 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePersonalizing Text-to-Image Generation to Individual Taste
Apr 08, 2026Modern text-to-image (T2I) models generate high-fidelity visuals but remain indifferent to individual user preferences. While existing reward models optimize for "average" human appeal, they fail to capture the inherent subjectivity of aesthetic judgment. In this work, we introduce a novel dataset and predictive framework, called PAMELA, designed to model personalized image evaluations. Our dataset comprises 70,000 ratings across 5,000 diverse images generated by state-of-the-art models (Flux 2 and Nano Banana). Each image is evaluated by 15 unique users, providing a rich distribution of subjective preferences across domains such as art, design, fashion, and cinematic photography. Leveraging this data, we propose a personalized reward model trained jointly on our high-quality annotations and existing aesthetic assessment subsets. We demonstrate that our model predicts individual liking with higher accuracy than the majority of current state-of-the-art methods predict population-level preferences. Using our personalized predictor, we demonstrate how simple prompt optimization methods can be used to steer generations towards individual user preferences. Our results highlight the importance of data quality and personalization to handle the subjectivity of user preferences. We release our dataset and model to facilitate standardized research in personalized T2I alignment and subjective visual quality assessment.
It's Never Too Late: Noise Optimization for Collapse Recovery in Trained Diffusion Models
Dec 31, 2025Contemporary text-to-image models exhibit a surprising degree of mode collapse, as can be seen when sampling several images given the same text prompt. While previous work has attempted to address this issue by steering the model using guidance mechanisms, or by generating a large pool of candidates and refining them, in this work we take a different direction and aim for diversity in generations via noise optimization. Specifically, we show that a simple noise optimization objective can mitigate mode collapse while preserving the fidelity of the base model. We also analyze the frequency characteristics of the noise and show that alternative noise initializations with different frequency profiles can improve both optimization and search. Our experiments demonstrate that noise optimization yields superior results in terms of generation quality and variety.
Road Obstacle Video Segmentation
Sep 16, 2025With the growing deployment of autonomous driving agents, the detection and segmentation of road obstacles have become critical to ensure safe autonomous navigation. However, existing road-obstacle segmentation methods are applied on individual frames, overlooking the temporal nature of the problem, leading to inconsistent prediction maps between consecutive frames. In this work, we demonstrate that the road-obstacle segmentation task is inherently temporal, since the segmentation maps for consecutive frames are strongly correlated. To address this, we curate and adapt four evaluation benchmarks for road-obstacle video segmentation and evaluate 11 state-of-the-art image- and video-based segmentation methods on these benchmarks. Moreover, we introduce two strong baseline methods based on vision foundation models. Our approach establishes a new state-of-the-art in road-obstacle video segmentation for long-range video sequences, providing valuable insights and direction for future research.
Noise Hypernetworks: Amortizing Test-Time Compute in Diffusion Models
Aug 13, 2025The new paradigm of test-time scaling has yielded remarkable breakthroughs in Large Language Models (LLMs) (e.g. reasoning models) and in generative vision models, allowing models to allocate additional computation during inference to effectively tackle increasingly complex problems. Despite the improvements of this approach, an important limitation emerges: the substantial increase in computation time makes the process slow and impractical for many applications. Given the success of this paradigm and its growing usage, we seek to preserve its benefits while eschewing the inference overhead. In this work we propose one solution to the critical problem of integrating test-time scaling knowledge into a model during post-training. Specifically, we replace reward guided test-time noise optimization in diffusion models with a Noise Hypernetwork that modulates initial input noise. We propose a theoretically grounded framework for learning this reward-tilted distribution for distilled generators, through a tractable noise-space objective that maintains fidelity to the base model while optimizing for desired characteristics. We show that our approach recovers a substantial portion of the quality gains from explicit test-time optimization at a fraction of the computational cost. Code is available at https://github.com/ExplainableML/HyperNoise
A Good CREPE needs more than just Sugar: Investigating Biases in Compositional Vision-Language Benchmarks
Jun 09, 2025



We investigate 17 benchmarks (e.g. SugarCREPE, VALSE) commonly used for measuring compositional understanding capabilities of vision-language models (VLMs). We scrutinize design choices in their construction, including data source (e.g. MS-COCO) and curation procedures (e.g. constructing negative images/captions), uncovering several inherent biases across most benchmarks. We find that blind heuristics (e.g. token-length, log-likelihood under a language model) perform on par with CLIP models, indicating that these benchmarks do not effectively measure compositional understanding. We demonstrate that the underlying factor is a distribution asymmetry between positive and negative images/captions, induced by the benchmark construction procedures. To mitigate these issues, we provide a few key recommendations for constructing more robust vision-language compositional understanding benchmarks, that would be less prone to such simple attacks.
Concept-Guided Interpretability via Neural Chunking
May 16, 2025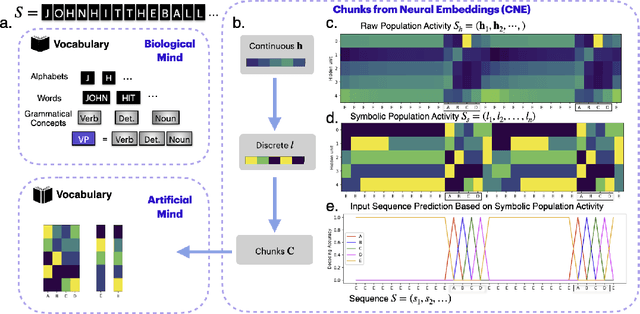
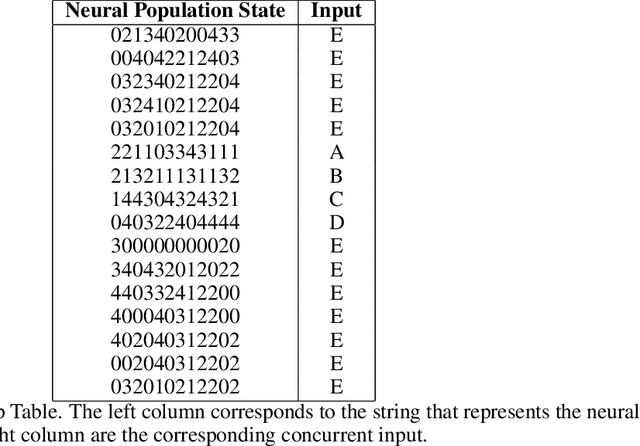
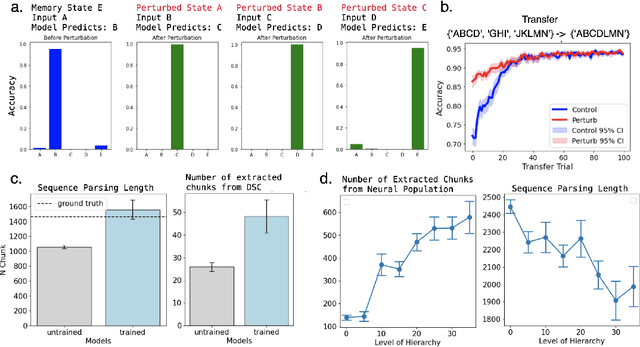
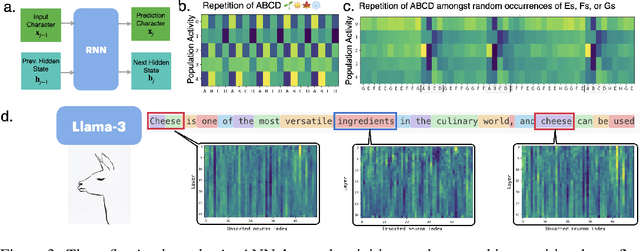
Neural networks are often black boxes, reflecting the significant challenge of understanding their internal workings. We propose a different perspective that challenges the prevailing view: rather than being inscrutable, neural networks exhibit patterns in their raw population activity that mirror regularities in the training data. We refer to this as the Reflection Hypothesis and provide evidence for this phenomenon in both simple recurrent neural networks (RNNs) and complex large language models (LLMs). Building on this insight, we propose to leverage cognitively-inspired methods of chunking to segment high-dimensional neural population dynamics into interpretable units that reflect underlying concepts. We propose three methods to extract these emerging entities, complementing each other based on label availability and dimensionality. Discrete sequence chunking (DSC) creates a dictionary of entities; population averaging (PA) extracts recurring entities that correspond to known labels; and unsupervised chunk discovery (UCD) can be used when labels are absent. We demonstrate the effectiveness of these methods in extracting entities across varying model sizes, ranging from inducing compositionality in RNNs to uncovering recurring neural population states in large models with diverse architectures, and illustrate their advantage over other methods. Throughout, we observe a robust correspondence between the extracted entities and concrete or abstract concepts. Artificially inducing the extracted entities in neural populations effectively alters the network's generation of associated concepts. Our work points to a new direction for interpretability, one that harnesses both cognitive principles and the structure of naturalistic data to reveal the hidden computations of complex learning systems, gradually transforming them from black boxes into systems we can begin to understand.
Sparse Autoencoders Learn Monosemantic Features in Vision-Language Models
Apr 03, 2025Sparse Autoencoders (SAEs) have recently been shown to enhance interpretability and steerability in Large Language Models (LLMs). In this work, we extend the application of SAEs to Vision-Language Models (VLMs), such as CLIP, and introduce a comprehensive framework for evaluating monosemanticity in vision representations. Our experimental results reveal that SAEs trained on VLMs significantly enhance the monosemanticity of individual neurons while also exhibiting hierarchical representations that align well with expert-defined structures (e.g., iNaturalist taxonomy). Most notably, we demonstrate that applying SAEs to intervene on a CLIP vision encoder, directly steer output from multimodal LLMs (e.g., LLaVA) without any modifications to the underlying model. These findings emphasize the practicality and efficacy of SAEs as an unsupervised approach for enhancing both the interpretability and control of VLMs.
Post-hoc Probabilistic Vision-Language Models
Dec 08, 2024



Vision-language models (VLMs), such as CLIP and SigLIP, have found remarkable success in classification, retrieval, and generative tasks. For this, VLMs deterministically map images and text descriptions to a joint latent space in which their similarity is assessed using the cosine similarity. However, a deterministic mapping of inputs fails to capture uncertainties over concepts arising from domain shifts when used in downstream tasks. In this work, we propose post-hoc uncertainty estimation in VLMs that does not require additional training. Our method leverages a Bayesian posterior approximation over the last layers in VLMs and analytically quantifies uncertainties over cosine similarities. We demonstrate its effectiveness for uncertainty quantification and support set selection in active learning. Compared to baselines, we obtain improved and well-calibrated predictive uncertainties, interpretable uncertainty estimates, and sample-efficient active learning. Our results show promise for safety-critical applications of large-scale models.
Scalable Ranked Preference Optimization for Text-to-Image Generation
Oct 23, 2024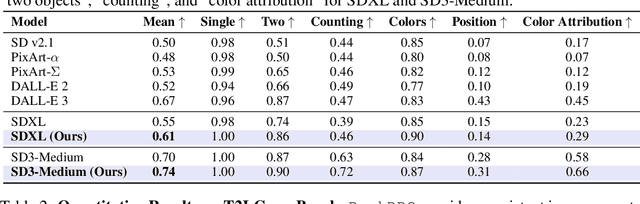
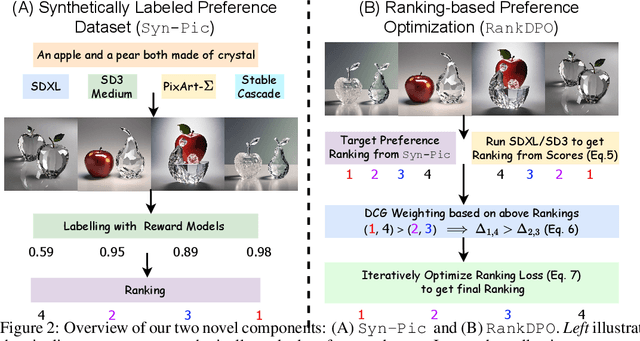

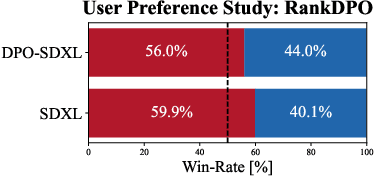
Direct Preference Optimization (DPO) has emerged as a powerful approach to align text-to-image (T2I) models with human feedback. Unfortunately, successful application of DPO to T2I models requires a huge amount of resources to collect and label large-scale datasets, e.g., millions of generated paired images annotated with human preferences. In addition, these human preference datasets can get outdated quickly as the rapid improvements of T2I models lead to higher quality images. In this work, we investigate a scalable approach for collecting large-scale and fully synthetic datasets for DPO training. Specifically, the preferences for paired images are generated using a pre-trained reward function, eliminating the need for involving humans in the annotation process, greatly improving the dataset collection efficiency. Moreover, we demonstrate that such datasets allow averaging predictions across multiple models and collecting ranked preferences as opposed to pairwise preferences. Furthermore, we introduce RankDPO to enhance DPO-based methods using the ranking feedback. Applying RankDPO on SDXL and SD3-Medium models with our synthetically generated preference dataset ``Syn-Pic'' improves both prompt-following (on benchmarks like T2I-Compbench, GenEval, and DPG-Bench) and visual quality (through user studies). This pipeline presents a practical and scalable solution to develop better preference datasets to enhance the performance of text-to-image models.
EgoCVR: An Egocentric Benchmark for Fine-Grained Composed Video Retrieval
Jul 23, 2024In Composed Video Retrieval, a video and a textual description which modifies the video content are provided as inputs to the model. The aim is to retrieve the relevant video with the modified content from a database of videos. In this challenging task, the first step is to acquire large-scale training datasets and collect high-quality benchmarks for evaluation. In this work, we introduce EgoCVR, a new evaluation benchmark for fine-grained Composed Video Retrieval using large-scale egocentric video datasets. EgoCVR consists of 2,295 queries that specifically focus on high-quality temporal video understanding. We find that existing Composed Video Retrieval frameworks do not achieve the necessary high-quality temporal video understanding for this task. To address this shortcoming, we adapt a simple training-free method, propose a generic re-ranking framework for Composed Video Retrieval, and demonstrate that this achieves strong results on EgoCVR. Our code and benchmark are freely available at https://github.com/ExplainableML/EgoCVR.