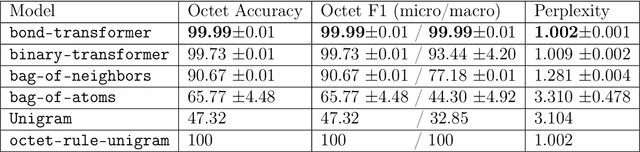
We propose a machine learning model, inspired by language modeling from natural language processing, which can automatically correct molecules in discrete representations using a structure rule learned from a collection of undirected molecular graphs. Using discrete representations of molecules allows cheap, fast, and coarse grained insights. We introduce an adaption on a modern neural network architecture, the Transformer, which can learn relationships between atoms and bonds. The algorithm thereby solves the unsupervised task of recovering partially observed molecules represented as undirected graphs. This is to our knowledge, the first work that can automatically learn any discrete molecular structure rule with input exclusively consisting of a training set of molecules. In this work the neural network successfully approximates the octet rule, relations in hypervalent molecules and ions when trained on the ZINC and QM9 dataset. These results provides encouraging evidence that neural networks can learn advanced molecular structure rules and dataset specific properties, as the transformer surpasses a strong octet-rule baseline.