 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMMEarth-Bench: Global Model Adaptation via Multimodal Test-Time Training
Feb 06, 2026Recent research in geospatial machine learning has demonstrated that models pretrained with self-supervised learning on Earth observation data can perform well on downstream tasks with limited training data. However, most of the existing geospatial benchmark datasets have few data modalities and poor global representation, limiting the ability to evaluate multimodal pretrained models at global scales. To fill this gap, we introduce MMEarth-Bench, a collection of five new multimodal environmental tasks with 12 modalities, globally distributed data, and both in- and out-of-distribution test splits. We benchmark a diverse set of pretrained models and find that while (multimodal) pretraining tends to improve model robustness in limited data settings, geographic generalization abilities remain poor. In order to facilitate model adaptation to new downstream tasks and geographic domains, we propose a model-agnostic method for test-time training with multimodal reconstruction (TTT-MMR) that uses all the modalities available at test time as auxiliary tasks, regardless of whether a pretrained model accepts them as input. Our method improves model performance on both the random and geographic test splits, and geographic batching leads to a good trade-off between regularization and specialization during TTT. Our dataset, code, and visualization tool are linked from the project page at lgordon99.github.io/mmearth-bench.
RAIGen: Rare Attribute Identification in Text-to-Image Generative Models
Feb 06, 2026Text-to-image diffusion models achieve impressive generation quality but inherit and amplify training-data biases, skewing coverage of semantic attributes. Prior work addresses this in two ways. Closed-set approaches mitigate biases in predefined fairness categories (e.g., gender, race), assuming socially salient minority attributes are known a priori. Open-set approaches frame the task as bias identification, highlighting majority attributes that dominate outputs. Both overlook a complementary task: uncovering rare or minority features underrepresented in the data distribution (social, cultural, or stylistic) yet still encoded in model representations. We introduce RAIGen, the first framework, to our knowledge, for un-supervised rare-attribute discovery in diffusion models. RAIGen leverages Matryoshka Sparse Autoencoders and a novel minority metric combining neuron activation frequency with semantic distinctiveness to identify interpretable neurons whose top-activating images reveal underrepresented attributes. Experiments show RAIGen discovers attributes beyond fixed fairness categories in Stable Diffusion, scales to larger models such as SDXL, supports systematic auditing across architectures, and enables targeted amplification of rare attributes during generation.
Thinking in Frames: How Visual Context and Test-Time Scaling Empower Video Reasoning
Jan 28, 2026Vision-Language Models have excelled at textual reasoning, but they often struggle with fine-grained spatial understanding and continuous action planning, failing to simulate the dynamics required for complex visual reasoning. In this work, we formulate visual reasoning by means of video generation models, positing that generated frames can act as intermediate reasoning steps between initial states and solutions. We evaluate their capacity in two distinct regimes: Maze Navigation for sequential discrete planning with low visual change and Tangram Puzzle for continuous manipulation with high visual change. Our experiments reveal three critical insights: (1) Robust Zero-Shot Generalization: In both tasks, the model demonstrates strong performance on unseen data distributions without specific finetuning. (2) Visual Context: The model effectively uses visual context as explicit control, such as agent icons and tangram shapes, enabling it to maintain high visual consistency and adapt its planning capability robustly to unseen patterns. (3) Visual Test-Time Scaling: We observe a test-time scaling law in sequential planning; increasing the generated video length (visual inference budget) empowers better zero-shot generalization to spatially and temporally complex paths. These findings suggest that video generation is not merely a media tool, but a scalable, generalizable paradigm for visual reasoning.
SuperF: Neural Implicit Fields for Multi-Image Super-Resolution
Dec 09, 2025High-resolution imagery is often hindered by limitations in sensor technology, atmospheric conditions, and costs. Such challenges occur in satellite remote sensing, but also with handheld cameras, such as our smartphones. Hence, super-resolution aims to enhance the image resolution algorithmically. Since single-image super-resolution requires solving an inverse problem, such methods must exploit strong priors, e.g. learned from high-resolution training data, or be constrained by auxiliary data, e.g. by a high-resolution guide from another modality. While qualitatively pleasing, such approaches often lead to "hallucinated" structures that do not match reality. In contrast, multi-image super-resolution (MISR) aims to improve the (optical) resolution by constraining the super-resolution process with multiple views taken with sub-pixel shifts. Here, we propose SuperF, a test-time optimization approach for MISR that leverages coordinate-based neural networks, also called neural fields. Their ability to represent continuous signals with an implicit neural representation (INR) makes them an ideal fit for the MISR task. The key characteristic of our approach is to share an INR for multiple shifted low-resolution frames and to jointly optimize the frame alignment with the INR. Our approach advances related INR baselines, adopted from burst fusion for layer separation, by directly parameterizing the sub-pixel alignment as optimizable affine transformation parameters and by optimizing via a super-sampled coordinate grid that corresponds to the output resolution. Our experiments yield compelling results on simulated bursts of satellite imagery and ground-level images from handheld cameras, with upsampling factors of up to 8. A key advantage of SuperF is that this approach does not rely on any high-resolution training data.
OneStory: Coherent Multi-Shot Video Generation with Adaptive Memory
Dec 08, 2025
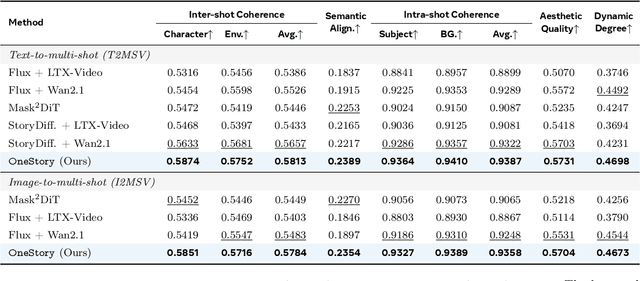
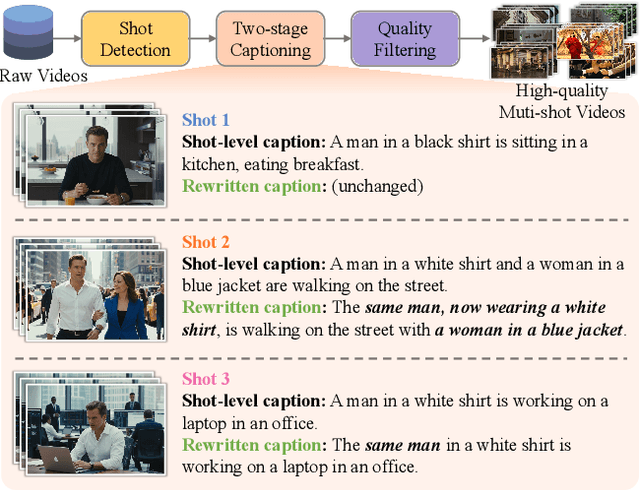

Storytelling in real-world videos often unfolds through multiple shots -- discontinuous yet semantically connected clips that together convey a coherent narrative. However, existing multi-shot video generation (MSV) methods struggle to effectively model long-range cross-shot context, as they rely on limited temporal windows or single keyframe conditioning, leading to degraded performance under complex narratives. In this work, we propose OneStory, enabling global yet compact cross-shot context modeling for consistent and scalable narrative generation. OneStory reformulates MSV as a next-shot generation task, enabling autoregressive shot synthesis while leveraging pretrained image-to-video (I2V) models for strong visual conditioning. We introduce two key modules: a Frame Selection module that constructs a semantically-relevant global memory based on informative frames from prior shots, and an Adaptive Conditioner that performs importance-guided patchification to generate compact context for direct conditioning. We further curate a high-quality multi-shot dataset with referential captions to mirror real-world storytelling patterns, and design effective training strategies under the next-shot paradigm. Finetuned from a pretrained I2V model on our curated 60K dataset, OneStory achieves state-of-the-art narrative coherence across diverse and complex scenes in both text- and image-conditioned settings, enabling controllable and immersive long-form video storytelling.
Stitch: Training-Free Position Control in Multimodal Diffusion Transformers
Sep 30, 2025Text-to-Image (T2I) generation models have advanced rapidly in recent years, but accurately capturing spatial relationships like "above" or "to the right of" poses a persistent challenge. Earlier methods improved spatial relationship following with external position control. However, as architectures evolved to enhance image quality, these techniques became incompatible with modern models. We propose Stitch, a training-free method for incorporating external position control into Multi-Modal Diffusion Transformers (MMDiT) via automatically-generated bounding boxes. Stitch produces images that are both spatially accurate and visually appealing by generating individual objects within designated bounding boxes and seamlessly stitching them together. We find that targeted attention heads capture the information necessary to isolate and cut out individual objects mid-generation, without needing to fully complete the image. We evaluate Stitch on PosEval, our benchmark for position-based T2I generation. Featuring five new tasks that extend the concept of Position beyond the basic GenEval task, PosEval demonstrates that even top models still have significant room for improvement in position-based generation. Tested on Qwen-Image, FLUX, and SD3.5, Stitch consistently enhances base models, even improving FLUX by 218% on GenEval's Position task and by 206% on PosEval. Stitch achieves state-of-the-art results with Qwen-Image on PosEval, improving over previous models by 54%, all accomplished while integrating position control into leading models training-free. Code is available at https://github.com/ExplainableML/Stitch.
RespoDiff: Dual-Module Bottleneck Transformation for Responsible & Faithful T2I Generation
Sep 18, 2025The rapid advancement of diffusion models has enabled high-fidelity and semantically rich text-to-image generation; however, ensuring fairness and safety remains an open challenge. Existing methods typically improve fairness and safety at the expense of semantic fidelity and image quality. In this work, we propose RespoDiff, a novel framework for responsible text-to-image generation that incorporates a dual-module transformation on the intermediate bottleneck representations of diffusion models. Our approach introduces two distinct learnable modules: one focused on capturing and enforcing responsible concepts, such as fairness and safety, and the other dedicated to maintaining semantic alignment with neutral prompts. To facilitate the dual learning process, we introduce a novel score-matching objective that enables effective coordination between the modules. Our method outperforms state-of-the-art methods in responsible generation by ensuring semantic alignment while optimizing both objectives without compromising image fidelity. Our approach improves responsible and semantically coherent generation by 20% across diverse, unseen prompts. Moreover, it integrates seamlessly into large-scale models like SDXL, enhancing fairness and safety. Code will be released upon acceptance.
Is Meta-Learning Out? Rethinking Unsupervised Few-Shot Classification with Limited Entropy
Sep 16, 2025



Meta-learning is a powerful paradigm for tackling few-shot tasks. However, recent studies indicate that models trained with the whole-class training strategy can achieve comparable performance to those trained with meta-learning in few-shot classification tasks. To demonstrate the value of meta-learning, we establish an entropy-limited supervised setting for fair comparisons. Through both theoretical analysis and experimental validation, we establish that meta-learning has a tighter generalization bound compared to whole-class training. We unravel that meta-learning is more efficient with limited entropy and is more robust to label noise and heterogeneous tasks, making it well-suited for unsupervised tasks. Based on these insights, We propose MINO, a meta-learning framework designed to enhance unsupervised performance. MINO utilizes the adaptive clustering algorithm DBSCAN with a dynamic head for unsupervised task construction and a stability-based meta-scaler for robustness against label noise. Extensive experiments confirm its effectiveness in multiple unsupervised few-shot and zero-shot tasks.
Cultural Evaluations of Vision-Language Models Have a Lot to Learn from Cultural Theory
May 28, 2025Modern vision-language models (VLMs) often fail at cultural competency evaluations and benchmarks. Given the diversity of applications built upon VLMs, there is renewed interest in understanding how they encode cultural nuances. While individual aspects of this problem have been studied, we still lack a comprehensive framework for systematically identifying and annotating the nuanced cultural dimensions present in images for VLMs. This position paper argues that foundational methodologies from visual culture studies (cultural studies, semiotics, and visual studies) are necessary for cultural analysis of images. Building upon this review, we propose a set of five frameworks, corresponding to cultural dimensions, that must be considered for a more complete analysis of the cultural competencies of VLMs.
RAVENEA: A Benchmark for Multimodal Retrieval-Augmented Visual Culture Understanding
May 20, 2025As vision-language models (VLMs) become increasingly integrated into daily life, the need for accurate visual culture understanding is becoming critical. Yet, these models frequently fall short in interpreting cultural nuances effectively. Prior work has demonstrated the effectiveness of retrieval-augmented generation (RAG) in enhancing cultural understanding in text-only settings, while its application in multimodal scenarios remains underexplored. To bridge this gap, we introduce RAVENEA (Retrieval-Augmented Visual culturE uNdErstAnding), a new benchmark designed to advance visual culture understanding through retrieval, focusing on two tasks: culture-focused visual question answering (cVQA) and culture-informed image captioning (cIC). RAVENEA extends existing datasets by integrating over 10,000 Wikipedia documents curated and ranked by human annotators. With RAVENEA, we train and evaluate seven multimodal retrievers for each image query, and measure the downstream impact of retrieval-augmented inputs across fourteen state-of-the-art VLMs. Our results show that lightweight VLMs, when augmented with culture-aware retrieval, outperform their non-augmented counterparts (by at least 3.2% absolute on cVQA and 6.2% absolute on cIC). This highlights the value of retrieval-augmented methods and culturally inclusive benchmarks for multimodal understanding.