 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContemporary AI lacks the imagination to diverge or negate in science
Jun 09, 2026Bold projections that artificial intelligence will accelerate scientific discovery have raced ahead of evidence from working scientists, and the field still lacks large-scale, scientist-in-the-loop tests of these claims. Here we mount the largest such evaluation to date and map what AI cannot yet do for science. We invited authors of 121,640 recent preprints across biology, medicine, chemistry, and the social sciences to judge ideas that large language models (LLMs) generated from the context and puzzles of their own papers. 6,749 scientists returned 25,139 sets of ratings on novelty, empirical feasibility, probability of being true, and favorability of adoption. Three patterns emerge. First, non-reasoning LLMs collapse into a narrow "hivemind" of similar ideas; reasoning models roam a wider hypothesis space, yet no model class spontaneously proposes null hypotheses -- a move humans make more freely. Second, scientists reward ideas that resemble their own and prize probability over novelty, though social scientists tolerate risk more readily than life scientists. Senior social scientists are the harshest critics, and their skepticism is well-earned: LLMs falter most in pluralistic fields like the social sciences that demand context-aware interpretation and evolving theories. Third, automated evaluators on which the community currently relies -- LLM-as-a-judge, artificial metrics, and even state-of-the-art (SOTA) models -- agree only weakly with expert judgment, and retrieval augmentation and scientist persona prompting yield only marginal gains. A Qwen3-14B reward model we post-trained on human ratings captures field taste nuances, beats SOTA models by up to 27%, and closes the gap to the inter-rater consistency of independent peer reviewers. For all the hype, today's scientific AI still represents a collaborator whose imagination, outputs and judgment benefit from human grounding.
Narrative Flattening: How Post-Training Compresses Thematic, Affective, and Stylistic Variation in LLM Fiction
May 27, 2026Large language models produce fluent fiction, yet their creative output is widely seen as flat. We ask where this quality originates in the training and whether it affects different domains of human fiction equally. We construct a matched story-continuation paradigm across StoryStar (public-platform), TMAS (prompt-guided), and The New Yorker (professional literary)-and compare continuations from four OLMo 32B checkpoints (Base, SFT, DPO, RLVR) against matched human text. Because these checkpoints share architecture, scale, tokenizer, and pretraining, the design isolates the post-training effect. We measure each continuation along three sentence-level dimensions: thematic motion, affective prevalence, and linguistic diversity. Across all three, post-training compresses dynamic variation: thematic transitions become more uniform, high-intensity emotions give way to neutrality, and stylistic diversity across stories shrinks. We term this progressive loss narrative flattening. The effect is directionally stable across story domains but gap size depends on the human baseline: professional literary fiction is compressed most, while public-platform and prompt-guided stories show smaller gaps, consistent with their human baselines sitting closer to the model's default rhythm. Post-trained endpoints converge across domains, suggesting alignment produces a continuation regime largely insensitive to the source domain's narrative texture.
A Theory of Appropriateness That Accounts for Norms of Rationality
Mar 14, 2026We propose a society-first theory of normative appropriateness where individuals, modeled as pre-trained actors with cognitive architectures analogous to Large Language Models (LLMs), generate behavior via predictive pattern completion. Our theory posits that individuals act by completing distributed symbolic patterns based on context, answering questions such as "What does a person such as I do in a situation such as this?". This sense-making mechanism provides a parsimonious account of the key features of human norms: their context-dependence, arbitrariness, automaticity, dynamism, and their support from social sanctioning. It challenges rational-choice theories of social norms by accounting for their key features without needing to exogenously posit scalar rewards or preference relations. By distinguishing between explicit norms, which we associate with in-context adaptation, and implicit norms, which we associate with long-term memory, the theory reconceptualizes several foundational ideas in cognitive science. In particular, it gives an alternative account to the data traditionally seen as supporting dual-process models, and it flips the role of rationality, allowing us to construe it as adherence to culturally-contingent justification standards.
The (Short-Term) Effects of Large Language Models on Unemployment and Earnings
Sep 19, 2025Large Language Models have spread rapidly since the release of ChatGPT in late 2022, accompanied by claims of major productivity gains but also concerns about job displacement. This paper examines the short-run labor market effects of LLM adoption by comparing earnings and unemployment across occupations with differing levels of exposure to these technologies. Using a Synthetic Difference in Differences approach, we estimate the impact of LLM exposure on earnings and unemployment. Our findings show that workers in highly exposed occupations experienced earnings increases following ChatGPT's introduction, while unemployment rates remained unchanged. These results suggest that initial labor market adjustments to LLMs operate primarily through earnings rather than worker reallocation.
Language Models Surface the Unwritten Code of Science and Society
May 25, 2025


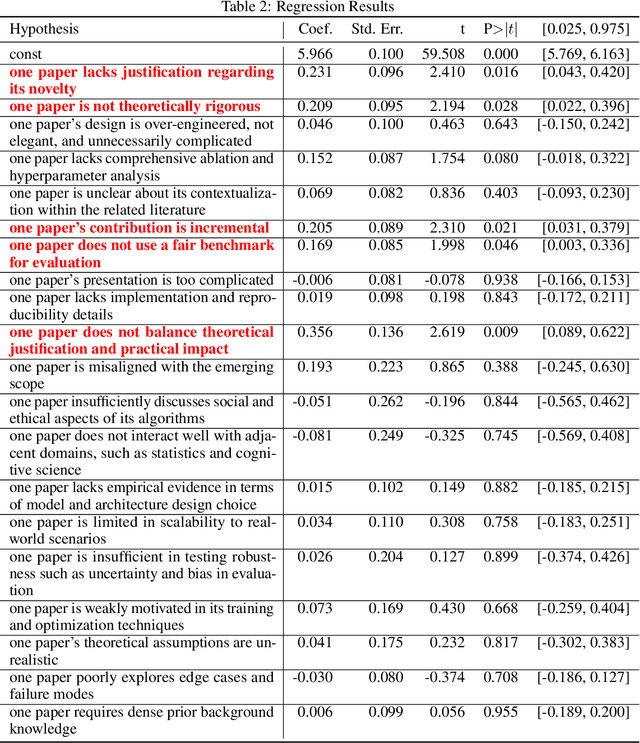
This paper calls on the research community not only to investigate how human biases are inherited by large language models (LLMs) but also to explore how these biases in LLMs can be leveraged to make society's "unwritten code" - such as implicit stereotypes and heuristics - visible and accessible for critique. We introduce a conceptual framework through a case study in science: uncovering hidden rules in peer review - the factors that reviewers care about but rarely state explicitly due to normative scientific expectations. The idea of the framework is to push LLMs to speak out their heuristics through generating self-consistent hypotheses - why one paper appeared stronger in reviewer scoring - among paired papers submitted to 45 computer science conferences, while iteratively searching deeper hypotheses from remaining pairs where existing hypotheses cannot explain. We observed that LLMs' normative priors about the internal characteristics of good science extracted from their self-talk, e.g. theoretical rigor, were systematically updated toward posteriors that emphasize storytelling about external connections, such as how the work is positioned and connected within and across literatures. This shift reveals the primacy of scientific myths about intrinsic properties driving scientific excellence rather than extrinsic contextualization and storytelling that influence conceptions of relevance and significance. Human reviewers tend to explicitly reward aspects that moderately align with LLMs' normative priors (correlation = 0.49) but avoid articulating contextualization and storytelling posteriors in their review comments (correlation = -0.14), despite giving implicit reward to them with positive scores. We discuss the broad applicability of the framework, leveraging LLMs as diagnostic tools to surface the tacit codes underlying human society, enabling more precisely targeted responsible AI.
Introspective Growth: Automatically Advancing LLM Expertise in Technology Judgment
May 18, 2025



Large language models (LLMs) increasingly demonstrate signs of conceptual understanding, yet much of their internal knowledge remains latent, loosely structured, and difficult to access or evaluate. We propose self-questioning as a lightweight and scalable strategy to improve LLMs' understanding, particularly in domains where success depends on fine-grained semantic distinctions. To evaluate this approach, we introduce a challenging new benchmark of 1.3 million post-2015 computer science patent pairs, characterized by dense technical jargon and strategically complex writing. The benchmark centers on a pairwise differentiation task: can a model distinguish between closely related but substantively different inventions? We show that prompting LLMs to generate and answer their own questions - targeting the background knowledge required for the task - significantly improves performance. These self-generated questions and answers activate otherwise underutilized internal knowledge. Allowing LLMs to retrieve answers from external scientific texts further enhances performance, suggesting that model knowledge is compressed and lacks the full richness of the training data. We also find that chain-of-thought prompting and self-questioning converge, though self-questioning remains more effective for improving understanding of technical concepts. Notably, we uncover an asymmetry in prompting: smaller models often generate more fundamental, more open-ended, better-aligned questions for mid-sized models than large models with better understanding do, revealing a new strategy for cross-model collaboration. Altogether, our findings establish self-questioning as both a practical mechanism for automatically improving LLM comprehension, especially in domains with sparse and underrepresented knowledge, and a diagnostic probe of how internal and external knowledge are organized.
China and the U.S. produce more impactful AI research when collaborating together
Apr 21, 2023Artificial Intelligence (AI) has become a disruptive technology, promising to grant a significant economic and strategic advantage to the nations that harness its power. China, with its recent push towards AI adoption, is challenging the U.S.'s position as the global leader in this field. Given AI's massive potential, as well as the fierce geopolitical tensions between the two nations, a number of policies have been put in place that discourage AI scientists from migrating to, or collaborating with, the other country. However, the extents of such brain drain and cross-border collaboration are not fully understood. Here, we analyze a dataset of over 350,000 AI scientists and 5,000,000 AI papers. We find that, since the year 2000, China and the U.S. have been leading the field in terms of impact, novelty, productivity, and workforce. Most AI scientists who migrate to China come from the U.S., and most who migrate to the U.S. come from China, highlighting a notable brain drain in both directions. Upon migrating from one country to the other, scientists continue to collaborate frequently with the origin country. Although the number of collaborations between the two countries has been increasing since the dawn of the millennium, such collaborations continue to be relatively rare. A matching experiment reveals that the two countries have always been more impactful when collaborating than when each of them works without the other. These findings suggest that instead of suppressing cross-border migration and collaboration between the two nations, the field could benefit from promoting such activities.
Learning from One and Only One Shot
Jan 14, 2022Humans can generalize from only a few examples and from little pre-training on similar tasks. Yet, machine learning (ML) typically requires large data to learn or pre-learn to transfer. Inspired by nativism, we directly model basic human-innate priors in abstract visual tasks e.g., character/doodle recognition. This yields a white-box model that learns general-appearance similarity -- how any two images look in general -- by mimicking how humans naturally "distort" an object at first sight. Using simply the nearest-neighbor classifier on this similarity space, we achieve human-level character recognition using only 1--10 examples per class and nothing else (no pre-training). This differs from few-shot learning (FSL) using significant pre-training. On standard benchmarks MNIST/EMNIST and the Omniglot challenge, we outperform both neural-network-based and classical ML in the "tiny-data" regime, including FSL pre-trained on large data. Our model enables unsupervised learning too: by learning the non-Euclidean, general-appearance similarity space in a k-means style, we can generate human-intuitive archetypes as cluster ``centroids''.
Human Languages with Greater Information Density Increase Communication Speed, but Decrease Conversation Breadth
Dec 15, 2021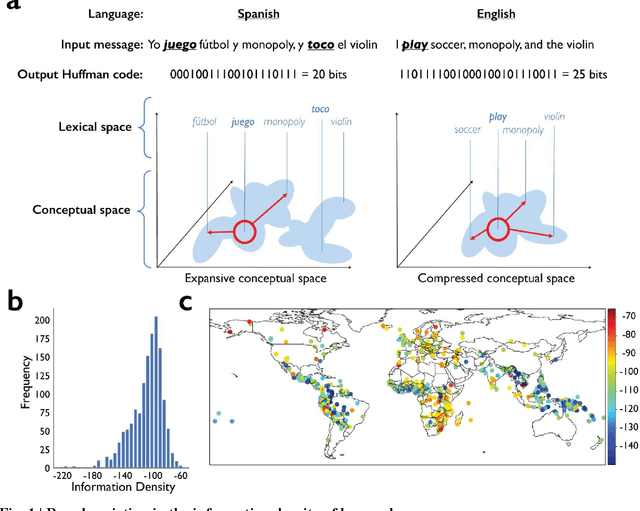


Language is the primary medium through which human information is communicated and coordination is achieved. One of the most important language functions is to categorize the world so messages can be communicated through conversation. While we know a great deal about how human languages vary in their encoding of information within semantic domains such as color, sound, number, locomotion, time, space, human activities, gender, body parts and biology, little is known about the global structure of semantic information and its effect on human communication. Using large-scale computation, artificial intelligence techniques, and massive, parallel corpora across 15 subject areas--including religion, economics, medicine, entertainment, politics, and technology--in 999 languages, here we show substantial variation in the information and semantic density of languages and their consequences for human communication and coordination. In contrast to prior work, we demonstrate that higher density languages communicate information much more quickly relative to lower density languages. Then, using over 9,000 real-life conversations across 14 languages and 90,000 Wikipedia articles across 140 languages, we show that because there are more ways to discuss any given topic in denser languages, conversations and articles retrace and cycle over a narrower conceptual terrain. These results demonstrate an important source of variation across the human communicative channel, suggesting that the structure of language shapes the nature and texture of conversation, with important consequences for the behavior of groups, organizations, markets, and societies.
Human Evaluation of Interpretability: The Case of AI-Generated Music Knowledge
Apr 15, 2020
Interpretability of machine learning models has gained more and more attention among researchers in the artificial intelligence (AI) and human-computer interaction (HCI) communities. Most existing work focuses on decision making, whereas we consider knowledge discovery. In particular, we focus on evaluating AI-discovered knowledge/rules in the arts and humanities. From a specific scenario, we present an experimental procedure to collect and assess human-generated verbal interpretations of AI-generated music theory/rules rendered as sophisticated symbolic/numeric objects. Our goal is to reveal both the possibilities and the challenges in such a process of decoding expressive messages from AI sources. We treat this as a first step towards 1) better design of AI representations that are human interpretable and 2) a general methodology to evaluate interpretability of AI-discovered knowledge representations.