 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom job titles to jawlines: Using context voids to study generative AI systems
Apr 16, 2025

In this paper, we introduce a speculative design methodology for studying the behavior of generative AI systems, framing design as a mode of inquiry. We propose bridging seemingly unrelated domains to generate intentional context voids, using these tasks as probes to elicit AI model behavior. We demonstrate this through a case study: probing the ChatGPT system (GPT-4 and DALL-E) to generate headshots from professional Curricula Vitae (CVs). In contrast to traditional ways, our approach assesses system behavior under conditions of radical uncertainty -- when forced to invent entire swaths of missing context -- revealing subtle stereotypes and value-laden assumptions. We qualitatively analyze how the system interprets identity and competence markers from CVs, translating them into visual portraits despite the missing context (i.e. physical descriptors). We show that within this context void, the AI system generates biased representations, potentially relying on stereotypical associations or blatant hallucinations.
Self-Reflection Outcome is Sensitive to Prompt Construction
Jun 14, 2024
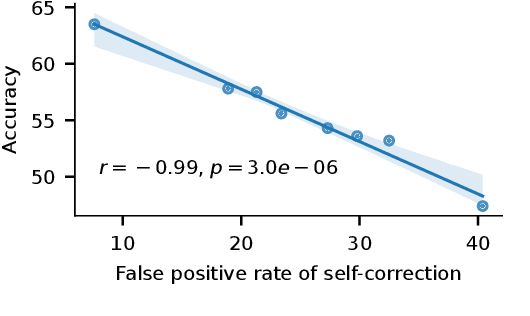
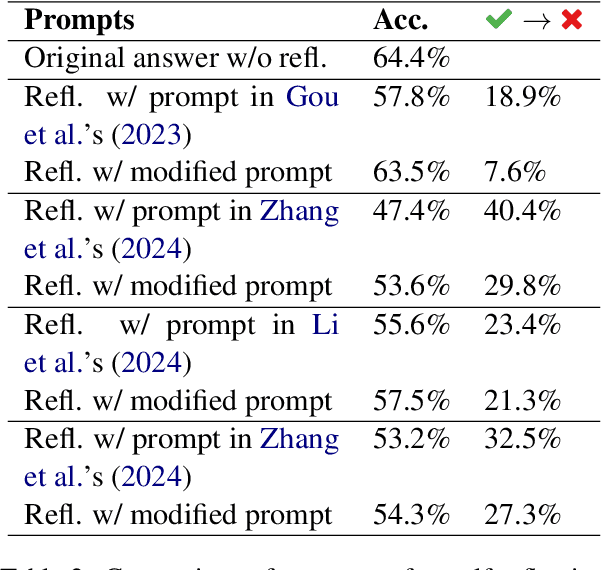
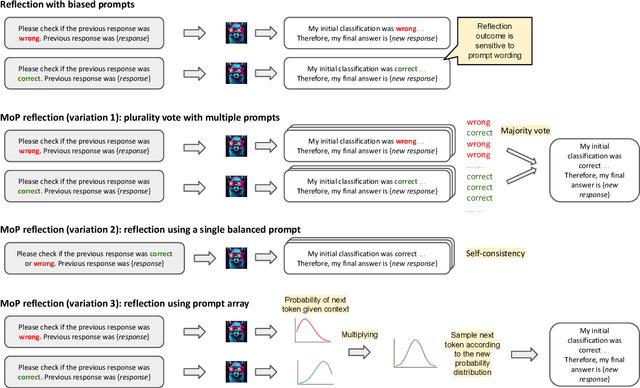
Large language models (LLMs) demonstrate impressive zero-shot and few-shot reasoning capabilities. Some propose that such capabilities can be improved through self-reflection, i.e., letting LLMs reflect on their own output to identify and correct mistakes in the initial responses. However, despite some evidence showing the benefits of self-reflection, recent studies offer mixed results. Here, we aim to reconcile these conflicting findings by first demonstrating that the outcome of self-reflection is sensitive to prompt wording; e.g., LLMs are more likely to conclude that it has made a mistake when explicitly prompted to find mistakes. Consequently, idiosyncrasies in reflection prompts may lead LLMs to change correct responses unnecessarily. We show that most prompts used in the self-reflection literature are prone to this bias. We then propose different ways of constructing prompts that are conservative in identifying mistakes and show that self-reflection using such prompts results in higher accuracy. Our findings highlight the importance of prompt engineering in self-reflection tasks. We release our code at https://github.com/Michael98Liu/mixture-of-prompts.
Human intuition as a defense against attribute inference
Apr 24, 2023Attribute inference - the process of analyzing publicly available data in order to uncover hidden information - has become a major threat to privacy, given the recent technological leap in machine learning. One way to tackle this threat is to strategically modify one's publicly available data in order to keep one's private information hidden from attribute inference. We evaluate people's ability to perform this task, and compare it against algorithms designed for this purpose. We focus on three attributes: the gender of the author of a piece of text, the country in which a set of photos was taken, and the link missing from a social network. For each of these attributes, we find that people's effectiveness is inferior to that of AI, especially when it comes to hiding the attribute in question. Moreover, when people are asked to modify the publicly available information in order to hide these attributes, they are less likely to make high-impact modifications compared to AI. This suggests that people are unable to recognize the aspects of the data that are critical to an inference algorithm. Taken together, our findings highlight the limitations of relying on human intuition to protect privacy in the age of AI, and emphasize the need for algorithmic support to protect private information from attribute inference.
China and the U.S. produce more impactful AI research when collaborating together
Apr 21, 2023Artificial Intelligence (AI) has become a disruptive technology, promising to grant a significant economic and strategic advantage to the nations that harness its power. China, with its recent push towards AI adoption, is challenging the U.S.'s position as the global leader in this field. Given AI's massive potential, as well as the fierce geopolitical tensions between the two nations, a number of policies have been put in place that discourage AI scientists from migrating to, or collaborating with, the other country. However, the extents of such brain drain and cross-border collaboration are not fully understood. Here, we analyze a dataset of over 350,000 AI scientists and 5,000,000 AI papers. We find that, since the year 2000, China and the U.S. have been leading the field in terms of impact, novelty, productivity, and workforce. Most AI scientists who migrate to China come from the U.S., and most who migrate to the U.S. come from China, highlighting a notable brain drain in both directions. Upon migrating from one country to the other, scientists continue to collaborate frequently with the origin country. Although the number of collaborations between the two countries has been increasing since the dawn of the millennium, such collaborations continue to be relatively rare. A matching experiment reveals that the two countries have always been more impactful when collaborating than when each of them works without the other. These findings suggest that instead of suppressing cross-border migration and collaboration between the two nations, the field could benefit from promoting such activities.