 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMIRAGE: Benchmarking and Aligning Multi-Instance Image Editing
Apr 06, 2026Instruction-guided image editing has seen remarkable progress with models like FLUX.2 and Qwen-Image-Edit, yet they still struggle with complex scenarios with multiple similar instances each requiring individual edits. We observe that state-of-the-art models suffer from severe over-editing and spatial misalignment when faced with multiple identical instances and composite instructions. To this end, we introduce a comprehensive benchmark specifically designed to evaluate fine-grained consistency in multi-instance and multi-instruction settings. To address the failures of existing methods observed in our benchmark, we propose Multi-Instance Regional Alignment via Guided Editing (MIRAGE), a training-free framework that enables precise, localized editing. By leveraging a vision-language model to parse complex instructions into regional subsets, MIRAGE employs a multi-branch parallel denoising strategy. This approach injects latent representations of target regions into the global representation space while maintaining background integrity through a reference trajectory. Extensive evaluations on MIRA-Bench and RefEdit-Bench demonstrate that our framework significantly outperforms existing methods in achieving precise instance-level modifications while preserving background consistency. Our benchmark and code are available at https://github.com/ZiqianLiu666/MIRAGE.
Explaining CLIP Zero-shot Predictions Through Concepts
Mar 30, 2026Large-scale vision-language models such as CLIP have achieved remarkable success in zero-shot image recognition, yet their predictions remain largely opaque to human understanding. In contrast, Concept Bottleneck Models provide interpretable intermediate representations by reasoning through human-defined concepts, but they rely on concept supervision and lack the ability to generalize to unseen classes. We introduce EZPC that bridges these two paradigms by explaining CLIP's zero-shot predictions through human-understandable concepts. Our method projects CLIP's joint image-text embeddings into a concept space learned from language descriptions, enabling faithful and transparent explanations without additional supervision. The model learns this projection via a combination of alignment and reconstruction objectives, ensuring that concept activations preserve CLIP's semantic structure while remaining interpretable. Extensive experiments on five benchmark datasets, CIFAR-100, CUB-200-2011, Places365, ImageNet-100, and ImageNet-1k, demonstrate that our approach maintains CLIP's strong zero-shot classification accuracy while providing meaningful concept-level explanations. By grounding open-vocabulary predictions in explicit semantic concepts, our method offers a principled step toward interpretable and trustworthy vision-language models. Code is available at https://github.com/oonat/ezpc.
FINER: MLLMs Hallucinate under Fine-grained Negative Queries
Mar 18, 2026Multimodal large language models (MLLMs) struggle with hallucinations, particularly with fine-grained queries, a challenge underrepresented by existing benchmarks that focus on coarse image-related questions. We introduce FIne-grained NEgative queRies (FINER), alongside two benchmarks: FINER-CompreCap and FINER-DOCCI. Using FINER, we analyze hallucinations across four settings: multi-object, multi-attribute, multi-relation, and ``what'' questions. Our benchmarks reveal that MLLMs hallucinate when fine-grained mismatches co-occur with genuinely present elements in the image. To address this, we propose FINER-Tuning, leveraging Direct Preference Optimization (DPO) on FINER-inspired data. Finetuning four frontier MLLMs with FINER-Tuning yields up to 24.2\% gains (InternVL3.5-14B) on hallucinations from our benchmarks, while simultaneously improving performance on eight existing hallucination suites, and enhancing general multimodal capabilities across six benchmarks. Code, benchmark, and models are available at \href{https://explainableml.github.io/finer-project/}{https://explainableml.github.io/finer-project/}.
Training-free Uncertainty Guidance for Complex Visual Tasks with MLLMs
Oct 01, 2025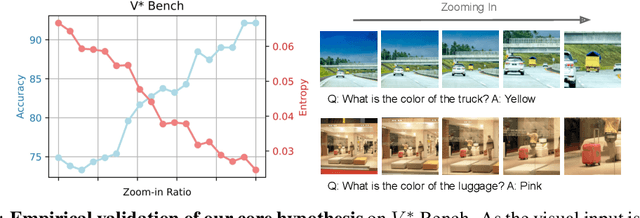
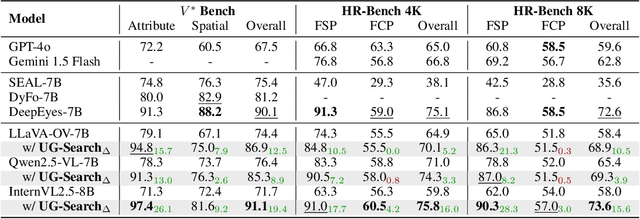
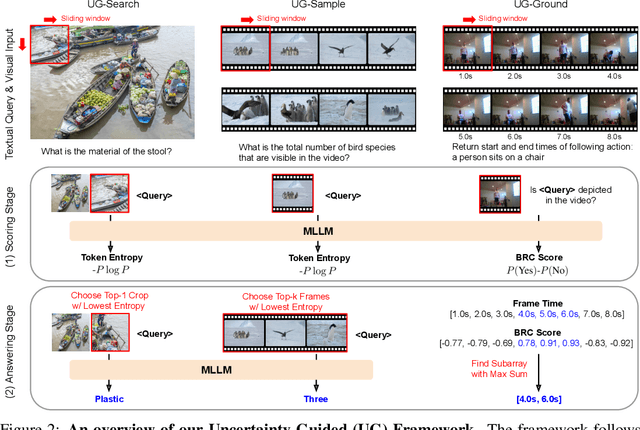
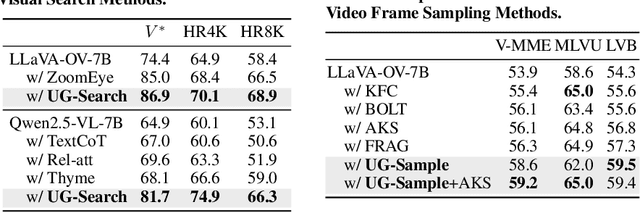
Multimodal Large Language Models (MLLMs) often struggle with fine-grained perception, such as identifying small objects in high-resolution images or finding key moments in long videos. Existing works typically rely on complicated, task-specific fine-tuning, which limits their generalizability and increases model complexity. In this work, we propose an effective, training-free framework that uses an MLLM's intrinsic uncertainty as a proactive guidance signal. Our core insight is that a model's output entropy decreases when presented with relevant visual information. We introduce a unified mechanism that scores candidate visual inputs by response uncertainty, enabling the model to autonomously focus on the most salient data. We apply this simple principle to three complex visual tasks: Visual Search, Long Video Understanding, and Temporal Grounding, allowing off-the-shelf MLLMs to achieve performance competitive with specialized, fine-tuned methods. Our work validates that harnessing intrinsic uncertainty is a powerful, general strategy for enhancing fine-grained multimodal performance.
SUB: Benchmarking CBM Generalization via Synthetic Attribute Substitutions
Jul 31, 2025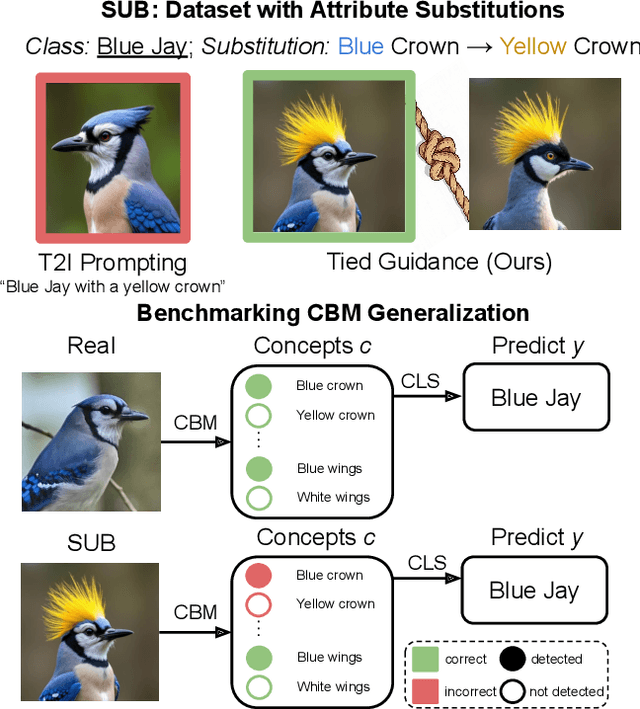
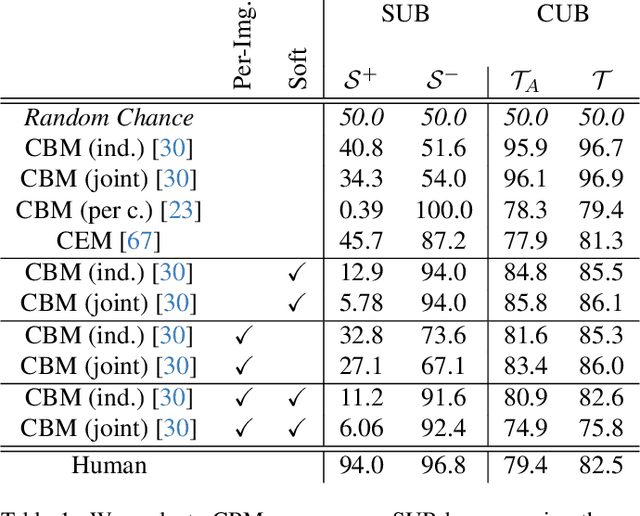
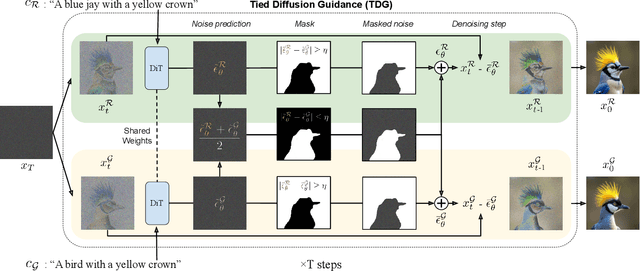

Concept Bottleneck Models (CBMs) and other concept-based interpretable models show great promise for making AI applications more transparent, which is essential in fields like medicine. Despite their success, we demonstrate that CBMs struggle to reliably identify the correct concepts under distribution shifts. To assess the robustness of CBMs to concept variations, we introduce SUB: a fine-grained image and concept benchmark containing 38,400 synthetic images based on the CUB dataset. To create SUB, we select a CUB subset of 33 bird classes and 45 concepts to generate images which substitute a specific concept, such as wing color or belly pattern. We introduce a novel Tied Diffusion Guidance (TDG) method to precisely control generated images, where noise sharing for two parallel denoising processes ensures that both the correct bird class and the correct attribute are generated. This novel benchmark enables rigorous evaluation of CBMs and similar interpretable models, contributing to the development of more robust methods. Our code is available at https://github.com/ExplainableML/sub and the dataset at http://huggingface.co/datasets/Jessica-bader/SUB.
LoFT: LoRA-fused Training Dataset Generation with Few-shot Guidance
May 16, 2025Despite recent advances in text-to-image generation, using synthetically generated data seldom brings a significant boost in performance for supervised learning. Oftentimes, synthetic datasets do not faithfully recreate the data distribution of real data, i.e., they lack the fidelity or diversity needed for effective downstream model training. While previous work has employed few-shot guidance to address this issue, existing methods still fail to capture and generate features unique to specific real images. In this paper, we introduce a novel dataset generation framework named LoFT, LoRA-Fused Training-data Generation with Few-shot Guidance. Our method fine-tunes LoRA weights on individual real images and fuses them at inference time, producing synthetic images that combine the features of real images for improved diversity and fidelity of generated data. We evaluate the synthetic data produced by LoFT on 10 datasets, using 8 to 64 real images per class as guidance and scaling up to 1000 images per class. Our experiments show that training on LoFT-generated data consistently outperforms other synthetic dataset methods, significantly increasing accuracy as the dataset size increases. Additionally, our analysis demonstrates that LoFT generates datasets with high fidelity and sufficient diversity, which contribute to the performance improvement. The code is available at https://github.com/ExplainableML/LoFT.
Concept-Guided Interpretability via Neural Chunking
May 16, 2025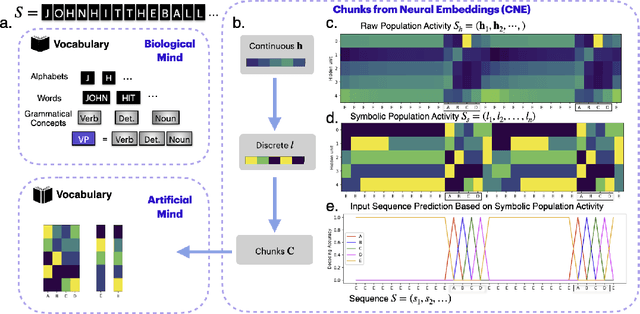
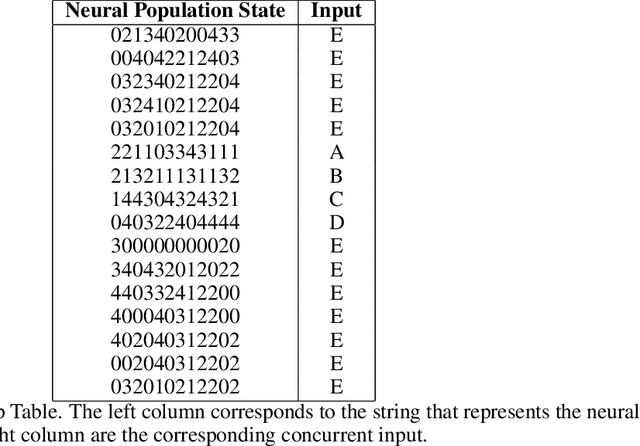
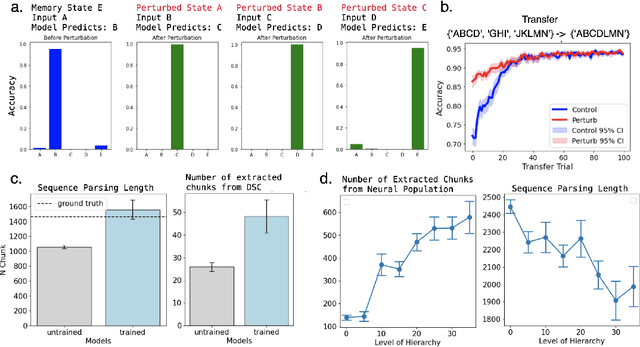
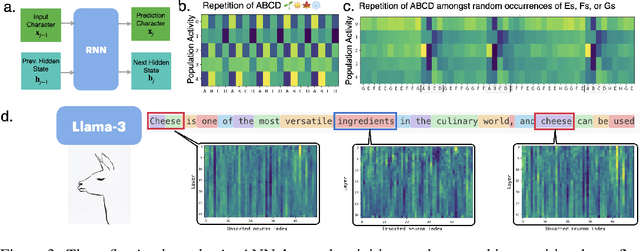
Neural networks are often black boxes, reflecting the significant challenge of understanding their internal workings. We propose a different perspective that challenges the prevailing view: rather than being inscrutable, neural networks exhibit patterns in their raw population activity that mirror regularities in the training data. We refer to this as the Reflection Hypothesis and provide evidence for this phenomenon in both simple recurrent neural networks (RNNs) and complex large language models (LLMs). Building on this insight, we propose to leverage cognitively-inspired methods of chunking to segment high-dimensional neural population dynamics into interpretable units that reflect underlying concepts. We propose three methods to extract these emerging entities, complementing each other based on label availability and dimensionality. Discrete sequence chunking (DSC) creates a dictionary of entities; population averaging (PA) extracts recurring entities that correspond to known labels; and unsupervised chunk discovery (UCD) can be used when labels are absent. We demonstrate the effectiveness of these methods in extracting entities across varying model sizes, ranging from inducing compositionality in RNNs to uncovering recurring neural population states in large models with diverse architectures, and illustrate their advantage over other methods. Throughout, we observe a robust correspondence between the extracted entities and concrete or abstract concepts. Artificially inducing the extracted entities in neural populations effectively alters the network's generation of associated concepts. Our work points to a new direction for interpretability, one that harnesses both cognitive principles and the structure of naturalistic data to reveal the hidden computations of complex learning systems, gradually transforming them from black boxes into systems we can begin to understand.
Feasibility with Language Models for Open-World Compositional Zero-Shot Learning
May 16, 2025Humans can easily tell if an attribute (also called state) is realistic, i.e., feasible, for an object, e.g. fire can be hot, but it cannot be wet. In Open-World Compositional Zero-Shot Learning, when all possible state-object combinations are considered as unseen classes, zero-shot predictors tend to perform poorly. Our work focuses on using external auxiliary knowledge to determine the feasibility of state-object combinations. Our Feasibility with Language Model (FLM) is a simple and effective approach that leverages Large Language Models (LLMs) to better comprehend the semantic relationships between states and objects. FLM involves querying an LLM about the feasibility of a given pair and retrieving the output logit for the positive answer. To mitigate potential misguidance of the LLM given that many of the state-object compositions are rare or completely infeasible, we observe that the in-context learning ability of LLMs is essential. We present an extensive study identifying Vicuna and ChatGPT as best performing, and we demonstrate that our FLM consistently improves OW-CZSL performance across all three benchmarks.
A Large Scale Analysis of Gender Biases in Text-to-Image Generative Models
Mar 30, 2025With the increasing use of image generation technology, understanding its social biases, including gender bias, is essential. This paper presents the first large-scale study on gender bias in text-to-image (T2I) models, focusing on everyday situations. While previous research has examined biases in occupations, we extend this analysis to gender associations in daily activities, objects, and contexts. We create a dataset of 3,217 gender-neutral prompts and generate 200 images per prompt from five leading T2I models. We automatically detect the perceived gender of people in the generated images and filter out images with no person or multiple people of different genders, leaving 2,293,295 images. To enable a broad analysis of gender bias in T2I models, we group prompts into semantically similar concepts and calculate the proportion of male- and female-gendered images for each prompt. Our analysis shows that T2I models reinforce traditional gender roles, reflect common gender stereotypes in household roles, and underrepresent women in financial related activities. Women are predominantly portrayed in care- and human-centered scenarios, and men in technical or physical labor scenarios.
Discovering Chunks in Neural Embeddings for Interpretability
Feb 03, 2025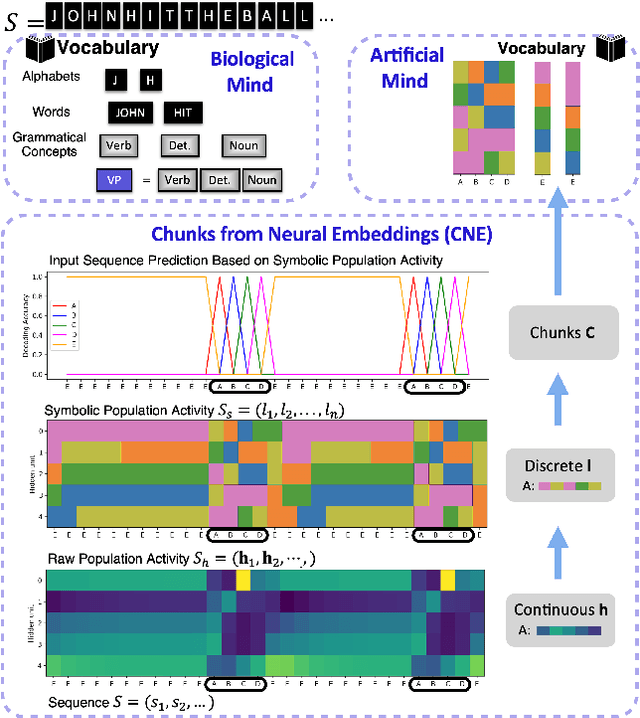

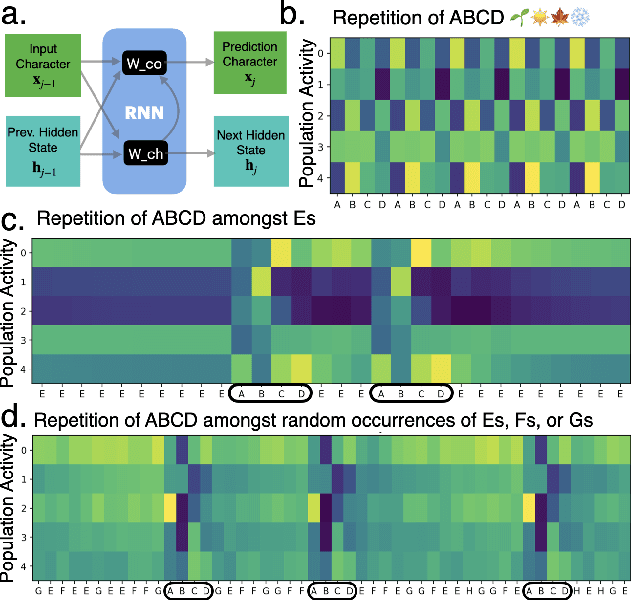
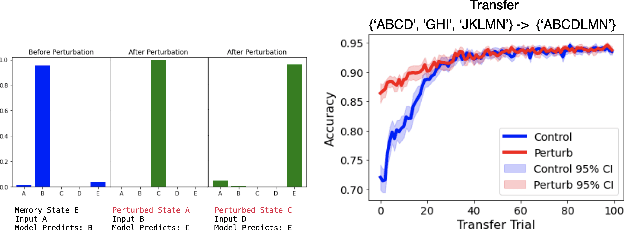
Understanding neural networks is challenging due to their high-dimensional, interacting components. Inspired by human cognition, which processes complex sensory data by chunking it into recurring entities, we propose leveraging this principle to interpret artificial neural population activities. Biological and artificial intelligence share the challenge of learning from structured, naturalistic data, and we hypothesize that the cognitive mechanism of chunking can provide insights into artificial systems. We first demonstrate this concept in recurrent neural networks (RNNs) trained on artificial sequences with imposed regularities, observing that their hidden states reflect these patterns, which can be extracted as a dictionary of chunks that influence network responses. Extending this to large language models (LLMs) like LLaMA, we identify similar recurring embedding states corresponding to concepts in the input, with perturbations to these states activating or inhibiting the associated concepts. By exploring methods to extract dictionaries of identifiable chunks across neural embeddings of varying complexity, our findings introduce a new framework for interpreting neural networks, framing their population activity as structured reflections of the data they process.