 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAccelerated Design and Deployment of Low-Carbon Concrete for Data Centers
Apr 11, 2022
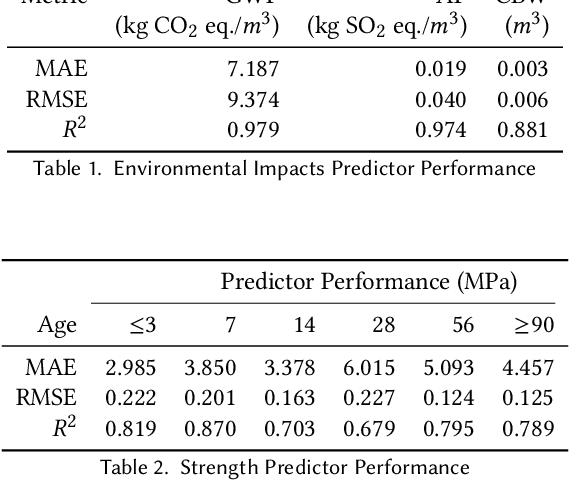

Concrete is the most widely used engineered material in the world with more than 10 billion tons produced annually. Unfortunately, with that scale comes a significant burden in terms of energy, water, and release of greenhouse gases and other pollutants; indeed 8% of worldwide carbon emissions are attributed to the production of cement, a key ingredient in concrete. As such, there is interest in creating concrete formulas that minimize this environmental burden, while satisfying engineering performance requirements including compressive strength. Specifically for computing, concrete is a major ingredient in the construction of data centers. In this work, we use conditional variational autoencoders (CVAEs), a type of semi-supervised generative artificial intelligence (AI) model, to discover concrete formulas with desired properties. Our model is trained just using a small open dataset from the UCI Machine Learning Repository joined with environmental impact data from standard lifecycle analysis. Computational predictions demonstrate CVAEs can design concrete formulas with much lower carbon requirements than existing formulations while meeting design requirements. Next we report laboratory-based compressive strength experiments for five AI-generated formulations, which demonstrate that the formulations exceed design requirements. The resulting formulations were then used by Ozinga Ready Mix -- a concrete supplier -- to generate field-ready concrete formulations, based on local conditions and their expertise in concrete design. Finally, we report on how these formulations were used in the construction of buildings and structures in a Meta data center in DeKalb, IL, USA. Results from field experiments as part of this real-world deployment corroborate the efficacy of AI-generated low-carbon concrete mixes.
Learning from One and Only One Shot
Jan 14, 2022Humans can generalize from only a few examples and from little pre-training on similar tasks. Yet, machine learning (ML) typically requires large data to learn or pre-learn to transfer. Inspired by nativism, we directly model basic human-innate priors in abstract visual tasks e.g., character/doodle recognition. This yields a white-box model that learns general-appearance similarity -- how any two images look in general -- by mimicking how humans naturally "distort" an object at first sight. Using simply the nearest-neighbor classifier on this similarity space, we achieve human-level character recognition using only 1--10 examples per class and nothing else (no pre-training). This differs from few-shot learning (FSL) using significant pre-training. On standard benchmarks MNIST/EMNIST and the Omniglot challenge, we outperform both neural-network-based and classical ML in the "tiny-data" regime, including FSL pre-trained on large data. Our model enables unsupervised learning too: by learning the non-Euclidean, general-appearance similarity space in a k-means style, we can generate human-intuitive archetypes as cluster ``centroids''.
Human Evaluation of Interpretability: The Case of AI-Generated Music Knowledge
Apr 15, 2020
Interpretability of machine learning models has gained more and more attention among researchers in the artificial intelligence (AI) and human-computer interaction (HCI) communities. Most existing work focuses on decision making, whereas we consider knowledge discovery. In particular, we focus on evaluating AI-discovered knowledge/rules in the arts and humanities. From a specific scenario, we present an experimental procedure to collect and assess human-generated verbal interpretations of AI-generated music theory/rules rendered as sophisticated symbolic/numeric objects. Our goal is to reveal both the possibilities and the challenges in such a process of decoding expressive messages from AI sources. We treat this as a first step towards 1) better design of AI representations that are human interpretable and 2) a general methodology to evaluate interpretability of AI-discovered knowledge representations.
A Group-Theoretic Approach to Abstraction: Hierarchical, Interpretable, and Task-Free Clustering
Jul 30, 2018


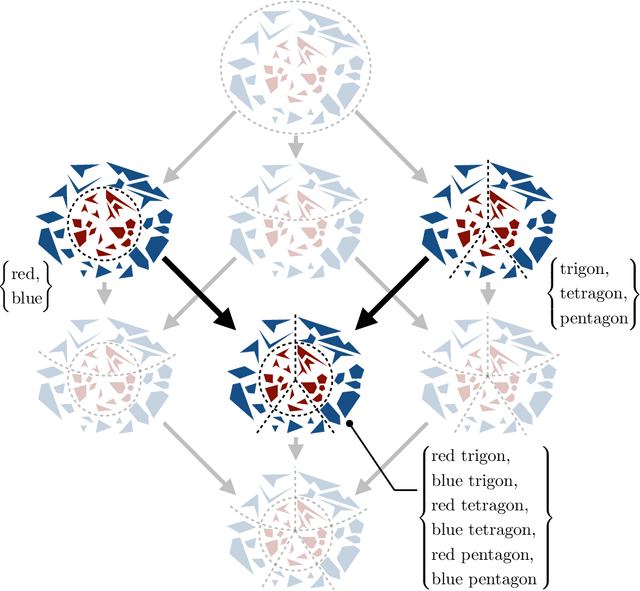
Abstraction plays a key role in concept learning and knowledge discovery. While pervasive in both human and artificial intelligence, it remains mysterious how concepts are abstracted in the first place. We study the nature of abstraction through a group-theoretic approach, formalizing it as a hierarchical, interpretable, and task-free clustering problem. This clustering framework is data-free, feature-free, similarity-free, and globally hierarchical---the four key features that distinguish it from common clustering models. Beyond a theoretical foundation for abstraction, we also present a top-down and a bottom-up approach to establish an algorithmic foundation for practical abstraction-generating methods. Lastly, using both a theoretical explanation and a real-world application, we show that the coupling of our abstraction framework with statistics realizes Shannon's information lattice and even further, brings learning into the picture. This gives a first step towards a principled and cognitive way of automatic concept learning and knowledge discovery.
Probabilistic Rule Realization and Selection
Mar 09, 2018
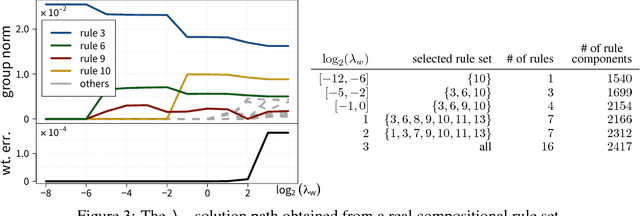
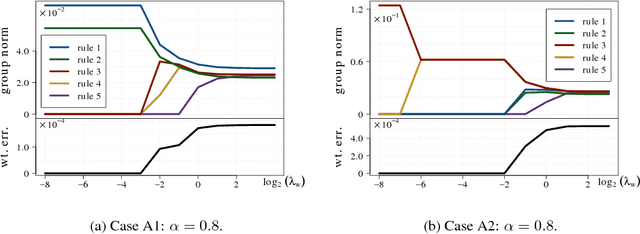
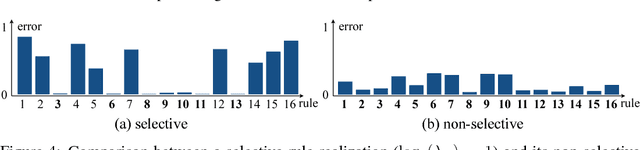
Abstraction and realization are bilateral processes that are key in deriving intelligence and creativity. In many domains, the two processes are approached through rules: high-level principles that reveal invariances within similar yet diverse examples. Under a probabilistic setting for discrete input spaces, we focus on the rule realization problem which generates input sample distributions that follow the given rules. More ambitiously, we go beyond a mechanical realization that takes whatever is given, but instead ask for proactively selecting reasonable rules to realize. This goal is demanding in practice, since the initial rule set may not always be consistent and thus intelligent compromises are needed. We formulate both rule realization and selection as two strongly connected components within a single and symmetric bi-convex problem, and derive an efficient algorithm that works at large scale. Taking music compositional rules as the main example throughout the paper, we demonstrate our model's efficiency in not only music realization (composition) but also music interpretation and understanding (analysis).
Learning Interpretable Musical Compositional Rules and Traces
Jun 17, 2016
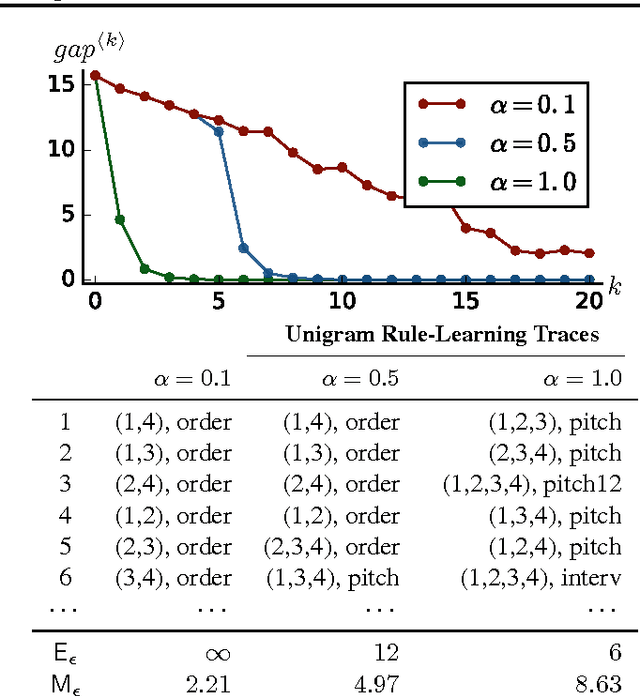
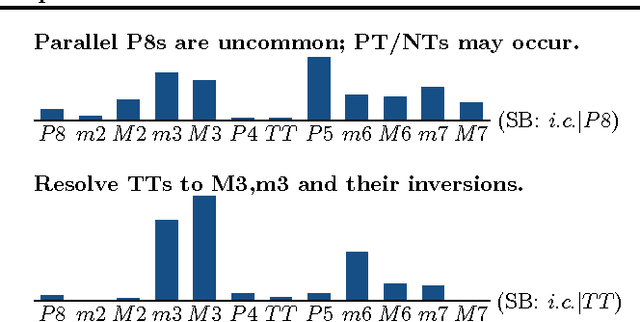
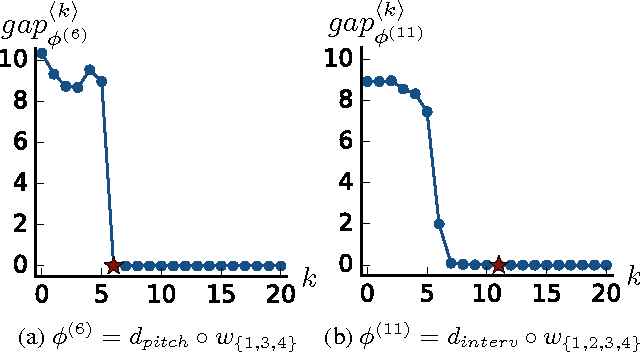
Throughout music history, theorists have identified and documented interpretable rules that capture the decisions of composers. This paper asks, "Can a machine behave like a music theorist?" It presents MUS-ROVER, a self-learning system for automatically discovering rules from symbolic music. MUS-ROVER performs feature learning via $n$-gram models to extract compositional rules --- statistical patterns over the resulting features. We evaluate MUS-ROVER on Bach's (SATB) chorales, demonstrating that it can recover known rules, as well as identify new, characteristic patterns for further study. We discuss how the extracted rules can be used in both machine and human composition.