 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInteractive Mobile App Navigation with Uncertain or Under-specified Natural Language Commands
Feb 04, 2022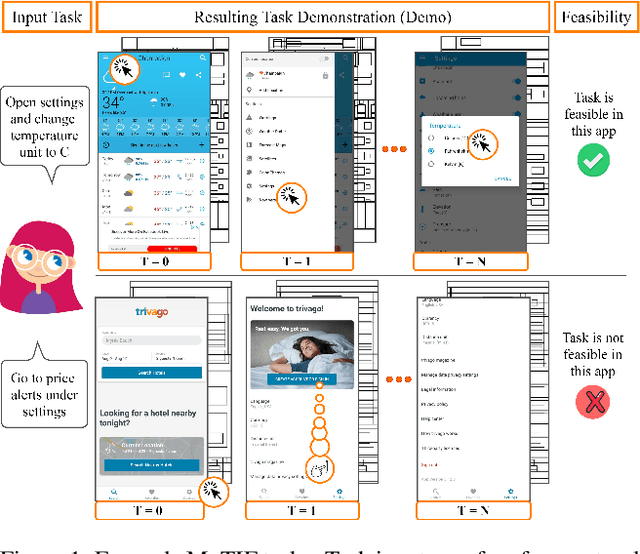
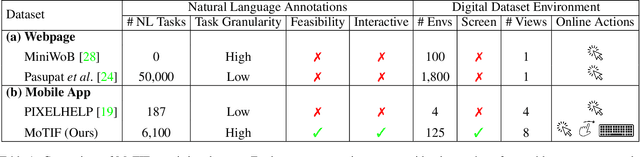
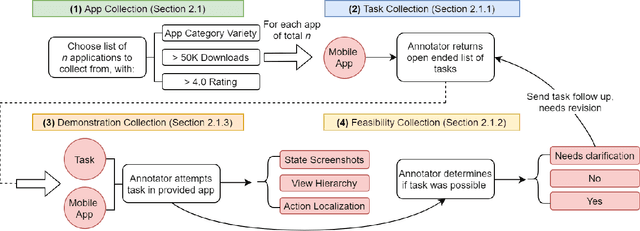
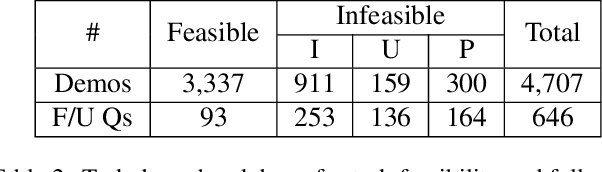
We introduce Mobile app Tasks with Iterative Feedback (MoTIF), a new dataset where the goal is to complete a natural language query in a mobile app. Current datasets for related tasks in interactive question answering, visual common sense reasoning, and question-answer plausibility prediction do not support research in resolving ambiguous natural language requests or operating in diverse digital domains. As a result, they fail to capture complexities of real question answering or interactive tasks. In contrast, MoTIF contains natural language requests that are not satisfiable, the first such work to investigate this issue for interactive vision-language tasks. MoTIF also contains follow up questions for ambiguous queries to enable research on task uncertainty resolution. We introduce task feasibility prediction and propose an initial model which obtains an F1 score of 61.1. We next benchmark task automation with our dataset and find adaptations of prior work perform poorly due to our realistic language requests, obtaining an accuracy of only 20.2% when mapping commands to grounded actions. We analyze performance and gain insight for future work that may bridge the gap between current model ability and what is needed for successful use in application.
Effectively Leveraging Attributes for Visual Similarity
May 04, 2021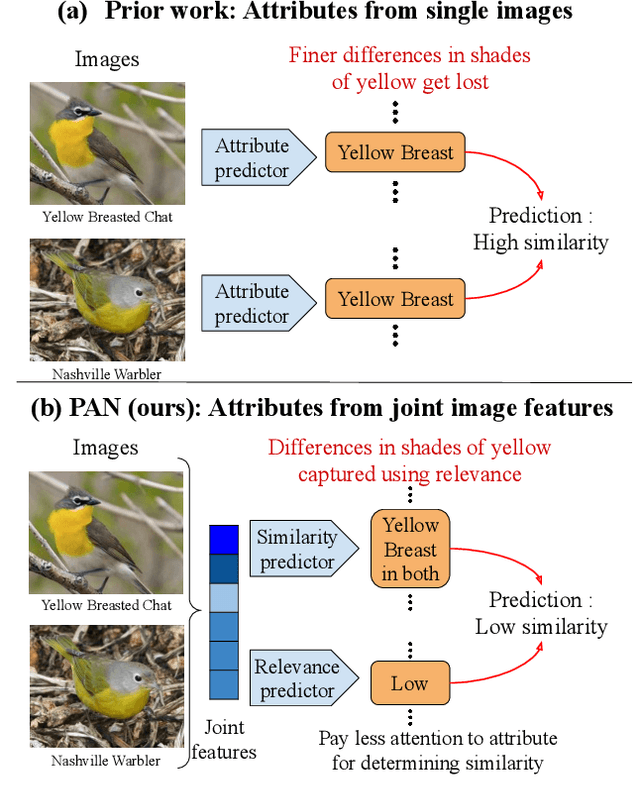
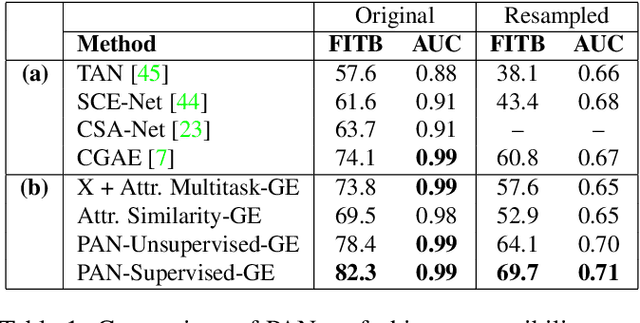


Measuring similarity between two images often requires performing complex reasoning along different axes (e.g., color, texture, or shape). Insights into what might be important for measuring similarity can can be provided by annotated attributes, but prior work tends to view these annotations as complete, resulting in them using a simplistic approach of predicting attributes on single images, which are, in turn, used to measure similarity. However, it is impractical for a dataset to fully annotate every attribute that may be important. Thus, only representing images based on these incomplete annotations may miss out on key information. To address this issue, we propose the Pairwise Attribute-informed similarity Network (PAN), which breaks similarity learning into capturing similarity conditions and relevance scores from a joint representation of two images. This enables our model to identify that two images contain the same attribute, but can have it deemed irrelevant (e.g., due to fine-grained differences between them) and ignored for measuring similarity between the two images. Notably, while prior methods of using attribute annotations are often unable to outperform prior art, PAN obtains a 4-9% improvement on compatibility prediction between clothing items on Polyvore Outfits, a 5\% gain on few shot classification of images using Caltech-UCSD Birds (CUB), and over 1% boost to Recall@1 on In-Shop Clothes Retrieval.
Mobile App Tasks with Iterative Feedback (MoTIF): Addressing Task Feasibility in Interactive Visual Environments
Apr 17, 2021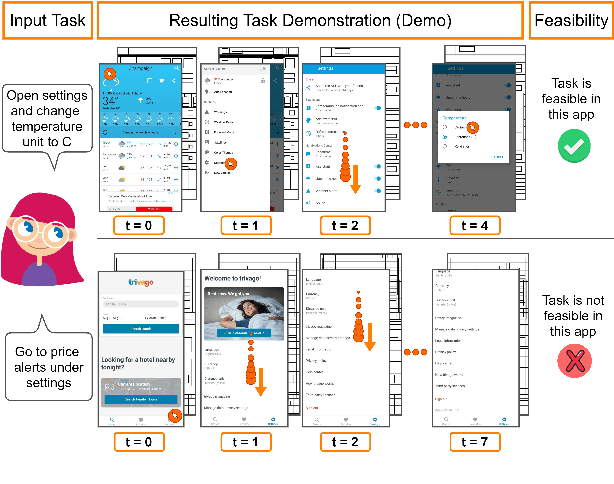
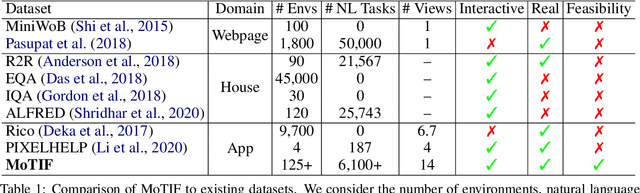
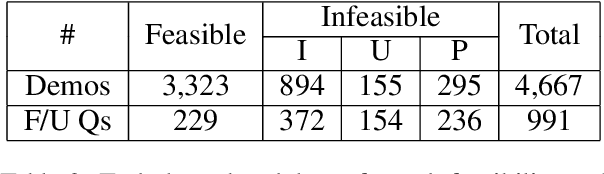
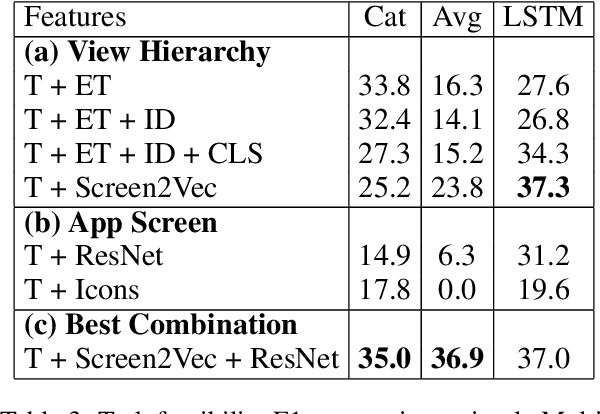
In recent years, vision-language research has shifted to study tasks which require more complex reasoning, such as interactive question answering, visual common sense reasoning, and question-answer plausibility prediction. However, the datasets used for these problems fail to capture the complexity of real inputs and multimodal environments, such as ambiguous natural language requests and diverse digital domains. We introduce Mobile app Tasks with Iterative Feedback (MoTIF), a dataset with natural language commands for the greatest number of interactive environments to date. MoTIF is the first to contain natural language requests for interactive environments that are not satisfiable, and we obtain follow-up questions on this subset to enable research on task uncertainty resolution. We perform initial feasibility classification experiments and only reach an F1 score of 37.3, verifying the need for richer vision-language representations and improved architectures to reason about task feasibility.
Can AI decrypt fashion jargon for you?
Mar 18, 2020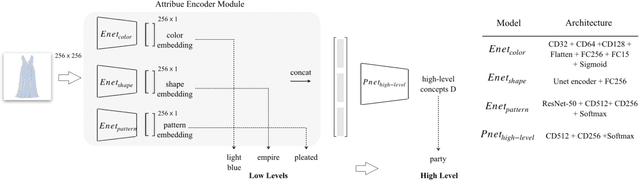
When people talk about fashion, they care about the underlying meaning of fashion concepts,e.g., style.For example, people ask questions like what features make this dress smart.However, the product descriptions in today fashion websites are full of domain specific and low level words. It is not clear to people how exactly those low level descriptions can contribute to a style or any high level fashion concept. In this paper, we proposed a data driven solution to address this concept understanding issues by leveraging a large number of existing product data on fashion sites. We first collected and categorized 1546 fashion keywords into 5 different fashion categories. Then, we collected a new fashion product dataset with 853,056 products in total. Finally, we trained a deep learning model that can explicitly predict and explain high level fashion concepts in a product image with its low level and domain specific fashion features.
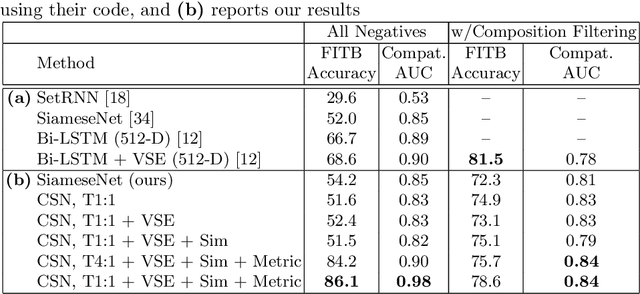
Using Discriminative Methods to Learn Fashion Compatibility Across Datasets
Jun 17, 2019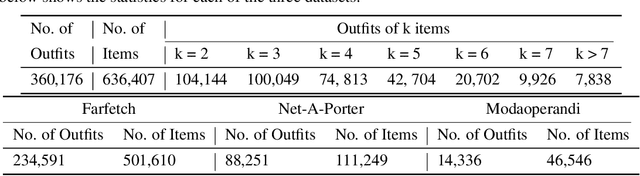
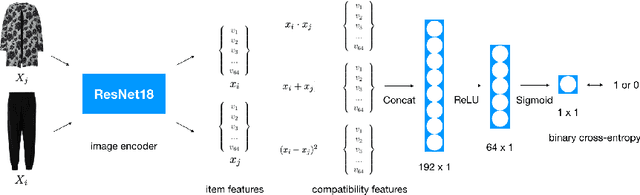
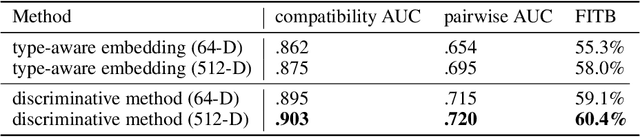

Determining whether a pair of garments are compatible with each other is a challenging matching problem. Past works explored various embedding methods for learning such a relationship. This paper introduces using discriminative methods to learn compatibility, by formulating the task as a simple binary classification problem. We evaluate our approach using an established dataset of outfits created by non-experts and demonstrated an improvement of ~2.5% on established metrics over the state-of-the-art method. We introduce three new datasets of professionally curated outfits and show the consistent performance of our approach on expert-curated datasets. To facilitate comparing across outfit datasets, we propose a new metric which, unlike previously used metrics, is not biased by the average size of outfits. We also demonstrate that compatibility between two types of items can be query indirectly, and such query strategy yield improvements.
Learning Type-Aware Embeddings for Fashion Compatibility
Jul 27, 2018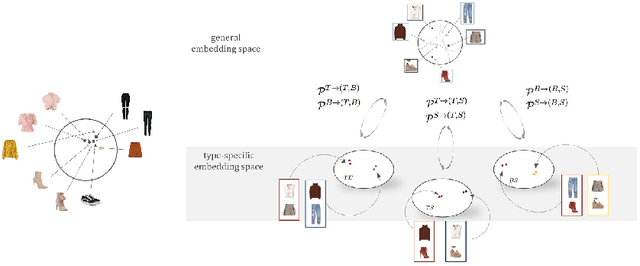


Outfits in online fashion data are composed of items of many different types (e.g. top, bottom, shoes) that share some stylistic relationship with one another. A representation for building outfits requires a method that can learn both notions of similarity (for example, when two tops are interchangeable) and compatibility (items of possibly different type that can go together in an outfit). This paper presents an approach to learning an image embedding that respects item type, and jointly learns notions of item similarity and compatibility in an end-to-end model. To evaluate the learned representation, we crawled 68,306 outfits created by users on the Polyvore website. Our approach obtains 3-5% improvement over the state-of-the-art on outfit compatibility prediction and fill-in-the-blank tasks using our dataset, as well as an established smaller dataset, while supporting a variety of useful queries.
Learning Interpretable Musical Compositional Rules and Traces
Jun 17, 2016
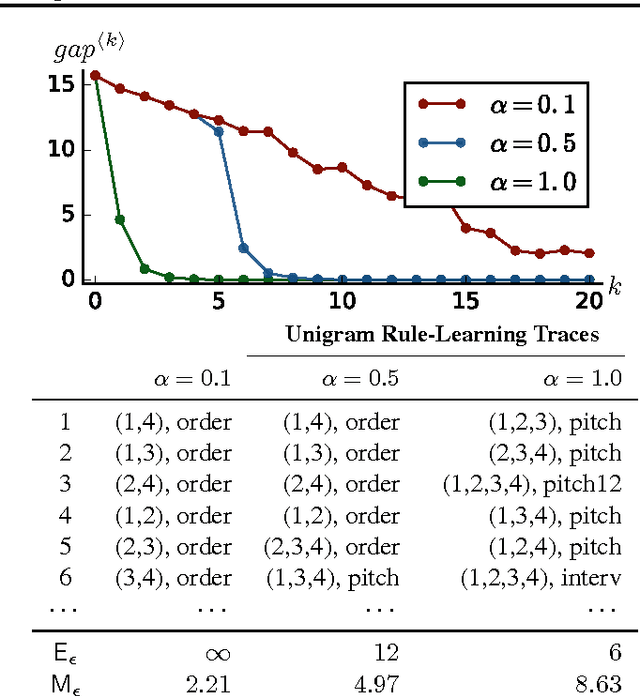
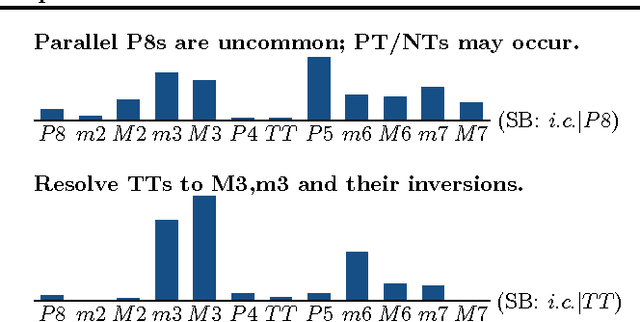
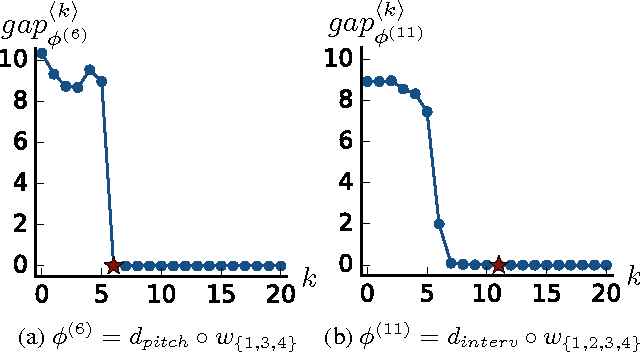
Throughout music history, theorists have identified and documented interpretable rules that capture the decisions of composers. This paper asks, "Can a machine behave like a music theorist?" It presents MUS-ROVER, a self-learning system for automatically discovering rules from symbolic music. MUS-ROVER performs feature learning via $n$-gram models to extract compositional rules --- statistical patterns over the resulting features. We evaluate MUS-ROVER on Bach's (SATB) chorales, demonstrating that it can recover known rules, as well as identify new, characteristic patterns for further study. We discuss how the extracted rules can be used in both machine and human composition.