 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVideo-MSR: Benchmarking Multi-hop Spatial Reasoning Capabilities of MLLMs
Jan 14, 2026Spatial reasoning has emerged as a critical capability for Multimodal Large Language Models (MLLMs), drawing increasing attention and rapid advancement. However, existing benchmarks primarily focus on single-step perception-to-judgment tasks, leaving scenarios requiring complex visual-spatial logical chains significantly underexplored. To bridge this gap, we introduce Video-MSR, the first benchmark specifically designed to evaluate Multi-hop Spatial Reasoning (MSR) in dynamic video scenarios. Video-MSR systematically probes MSR capabilities through four distinct tasks: Constrained Localization, Chain-based Reference Retrieval, Route Planning, and Counterfactual Physical Deduction. Our benchmark comprises 3,052 high-quality video instances with 4,993 question-answer pairs, constructed via a scalable, visually-grounded pipeline combining advanced model generation with rigorous human verification. Through a comprehensive evaluation of 20 state-of-the-art MLLMs, we uncover significant limitations, revealing that while models demonstrate proficiency in surface-level perception, they exhibit distinct performance drops in MSR tasks, frequently suffering from spatial disorientation and hallucination during multi-step deductions. To mitigate these shortcomings and empower models with stronger MSR capabilities, we further curate MSR-9K, a specialized instruction-tuning dataset, and fine-tune Qwen-VL, achieving a +7.82% absolute improvement on Video-MSR. Our results underscore the efficacy of multi-hop spatial instruction data and establish Video-MSR as a vital foundation for future research. The code and data will be available at https://github.com/ruiz-nju/Video-MSR.
Concept-Guided Interpretability via Neural Chunking
May 16, 2025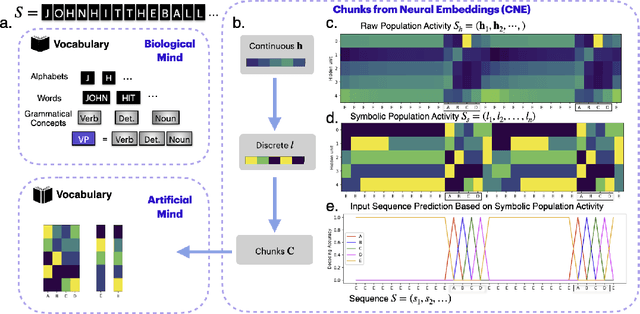
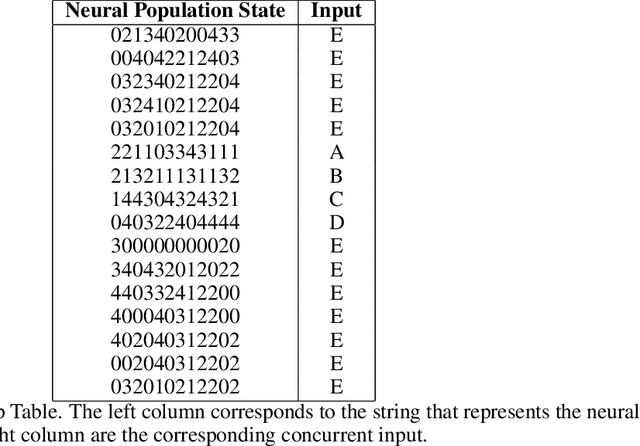
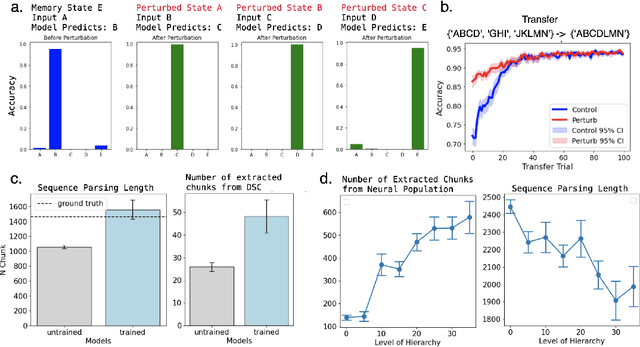
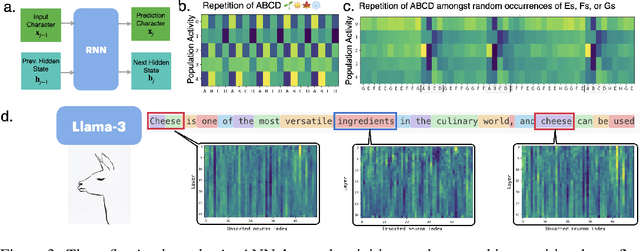
Neural networks are often black boxes, reflecting the significant challenge of understanding their internal workings. We propose a different perspective that challenges the prevailing view: rather than being inscrutable, neural networks exhibit patterns in their raw population activity that mirror regularities in the training data. We refer to this as the Reflection Hypothesis and provide evidence for this phenomenon in both simple recurrent neural networks (RNNs) and complex large language models (LLMs). Building on this insight, we propose to leverage cognitively-inspired methods of chunking to segment high-dimensional neural population dynamics into interpretable units that reflect underlying concepts. We propose three methods to extract these emerging entities, complementing each other based on label availability and dimensionality. Discrete sequence chunking (DSC) creates a dictionary of entities; population averaging (PA) extracts recurring entities that correspond to known labels; and unsupervised chunk discovery (UCD) can be used when labels are absent. We demonstrate the effectiveness of these methods in extracting entities across varying model sizes, ranging from inducing compositionality in RNNs to uncovering recurring neural population states in large models with diverse architectures, and illustrate their advantage over other methods. Throughout, we observe a robust correspondence between the extracted entities and concrete or abstract concepts. Artificially inducing the extracted entities in neural populations effectively alters the network's generation of associated concepts. Our work points to a new direction for interpretability, one that harnesses both cognitive principles and the structure of naturalistic data to reveal the hidden computations of complex learning systems, gradually transforming them from black boxes into systems we can begin to understand.
From Dionysius Emerges Apollo -- Learning Patterns and Abstractions from Perceptual Sequences
Mar 14, 2025Cognition swiftly breaks high-dimensional sensory streams into familiar parts and uncovers their relations. Why do structures emerge, and how do they enable learning, generalization, and prediction? What computational principles underlie this core aspect of perception and intelligence? A sensory stream, simplified, is a one-dimensional sequence. In learning such sequences, we naturally segment them into parts -- a process known as chunking. In the first project, I investigated factors influencing chunking in a serial reaction time task and showed that humans adapt to underlying chunks while balancing speed and accuracy. Building on this, I developed models that learn chunks and parse sequences chunk by chunk. Normatively, I proposed chunking as a rational strategy for discovering recurring patterns and nested hierarchies, enabling efficient sequence factorization. Learned chunks serve as reusable primitives for transfer, composition, and mental simulation -- letting the model compose the new from the known. I demonstrated this model's ability to learn hierarchies in single and multi-dimensional sequences and highlighted its utility for unsupervised pattern discovery. The second part moves from concrete to abstract sequences. I taxonomized abstract motifs and examined their role in sequence memory. Behavioral evidence suggests that humans exploit pattern redundancies for compression and transfer. I proposed a non-parametric hierarchical variable model that learns both chunks and abstract variables, uncovering invariant symbolic patterns. I showed its similarity to human learning and compared it to large language models. Taken together, this thesis suggests that chunking and abstraction as simple computational principles enable structured knowledge acquisition in hierarchically organized sequences, from simple to complex, concrete to abstract.
Discovering Chunks in Neural Embeddings for Interpretability
Feb 03, 2025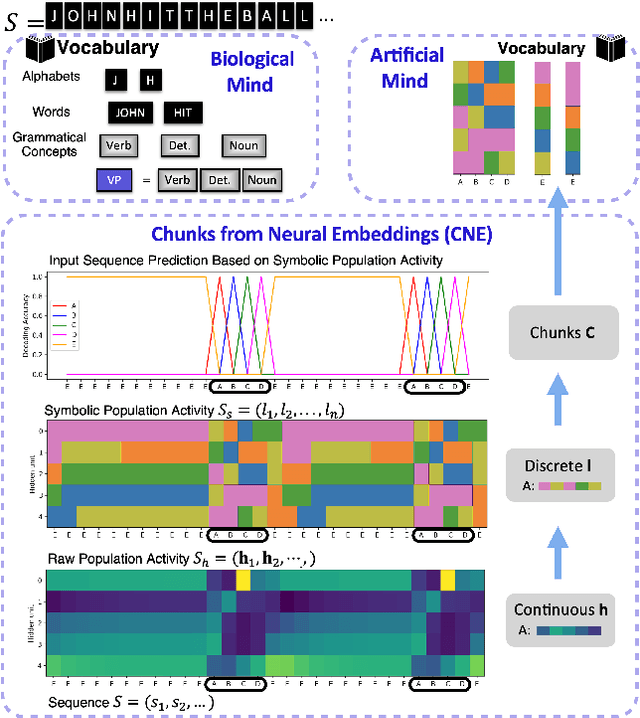

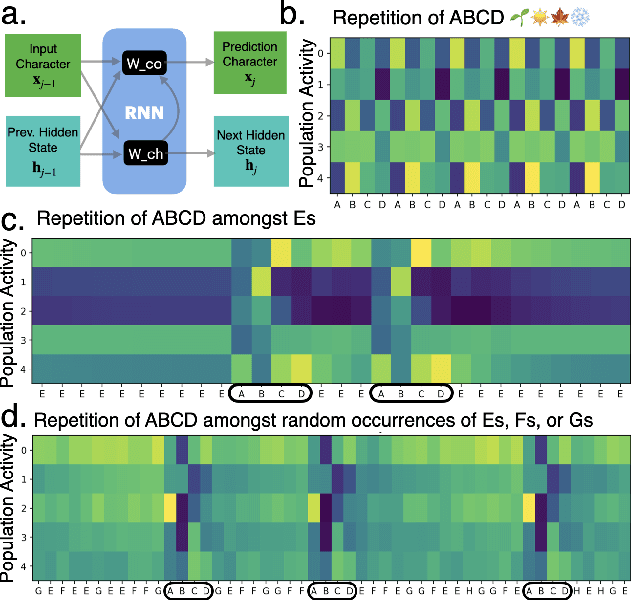
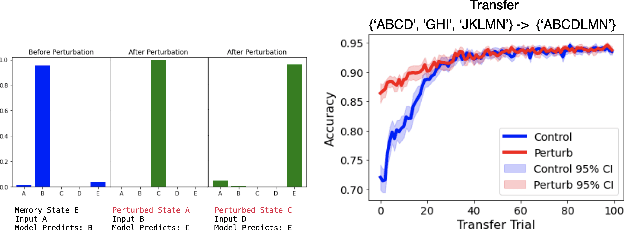
Understanding neural networks is challenging due to their high-dimensional, interacting components. Inspired by human cognition, which processes complex sensory data by chunking it into recurring entities, we propose leveraging this principle to interpret artificial neural population activities. Biological and artificial intelligence share the challenge of learning from structured, naturalistic data, and we hypothesize that the cognitive mechanism of chunking can provide insights into artificial systems. We first demonstrate this concept in recurrent neural networks (RNNs) trained on artificial sequences with imposed regularities, observing that their hidden states reflect these patterns, which can be extracted as a dictionary of chunks that influence network responses. Extending this to large language models (LLMs) like LLaMA, we identify similar recurring embedding states corresponding to concepts in the input, with perturbations to these states activating or inhibiting the associated concepts. By exploring methods to extract dictionaries of identifiable chunks across neural embeddings of varying complexity, our findings introduce a new framework for interpreting neural networks, framing their population activity as structured reflections of the data they process.
Building, Reusing, and Generalizing Abstract Representations from Concrete Sequences
Oct 27, 2024



Humans excel at learning abstract patterns across different sequences, filtering out irrelevant details, and transferring these generalized concepts to new sequences. In contrast, many sequence learning models lack the ability to abstract, which leads to memory inefficiency and poor transfer. We introduce a non-parametric hierarchical variable learning model (HVM) that learns chunks from sequences and abstracts contextually similar chunks as variables. HVM efficiently organizes memory while uncovering abstractions, leading to compact sequence representations. When learning on language datasets such as babyLM, HVM learns a more efficient dictionary than standard compression algorithms such as Lempel-Ziv. In a sequence recall task requiring the acquisition and transfer of variables embedded in sequences, we demonstrate HVM's sequence likelihood correlates with human recall times. In contrast, large language models (LLMs) struggle to transfer abstract variables as effectively as humans. From HVM's adjustable layer of abstraction, we demonstrate that the model realizes a precise trade-off between compression and generalization. Our work offers a cognitive model that captures the learning and transfer of abstract representations in human cognition and differentiates itself from the behavior of large language models.
Centaur: a foundation model of human cognition
Oct 26, 2024



Establishing a unified theory of cognition has been a major goal of psychology. While there have been previous attempts to instantiate such theories by building computational models, we currently do not have one model that captures the human mind in its entirety. Here we introduce Centaur, a computational model that can predict and simulate human behavior in any experiment expressible in natural language. We derived Centaur by finetuning a state-of-the-art language model on a novel, large-scale data set called Psych-101. Psych-101 reaches an unprecedented scale, covering trial-by-trial data from over 60,000 participants performing over 10,000,000 choices in 160 experiments. Centaur not only captures the behavior of held-out participants better than existing cognitive models, but also generalizes to new cover stories, structural task modifications, and entirely new domains. Furthermore, we find that the model's internal representations become more aligned with human neural activity after finetuning. Taken together, Centaur is the first real candidate for a unified model of human cognition. We anticipate that it will have a disruptive impact on the cognitive sciences, challenging the existing paradigm for developing computational models.