 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHow should the advent of large language models affect the practice of science?
Dec 05, 2023Large language models (LLMs) are being increasingly incorporated into scientific workflows. However, we have yet to fully grasp the implications of this integration. How should the advent of large language models affect the practice of science? For this opinion piece, we have invited four diverse groups of scientists to reflect on this query, sharing their perspectives and engaging in debate. Schulz et al. make the argument that working with LLMs is not fundamentally different from working with human collaborators, while Bender et al. argue that LLMs are often misused and over-hyped, and that their limitations warrant a focus on more specialized, easily interpretable tools. Marelli et al. emphasize the importance of transparent attribution and responsible use of LLMs. Finally, Botvinick and Gershman advocate that humans should retain responsibility for determining the scientific roadmap. To facilitate the discussion, the four perspectives are complemented with a response from each group. By putting these different perspectives in conversation, we aim to bring attention to important considerations within the academic community regarding the adoption of LLMs and their impact on both current and future scientific practices.
The Development of Darwin's Origin of Species
Feb 26, 2018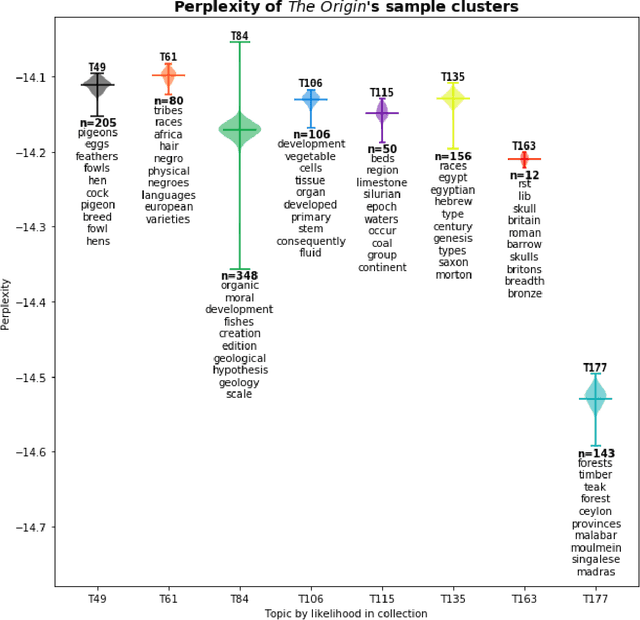
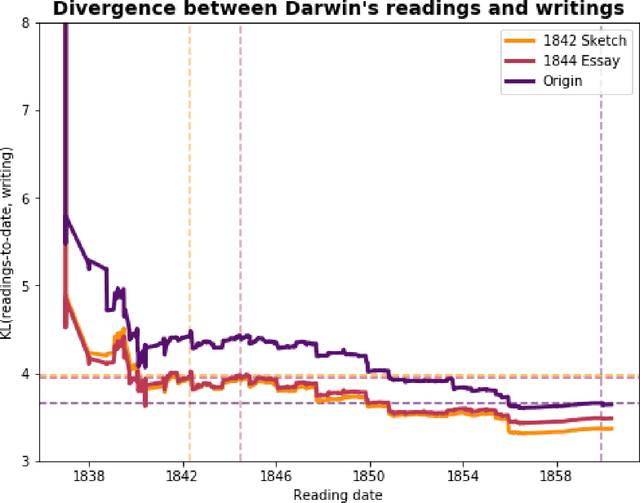
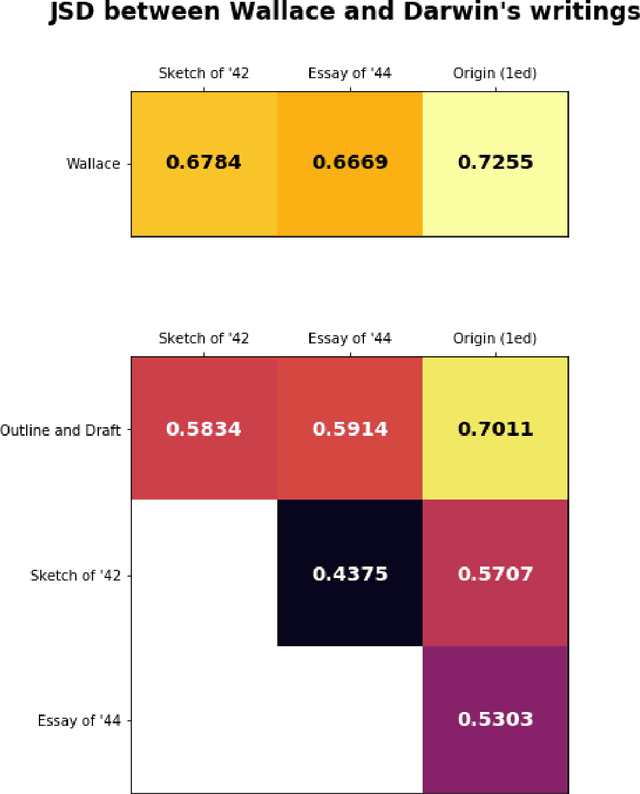
From 1837, when he returned to England aboard the $\textit{HMS Beagle}$, to 1860, just after publication of $\textit{The Origin of Species}$, Charles Darwin kept detailed notes of each book he read or wanted to read. His notes and manuscripts provide information about decades of individual scientific practice. Previously, we trained topic models on the full texts of each reading, and applied information-theoretic measures to detect that changes in his reading patterns coincided with the boundaries of his three major intellectual projects in the period 1837-1860. In this new work we apply the reading model to five additional documents, four of them by Darwin: the first edition of $\textit{The Origin of Species}$, two private essays stating intermediate forms of his theory in 1842 and 1844, a third essay of disputed dating, and Alfred Russel Wallace's essay, which Darwin received in 1858. We address three historical inquiries, previously treated qualitatively: 1) the mythology of "Darwin's Delay," that despite completing an extensive draft in 1844, Darwin waited until 1859 to publish $\textit{The Origin of Species}$ due to external pressures; 2) the relationship between Darwin and Wallace's contemporaneous theories, especially in light of their joint presentation; and 3) dating of the "Outline and Draft" which was rediscovered in 1975 and postulated first as an 1839 draft preceding the Sketch of 1842, then as an interstitial draft between the 1842 and 1844 essays.
Multi-level computational methods for interdisciplinary research in the HathiTrust Digital Library
Jun 08, 2017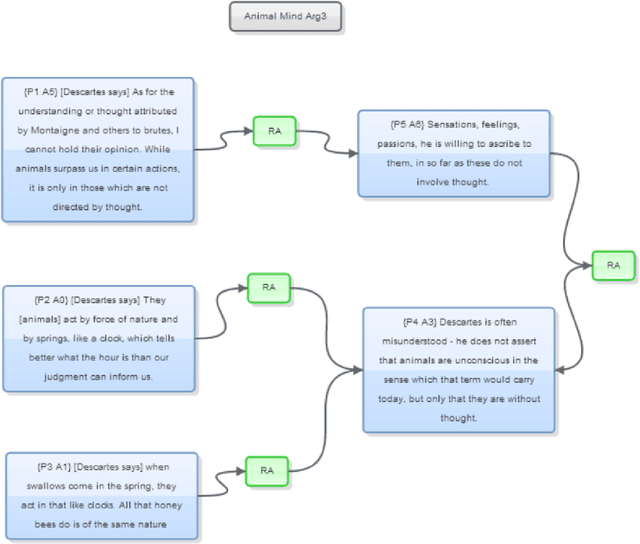
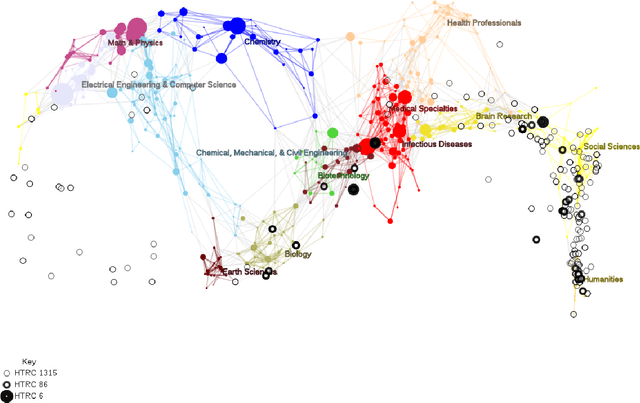

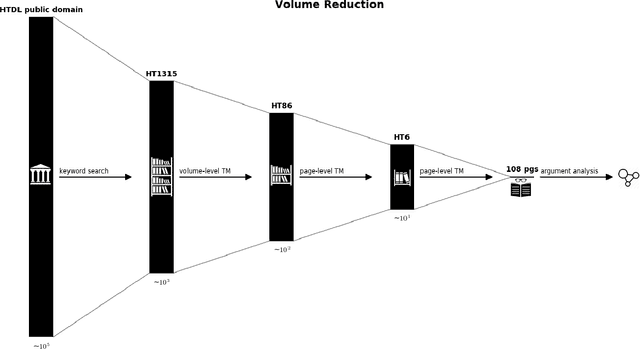
We show how faceted search using a combination of traditional classification systems and mixed-membership topic models can go beyond keyword search to inform resource discovery, hypothesis formulation, and argument extraction for interdisciplinary research. Our test domain is the history and philosophy of scientific work on animal mind and cognition. The methods can be generalized to other research areas and ultimately support a system for semi-automatic identification of argument structures. We provide a case study for the application of the methods to the problem of identifying and extracting arguments about anthropomorphism during a critical period in the development of comparative psychology. We show how a combination of classification systems and mixed-membership models trained over large digital libraries can inform resource discovery in this domain. Through a novel approach of "drill-down" topic modeling---simultaneously reducing both the size of the corpus and the unit of analysis---we are able to reduce a large collection of fulltext volumes to a much smaller set of pages within six focal volumes containing arguments of interest to historians and philosophers of comparative psychology. The volumes identified in this way did not appear among the first ten results of the keyword search in the HathiTrust digital library and the pages bear the kind of "close reading" needed to generate original interpretations that is the heart of scholarly work in the humanities. Zooming back out, we provide a way to place the books onto a map of science originally constructed from very different data and for different purposes. The multilevel approach advances understanding of the intellectual and societal contexts in which writings are interpreted.
Towards Evaluation of Cultural-scale Claims in Light of Topic Model Sampling Effects
Feb 13, 2017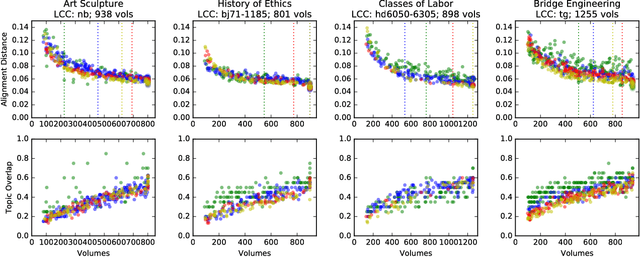
Cultural-scale models of full text documents are prone to over-interpretation by researchers making unintentionally strong socio-linguistic claims (Pechenick et al., 2015) without recognizing that even large digital libraries are merely samples of all the books ever produced. In this study, we test the sensitivity of the topic models to the sampling process by taking random samples of books in the Hathi Trust Digital Library from different areas of the Library of Congress Classification Outline. For each classification area, we train several topic models over the entire class with different random seeds, generating a set of spanning models. Then, we train topic models on random samples of books from the classification area, generating a set of sample models. Finally, we perform a topic alignment between each pair of models by computing the Jensen-Shannon distance (JSD) between the word probability distributions for each topic. We take two measures on each model alignment: alignment distance and topic overlap. We find that sample models with a large sample size typically have an alignment distance that falls in the range of the alignment distance between spanning models. Unsurprisingly, as sample size increases, alignment distance decreases. We also find that the topic overlap increases as sample size increases. However, the decomposition of these measures by sample size differs by number of topics and by classification area. We speculate that these measures could be used to find classes which have a common "canon" discussed among all books in the area, as shown by high topic overlap and low alignment distance even in small sample sizes.
Topic Modeling the Hàn diăn Ancient Classics
Feb 02, 2017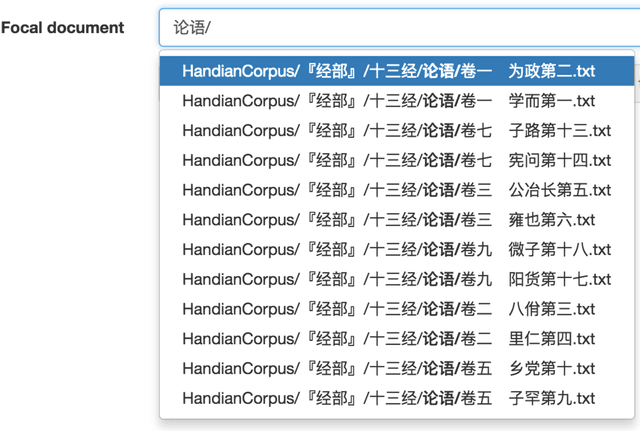
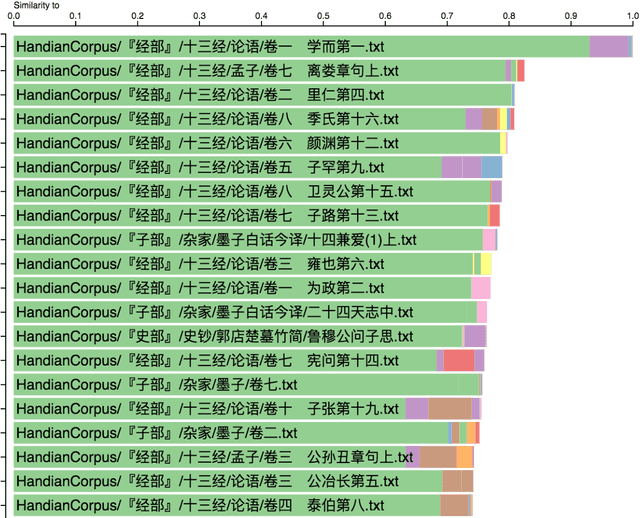
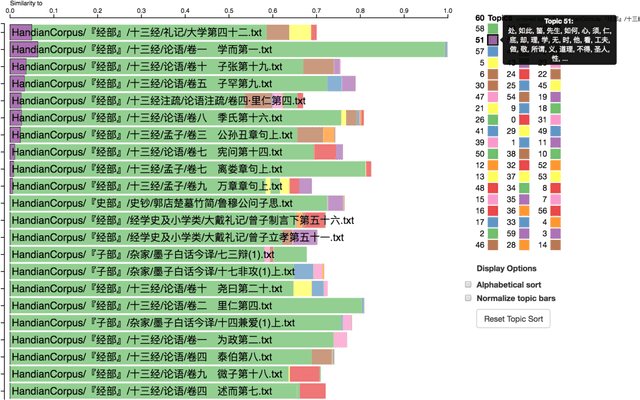
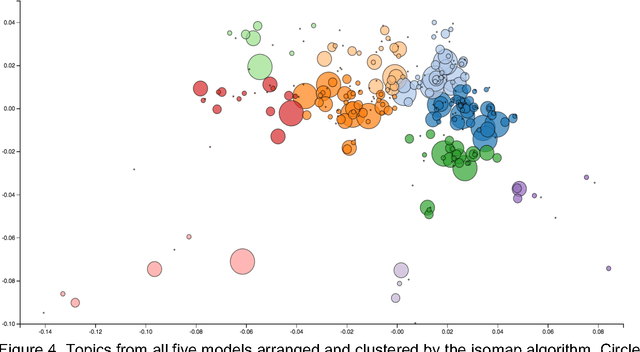
Ancient Chinese texts present an area of enormous challenge and opportunity for humanities scholars interested in exploiting computational methods to assist in the development of new insights and interpretations of culturally significant materials. In this paper we describe a collaborative effort between Indiana University and Xi'an Jiaotong University to support exploration and interpretation of a digital corpus of over 18,000 ancient Chinese documents, which we refer to as the "Handian" ancient classics corpus (H\`an di\u{a}n g\u{u} j\'i, i.e, the "Han canon" or "Chinese classics"). It contains classics of ancient Chinese philosophy, documents of historical and biographical significance, and literary works. We begin by describing the Digital Humanities context of this joint project, and the advances in humanities computing that made this project feasible. We describe the corpus and introduce our application of probabilistic topic modeling to this corpus, with attention to the particular challenges posed by modeling ancient Chinese documents. We give a specific example of how the software we have developed can be used to aid discovery and interpretation of themes in the corpus. We outline more advanced forms of computer-aided interpretation that are also made possible by the programming interface provided by our system, and the general implications of these methods for understanding the nature of meaning in these texts.
Exploration and Exploitation of Victorian Science in Darwin's Reading Notebooks
Feb 02, 2017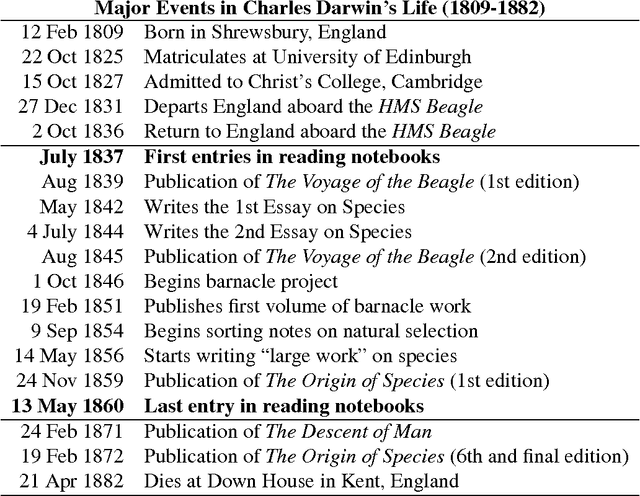
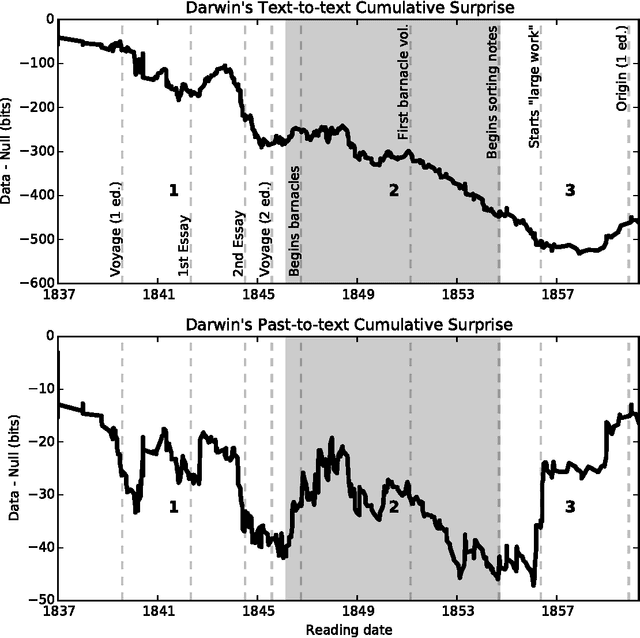
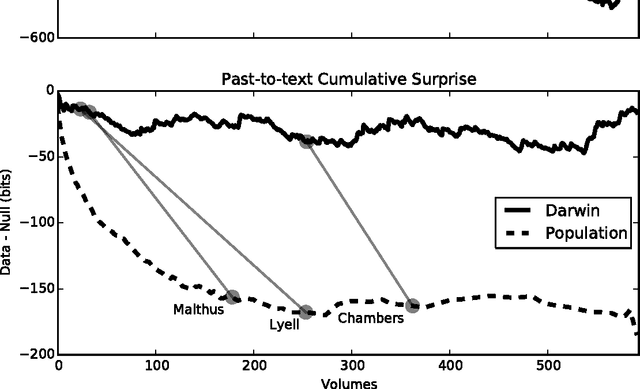
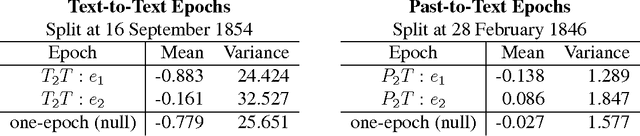
Search in an environment with an uncertain distribution of resources involves a trade-off between exploitation of past discoveries and further exploration. This extends to information foraging, where a knowledge-seeker shifts between reading in depth and studying new domains. To study this decision-making process, we examine the reading choices made by one of the most celebrated scientists of the modern era: Charles Darwin. From the full-text of books listed in his chronologically-organized reading journals, we generate topic models to quantify his local (text-to-text) and global (text-to-past) reading decisions using Kullback-Liebler Divergence, a cognitively-validated, information-theoretic measure of relative surprise. Rather than a pattern of surprise-minimization, corresponding to a pure exploitation strategy, Darwin's behavior shifts from early exploitation to later exploration, seeking unusually high levels of cognitive surprise relative to previous eras. These shifts, detected by an unsupervised Bayesian model, correlate with major intellectual epochs of his career as identified both by qualitative scholarship and Darwin's own self-commentary. Our methods allow us to compare his consumption of texts with their publication order. We find Darwin's consumption more exploratory than the culture's production, suggesting that underneath gradual societal changes are the explorations of individual synthesis and discovery. Our quantitative methods advance the study of cognitive search through a framework for testing interactions between individual and collective behavior and between short- and long-term consumption choices. This novel application of topic modeling to characterize individual reading complements widespread studies of collective scientific behavior.
* Cognition pre-print, published February 2017; 22 pages, plus 17 pages supporting information, 7 pages references