 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLayerwise Dynamics for In-Context Classification in Transformers
Apr 13, 2026Transformers can perform in-context classification from a few labeled examples, yet the inference-time algorithm remains opaque. We study multi-class linear classification in the hard no-margin regime and make the computation identifiable by enforcing feature- and label-permutation equivariance at every layer. This enables interpretability while maintaining functional equivalence and yields highly structured weights. From these models we extract an explicit depth-indexed recursion: an end-to-end identified, emergent update rule inside a softmax transformer, to our knowledge the first of its kind. Attention matrices formed from mixed feature-label Gram structure drive coupled updates of training points, labels, and the test probe. The resulting dynamics implement a geometry-driven algorithmic motif, which can provably amplify class separation and yields robust expected class alignment.
Hearing Between the Lines: Unlocking the Reasoning Power of LLMs for Speech Evaluation
Jan 24, 2026Large Language Model (LLM) judges exhibit strong reasoning capabilities but are limited to textual content. This leaves current automatic Speech-to-Speech (S2S) evaluation methods reliant on opaque and expensive Audio Language Models (ALMs). In this work, we propose TRACE (Textual Reasoning over Audio Cues for Evaluation), a novel framework that enables LLM judges to reason over audio cues to achieve cost-efficient and human-aligned S2S evaluation. To demonstrate the strength of the framework, we first introduce a Human Chain-of-Thought (HCoT) annotation protocol to improve the diagnostic capability of existing judge benchmarks by separating evaluation into explicit dimensions: content (C), voice quality (VQ), and paralinguistics (P). Using this data, TRACE constructs a textual blueprint of inexpensive audio signals and prompts an LLM to render dimension-wise judgments, fusing them into an overall rating via a deterministic policy. TRACE achieves higher agreement with human raters than ALMs and transcript-only LLM judges while being significantly more cost-effective. We will release the HCoT annotations and the TRACE framework to enable scalable and human-aligned S2S evaluation.
Dimension-First Evaluation of Speech-to-Speech Models with Structured Acoustic Cues
Jan 20, 2026Large Language Model (LLM) judges exhibit strong reasoning capabilities but are limited to textual content. This leaves current automatic Speech-to-Speech (S2S) evaluation methods reliant on opaque and expensive Audio Language Models (ALMs). In this work, we propose TRACE (Textual Reasoning over Audio Cues for Evaluation), a novel framework that enables LLM judges to reason over audio cues to achieve cost-efficient and human-aligned S2S evaluation. To demonstrate the strength of the framework, we first introduce a Human Chain-of-Thought (HCoT) annotation protocol to improve the diagnostic capability of existing judge benchmarks by separating evaluation into explicit dimensions: content (C), voice quality (VQ), and paralinguistics (P). Using this data, TRACE constructs a textual blueprint of inexpensive audio signals and prompts an LLM to render dimension-wise judgments, fusing them into an overall rating via a deterministic policy. TRACE achieves higher agreement with human raters than ALMs and transcript-only LLM judges while being significantly more cost-effective. We will release the HCoT annotations and the TRACE framework to enable scalable and human-aligned S2S evaluation.
BabyVLM-V2: Toward Developmentally Grounded Pretraining and Benchmarking of Vision Foundation Models
Dec 11, 2025Early children's developmental trajectories set up a natural goal for sample-efficient pretraining of vision foundation models. We introduce BabyVLM-V2, a developmentally grounded framework for infant-inspired vision-language modeling that extensively improves upon BabyVLM-V1 through a longitudinal, multifaceted pretraining set, a versatile model, and, most importantly, DevCV Toolbox for cognitive evaluation. The pretraining set maximizes coverage while minimizing curation of a longitudinal, infant-centric audiovisual corpus, yielding video-utterance, image-utterance, and multi-turn conversational data that mirror infant experiences. DevCV Toolbox adapts all vision-related measures of the recently released NIH Baby Toolbox into a benchmark suite of ten multimodal tasks, covering spatial reasoning, memory, and vocabulary understanding aligned with early children's capabilities. Experimental results show that a compact model pretrained from scratch can achieve competitive performance on DevCV Toolbox, outperforming GPT-4o on some tasks. We hope the principled, unified BabyVLM-V2 framework will accelerate research in developmentally plausible pretraining of vision foundation models.
BabyVLM: Data-Efficient Pretraining of VLMs Inspired by Infant Learning
Apr 13, 2025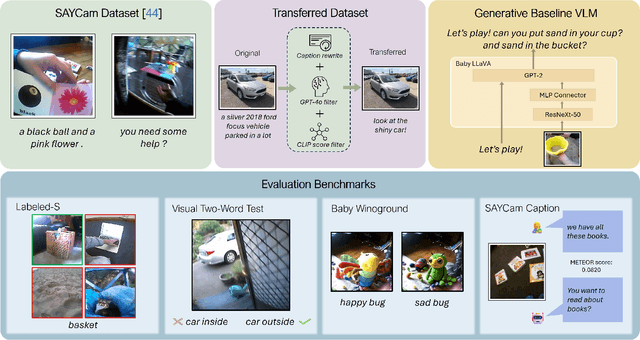

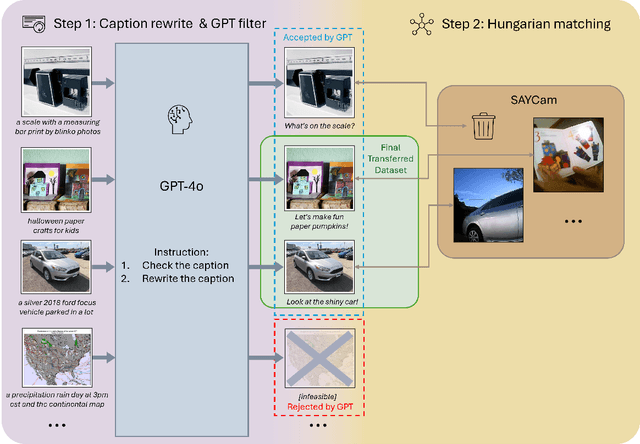

Human infants rapidly develop visual reasoning skills from minimal input, suggesting that developmentally inspired pretraining could significantly enhance the efficiency of vision-language models (VLMs). Although recent efforts have leveraged infant-inspired datasets like SAYCam, existing evaluation benchmarks remain misaligned--they are either too simplistic, narrowly scoped, or tailored for large-scale pretrained models. Additionally, training exclusively on infant data overlooks the broader, diverse input from which infants naturally learn. To address these limitations, we propose BabyVLM, a novel framework comprising comprehensive in-domain evaluation benchmarks and a synthetic training dataset created via child-directed transformations of existing datasets. We demonstrate that VLMs trained with our synthetic dataset achieve superior performance on BabyVLM tasks compared to models trained solely on SAYCam or general-purpose data of the SAYCam size. BabyVLM thus provides a robust, developmentally aligned evaluation tool and illustrates how compact models trained on carefully curated data can generalize effectively, opening pathways toward data-efficient vision-language learning paradigms.
Enhancing Compositional Reasoning in Vision-Language Models with Synthetic Preference Data
Apr 07, 2025



Compositionality, or correctly recognizing scenes as compositions of atomic visual concepts, remains difficult for multimodal large language models (MLLMs). Even state of the art MLLMs such as GPT-4o can make mistakes in distinguishing compositions like "dog chasing cat" vs "cat chasing dog". While on Winoground, a benchmark for measuring such reasoning, MLLMs have made significant progress, they are still far from a human's performance. We show that compositional reasoning in these models can be improved by elucidating such concepts via data, where a model is trained to prefer the correct caption for an image over a close but incorrect one. We introduce SCRAMBLe: Synthetic Compositional Reasoning Augmentation of MLLMs with Binary preference Learning, an approach for preference tuning open-weight MLLMs on synthetic preference data generated in a fully automated manner from existing image-caption data. SCRAMBLe holistically improves these MLLMs' compositional reasoning capabilities which we can see through significant improvements across multiple vision language compositionality benchmarks, as well as smaller but significant improvements on general question answering tasks. As a sneak peek, SCRAMBLe tuned Molmo-7B model improves on Winoground from 49.5% to 54.8% (best reported to date), while improving by ~1% on more general visual question answering tasks. Code for SCRAMBLe along with tuned models and our synthetic training dataset is available at https://github.com/samarth4149/SCRAMBLe.
Constrained Linear Thompson Sampling
Mar 03, 2025We study the safe linear bandit problem, where an agent sequentially selects actions from a convex domain to maximize an unknown objective while ensuring unknown linear constraints are satisfied on a per-round basis. Existing approaches primarily rely on optimism-based methods with frequentist confidence bounds, often leading to computationally expensive action selection routines. We propose COnstrained Linear Thompson Sampling (COLTS), a sampling-based framework that efficiently balances regret minimization and constraint satisfaction by selecting actions on the basis of noisy perturbations of the estimates of the unknown objective vector and constraint matrix. We introduce three variants of COLTS, distinguished by the learner's available side information: - S-COLTS assumes access to a known safe action and ensures strict constraint enforcement by combining the COLTS approach with a rescaling towards the safe action. For $d$-dimensional actions, this yields $\tilde{O}(\sqrt{d^3 T})$ regret and zero constraint violations (or risk). - E-COLTS enforces constraints softly under Slater's condition, and attains regret and risk of $\tilde{O}(\sqrt{d^3 T})$ by combining COLTS with uniform exploration. - R-COLTS requires no side information, and ensures instance-independent regret and risk of $\tilde{O}(\sqrt{d^3 T})$ by leveraging repeated resampling. A key technical innovation is a coupled noise design, which maintains optimism while preserving computational efficiency, which is combined with a scaling based analysis technique to address the variation of the per-round feasible region induced by sampled constraint matrices. Our methods match the regret bounds of prior approaches, while significantly reducing computational costs compared to them, thus yielding a scalable and practical approach for constrained bandit linear optimization.
SPARC: Score Prompting and Adaptive Fusion for Zero-Shot Multi-Label Recognition in Vision-Language Models
Feb 24, 2025
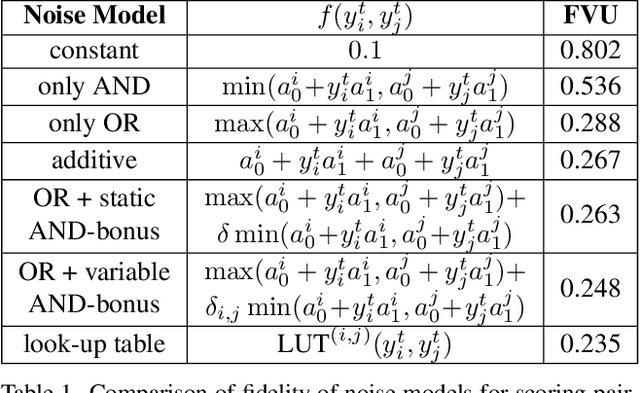
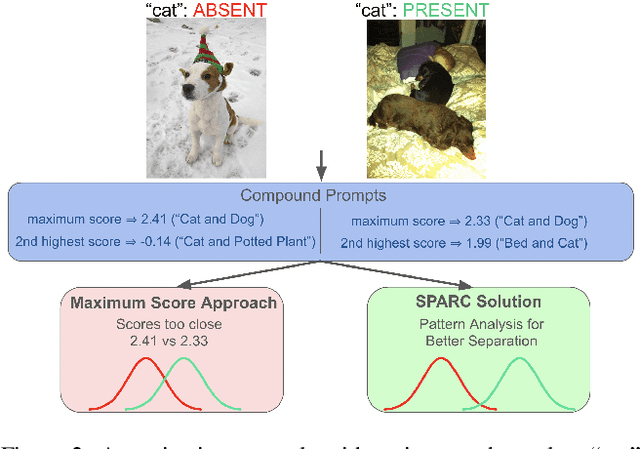
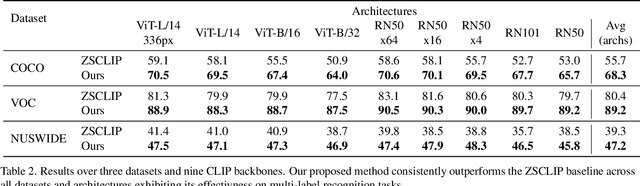
Zero-shot multi-label recognition (MLR) with Vision-Language Models (VLMs) faces significant challenges without training data, model tuning, or architectural modifications. Existing approaches require prompt tuning or architectural adaptations, limiting zero-shot applicability. Our work proposes a novel solution treating VLMs as black boxes, leveraging scores without training data or ground truth. Using large language model insights on object co-occurrence, we introduce compound prompts grounded in realistic object combinations. Analysis of these prompt scores reveals VLM biases and ``AND''/``OR'' signal ambiguities, notably that maximum compound scores are surprisingly suboptimal compared to second-highest scores. We address these through a debiasing and score-fusion algorithm that corrects image bias and clarifies VLM response behaviors. Our method enhances other zero-shot approaches, consistently improving their results. Experiments show superior mean Average Precision (mAP) compared to methods requiring training data, achieved through refined object ranking for robust zero-shot MLR.
Deep Companion Learning: Enhancing Generalization Through Historical Consistency
Jul 26, 2024



We propose Deep Companion Learning (DCL), a novel training method for Deep Neural Networks (DNNs) that enhances generalization by penalizing inconsistent model predictions compared to its historical performance. To achieve this, we train a deep-companion model (DCM), by using previous versions of the model to provide forecasts on new inputs. This companion model deciphers a meaningful latent semantic structure within the data, thereby providing targeted supervision that encourages the primary model to address the scenarios it finds most challenging. We validate our approach through both theoretical analysis and extensive experimentation, including ablation studies, on a variety of benchmark datasets (CIFAR-100, Tiny-ImageNet, ImageNet-1K) using diverse architectural models (ShuffleNetV2, ResNet, Vision Transformer, etc.), demonstrating state-of-the-art performance.
Testing the Feasibility of Linear Programs with Bandit Feedback
Jun 21, 2024

While the recent literature has seen a surge in the study of constrained bandit problems, all existing methods for these begin by assuming the feasibility of the underlying problem. We initiate the study of testing such feasibility assumptions, and in particular address the problem in the linear bandit setting, thus characterising the costs of feasibility testing for an unknown linear program using bandit feedback. Concretely, we test if $\exists x: Ax \ge 0$ for an unknown $A \in \mathbb{R}^{m \times d}$, by playing a sequence of actions $x_t\in \mathbb{R}^d$, and observing $Ax_t + \mathrm{noise}$ in response. By identifying the hypothesis as determining the sign of the value of a minimax game, we construct a novel test based on low-regret algorithms and a nonasymptotic law of iterated logarithms. We prove that this test is reliable, and adapts to the `signal level,' $\Gamma,$ of any instance, with mean sample costs scaling as $\widetilde{O}(d^2/\Gamma^2)$. We complement this by a minimax lower bound of $\Omega(d/\Gamma^2)$ for sample costs of reliable tests, dominating prior asymptotic lower bounds by capturing the dependence on $d$, and thus elucidating a basic insight missing in the extant literature on such problems.