 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEpistemic diversity across language models mitigates knowledge collapse
Dec 17, 2025The growing use of artificial intelligence (AI) raises concerns of knowledge collapse, i.e., a reduction to the most dominant and central set of ideas. Prior work has demonstrated single-model collapse, defined as performance decay in an AI model trained on its own output. Inspired by ecology, we ask whether AI ecosystem diversity, that is, diversity among models, can mitigate such a collapse. We build on the single-model approach but focus on ecosystems of models trained on their collective output. To study the effect of diversity on model performance, we segment the training data across language models and evaluate the resulting ecosystems over ten, self-training iterations. We find that increased epistemic diversity mitigates collapse, but, interestingly, only up to an optimal level. Our results suggest that an ecosystem containing only a few diverse models fails to express the rich mixture of the full, true distribution, resulting in rapid performance decay. Yet distributing the data across too many models reduces each model's approximation capacity on the true distribution, leading to poor performance already in the first iteration step. In the context of AI monoculture, our results suggest the need to monitor diversity across AI systems and to develop policies that incentivize more domain- and community-specific models.
From job titles to jawlines: Using context voids to study generative AI systems
Apr 16, 2025

In this paper, we introduce a speculative design methodology for studying the behavior of generative AI systems, framing design as a mode of inquiry. We propose bridging seemingly unrelated domains to generate intentional context voids, using these tasks as probes to elicit AI model behavior. We demonstrate this through a case study: probing the ChatGPT system (GPT-4 and DALL-E) to generate headshots from professional Curricula Vitae (CVs). In contrast to traditional ways, our approach assesses system behavior under conditions of radical uncertainty -- when forced to invent entire swaths of missing context -- revealing subtle stereotypes and value-laden assumptions. We qualitatively analyze how the system interprets identity and competence markers from CVs, translating them into visual portraits despite the missing context (i.e. physical descriptors). We show that within this context void, the AI system generates biased representations, potentially relying on stereotypical associations or blatant hallucinations.
Insights from Network Science can advance Deep Graph Learning
Feb 03, 2025Deep graph learning and network science both analyze graphs but approach similar problems from different perspectives. Whereas network science focuses on models and measures that reveal the organizational principles of complex systems with explicit assumptions, deep graph learning focuses on flexible and generalizable models that learn patterns in graph data in an automated fashion. Despite these differences, both fields share the same goal: to better model and understand patterns in graph-structured data. Early efforts to integrate methods, models, and measures from network science and deep graph learning indicate significant untapped potential. In this position, we explore opportunities at their intersection. We discuss open challenges in deep graph learning, including data augmentation, improved evaluation practices, higher-order models, and pooling methods. Likewise, we highlight challenges in network science, including scaling to massive graphs, integrating continuous gradient-based optimization, and developing standardized benchmarks.
Search Engines Post-ChatGPT: How Generative Artificial Intelligence Could Make Search Less Reliable
Feb 18, 2024In this commentary, we discuss the evolving nature of search engines, as they begin to generate, index, and distribute content created by generative artificial intelligence (GenAI). Our discussion highlights challenges in the early stages of GenAI integration, particularly around factual inconsistencies and biases. We discuss how output from GenAI carries an unwarranted sense of credibility, while decreasing transparency and sourcing ability. Furthermore, search engines are already answering queries with error-laden, generated content, further blurring the provenance of information and impacting the integrity of the information ecosystem. We argue how all these factors could reduce the reliability of search engines. Finally, we summarize some of the active research directions and open questions.
How should the advent of large language models affect the practice of science?
Dec 05, 2023Large language models (LLMs) are being increasingly incorporated into scientific workflows. However, we have yet to fully grasp the implications of this integration. How should the advent of large language models affect the practice of science? For this opinion piece, we have invited four diverse groups of scientists to reflect on this query, sharing their perspectives and engaging in debate. Schulz et al. make the argument that working with LLMs is not fundamentally different from working with human collaborators, while Bender et al. argue that LLMs are often misused and over-hyped, and that their limitations warrant a focus on more specialized, easily interpretable tools. Marelli et al. emphasize the importance of transparent attribution and responsible use of LLMs. Finally, Botvinick and Gershman advocate that humans should retain responsibility for determining the scientific roadmap. To facilitate the discussion, the four perspectives are complemented with a response from each group. By putting these different perspectives in conversation, we aim to bring attention to important considerations within the academic community regarding the adoption of LLMs and their impact on both current and future scientific practices.
Delineating Knowledge Domains in the Scientific Literature Using Visual Information
Aug 12, 2019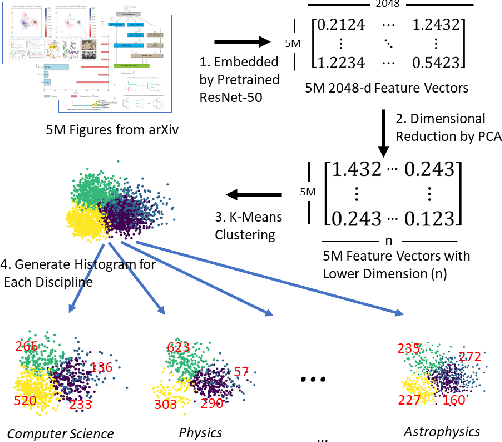
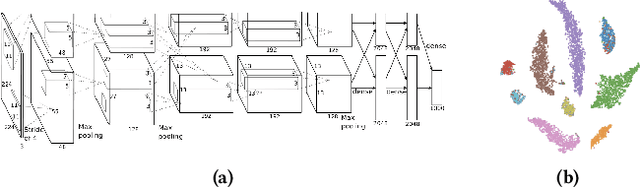
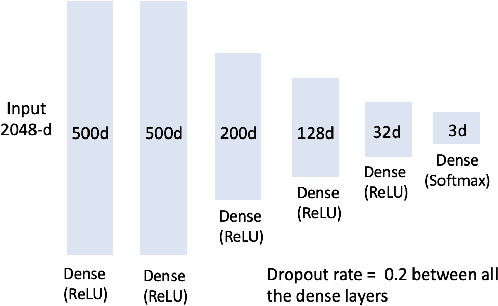
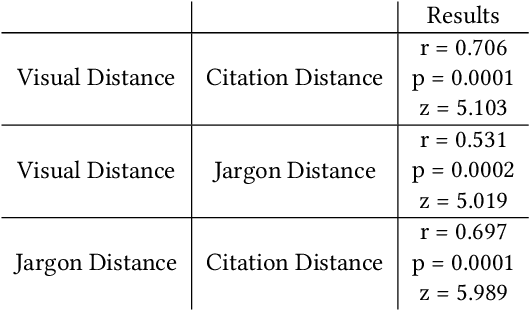
Figures are an important channel for scientific communication, used to express complex ideas, models and data in ways that words cannot. However, this visual information is mostly ignored in analyses of the scientific literature. In this paper, we demonstrate the utility of using scientific figures as markers of knowledge domains in science, which can be used for classification, recommender systems, and studies of scientific information exchange. We encode sets of images into a visual signature, then use distances between these signatures to understand how patterns of visual communication compare with patterns of jargon and citation structures. We find that figures can be as effective for differentiating communities of practice as text or citation patterns. We then consider where these metrics disagree to understand how different disciplines use visualization to express ideas. Finally, we further consider how specific figure types propagate through the literature, suggesting a new mechanism for understanding the flow of ideas apart from conventional channels of text and citations. Our ultimate aim is to better leverage these information-dense objects to improve scientific communication across disciplinary boundaries.
Viziometrics: Analyzing Visual Information in the Scientific Literature
May 27, 2016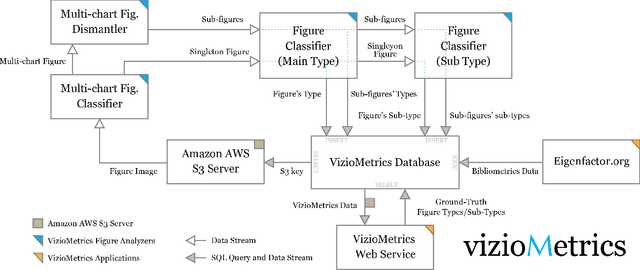
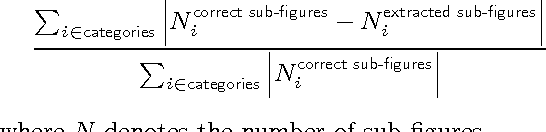

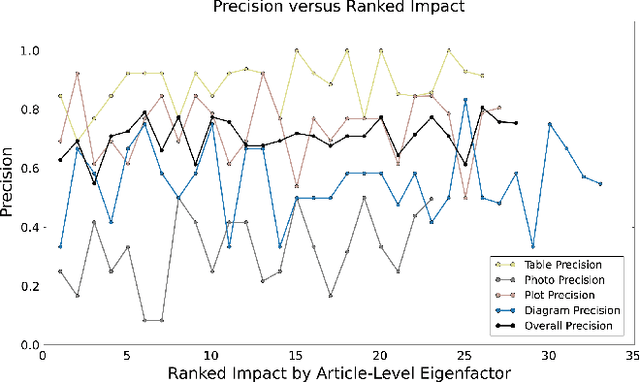
Scientific results are communicated visually in the literature through diagrams, visualizations, and photographs. These information-dense objects have been largely ignored in bibliometrics and scientometrics studies when compared to citations and text. In this paper, we use techniques from computer vision and machine learning to classify more than 8 million figures from PubMed into 5 figure types and study the resulting patterns of visual information as they relate to impact. We find that the distribution of figures and figure types in the literature has remained relatively constant over time, but can vary widely across field and topic. Remarkably, we find a significant correlation between scientific impact and the use of visual information, where higher impact papers tend to include more diagrams, and to a lesser extent more plots and photographs. To explore these results and other ways of extracting this visual information, we have built a visual browser to illustrate the concept and explore design alternatives for supporting viziometric analysis and organizing visual information. We use these results to articulate a new research agenda -- viziometrics -- to study the organization and presentation of visual information in the scientific literature.