 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHearing Between the Lines: Unlocking the Reasoning Power of LLMs for Speech Evaluation
Jan 24, 2026Large Language Model (LLM) judges exhibit strong reasoning capabilities but are limited to textual content. This leaves current automatic Speech-to-Speech (S2S) evaluation methods reliant on opaque and expensive Audio Language Models (ALMs). In this work, we propose TRACE (Textual Reasoning over Audio Cues for Evaluation), a novel framework that enables LLM judges to reason over audio cues to achieve cost-efficient and human-aligned S2S evaluation. To demonstrate the strength of the framework, we first introduce a Human Chain-of-Thought (HCoT) annotation protocol to improve the diagnostic capability of existing judge benchmarks by separating evaluation into explicit dimensions: content (C), voice quality (VQ), and paralinguistics (P). Using this data, TRACE constructs a textual blueprint of inexpensive audio signals and prompts an LLM to render dimension-wise judgments, fusing them into an overall rating via a deterministic policy. TRACE achieves higher agreement with human raters than ALMs and transcript-only LLM judges while being significantly more cost-effective. We will release the HCoT annotations and the TRACE framework to enable scalable and human-aligned S2S evaluation.
Dimension-First Evaluation of Speech-to-Speech Models with Structured Acoustic Cues
Jan 20, 2026Large Language Model (LLM) judges exhibit strong reasoning capabilities but are limited to textual content. This leaves current automatic Speech-to-Speech (S2S) evaluation methods reliant on opaque and expensive Audio Language Models (ALMs). In this work, we propose TRACE (Textual Reasoning over Audio Cues for Evaluation), a novel framework that enables LLM judges to reason over audio cues to achieve cost-efficient and human-aligned S2S evaluation. To demonstrate the strength of the framework, we first introduce a Human Chain-of-Thought (HCoT) annotation protocol to improve the diagnostic capability of existing judge benchmarks by separating evaluation into explicit dimensions: content (C), voice quality (VQ), and paralinguistics (P). Using this data, TRACE constructs a textual blueprint of inexpensive audio signals and prompts an LLM to render dimension-wise judgments, fusing them into an overall rating via a deterministic policy. TRACE achieves higher agreement with human raters than ALMs and transcript-only LLM judges while being significantly more cost-effective. We will release the HCoT annotations and the TRACE framework to enable scalable and human-aligned S2S evaluation.
SPARC: Score Prompting and Adaptive Fusion for Zero-Shot Multi-Label Recognition in Vision-Language Models
Feb 24, 2025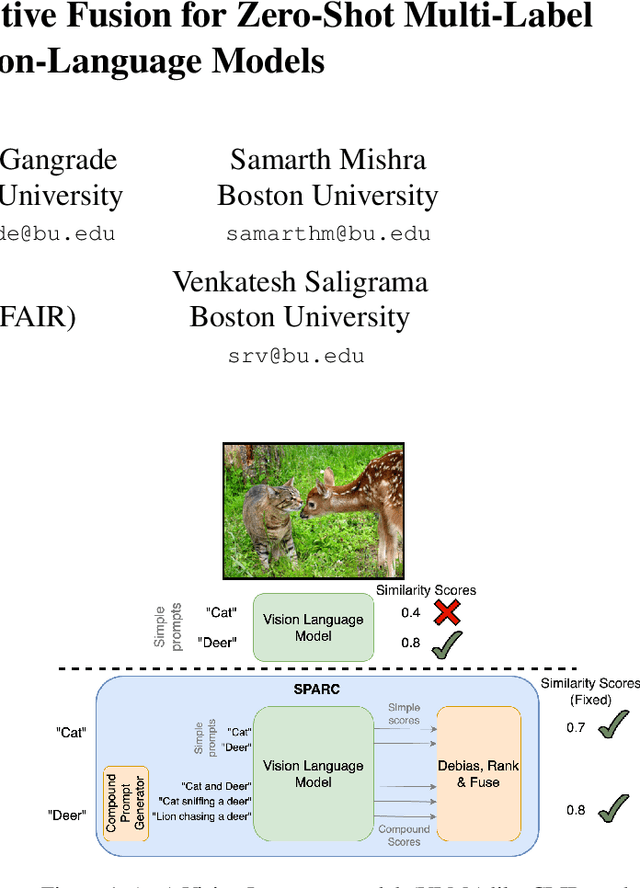
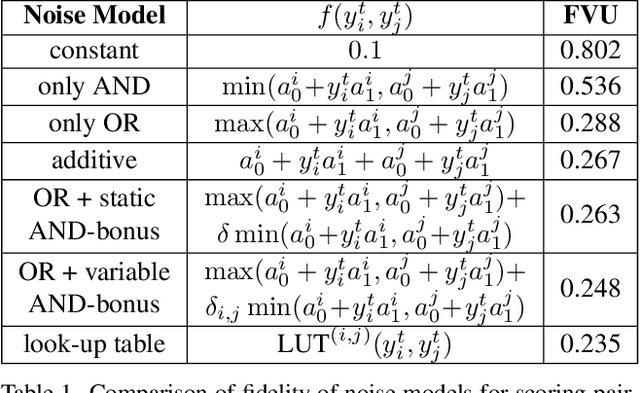
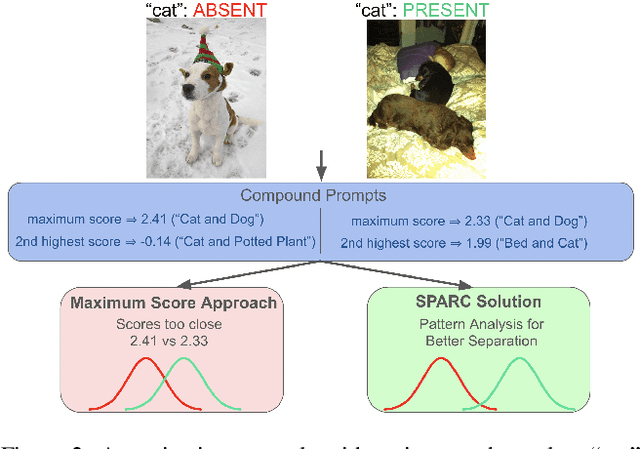
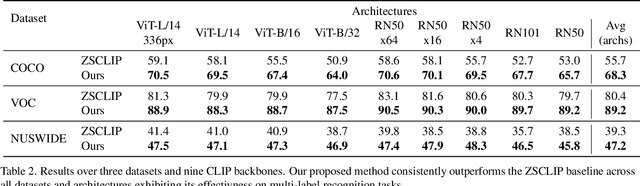
Zero-shot multi-label recognition (MLR) with Vision-Language Models (VLMs) faces significant challenges without training data, model tuning, or architectural modifications. Existing approaches require prompt tuning or architectural adaptations, limiting zero-shot applicability. Our work proposes a novel solution treating VLMs as black boxes, leveraging scores without training data or ground truth. Using large language model insights on object co-occurrence, we introduce compound prompts grounded in realistic object combinations. Analysis of these prompt scores reveals VLM biases and ``AND''/``OR'' signal ambiguities, notably that maximum compound scores are surprisingly suboptimal compared to second-highest scores. We address these through a debiasing and score-fusion algorithm that corrects image bias and clarifies VLM response behaviors. Our method enhances other zero-shot approaches, consistently improving their results. Experiments show superior mean Average Precision (mAP) compared to methods requiring training data, achieved through refined object ranking for robust zero-shot MLR.
MALADY: Multiclass Active Learning with Auction Dynamics on Graphs
Sep 14, 2024


Active learning enhances the performance of machine learning methods, particularly in semi-supervised cases, by judiciously selecting a limited number of unlabeled data points for labeling, with the goal of improving the performance of an underlying classifier. In this work, we introduce the Multiclass Active Learning with Auction Dynamics on Graphs (MALADY) framework which leverages the auction dynamics algorithm on similarity graphs for efficient active learning. In particular, we generalize the auction dynamics algorithm on similarity graphs for semi-supervised learning in [24] to incorporate a more general optimization functional. Moreover, we introduce a novel active learning acquisition function that uses the dual variable of the auction algorithm to measure the uncertainty in the classifier to prioritize queries near the decision boundaries between different classes. Lastly, using experiments on classification tasks, we evaluate the performance of our proposed method and show that it exceeds that of comparison algorithms.
Dirichlet Active Learning
Nov 09, 2023



This work introduces Dirichlet Active Learning (DiAL), a Bayesian-inspired approach to the design of active learning algorithms. Our framework models feature-conditional class probabilities as a Dirichlet random field and lends observational strength between similar features in order to calibrate the random field. This random field can then be utilized in learning tasks: in particular, we can use current estimates of mean and variance to conduct classification and active learning in the context where labeled data is scarce. We demonstrate the applicability of this model to low-label rate graph learning by constructing ``propagation operators'' based upon the graph Laplacian, and offer computational studies demonstrating the method's competitiveness with the state of the art. Finally, we provide rigorous guarantees regarding the ability of this approach to ensure both exploration and exploitation, expressed respectively in terms of cluster exploration and increased attention to decision boundaries.
Cluster-aware Semi-supervised Learning: Relational Knowledge Distillation Provably Learns Clustering
Jul 20, 2023


Despite the empirical success and practical significance of (relational) knowledge distillation that matches (the relations of) features between teacher and student models, the corresponding theoretical interpretations remain limited for various knowledge distillation paradigms. In this work, we take an initial step toward a theoretical understanding of relational knowledge distillation (RKD), with a focus on semi-supervised classification problems. We start by casting RKD as spectral clustering on a population-induced graph unveiled by a teacher model. Via a notion of clustering error that quantifies the discrepancy between the predicted and ground truth clusterings, we illustrate that RKD over the population provably leads to low clustering error. Moreover, we provide a sample complexity bound for RKD with limited unlabeled samples. For semi-supervised learning, we further demonstrate the label efficiency of RKD through a general framework of cluster-aware semi-supervised learning that assumes low clustering errors. Finally, by unifying data augmentation consistency regularization into this cluster-aware framework, we show that despite the common effect of learning accurate clusterings, RKD facilitates a "global" perspective through spectral clustering, whereas consistency regularization focuses on a "local" perspective via expansion.
Novel Batch Active Learning Approach and Its Application to Synthetic Aperture Radar Datasets
Jul 19, 2023Active learning improves the performance of machine learning methods by judiciously selecting a limited number of unlabeled data points to query for labels, with the aim of maximally improving the underlying classifier's performance. Recent gains have been made using sequential active learning for synthetic aperture radar (SAR) data arXiv:2204.00005. In each iteration, sequential active learning selects a query set of size one while batch active learning selects a query set of multiple datapoints. While batch active learning methods exhibit greater efficiency, the challenge lies in maintaining model accuracy relative to sequential active learning methods. We developed a novel, two-part approach for batch active learning: Dijkstra's Annulus Core-Set (DAC) for core-set generation and LocalMax for batch sampling. The batch active learning process that combines DAC and LocalMax achieves nearly identical accuracy as sequential active learning but is more efficient, proportional to the batch size. As an application, a pipeline is built based on transfer learning feature embedding, graph learning, DAC, and LocalMax to classify the FUSAR-Ship and OpenSARShip datasets. Our pipeline outperforms the state-of-the-art CNN-based methods.
* 16 pages, 7 figures, Preprint
Graph-based Active Learning for Surface Water and Sediment Detection in Multispectral Images
Jun 17, 2023We develop a graph active learning pipeline (GAP) to detect surface water and in-river sediment pixels in satellite images. The active learning approach is applied within the training process to optimally select specific pixels to generate a hand-labeled training set. Our method obtains higher accuracy with far fewer training pixels than both standard and deep learning models. According to our experiments, our GAP trained on a set of 3270 pixels reaches a better accuracy than the neural network method trained on 2.1 million pixels.
Poisson Reweighted Laplacian Uncertainty Sampling for Graph-based Active Learning
Oct 27, 2022We show that uncertainty sampling is sufficient to achieve exploration versus exploitation in graph-based active learning, as long as the measure of uncertainty properly aligns with the underlying model and the model properly reflects uncertainty in unexplored regions. In particular, we use a recently developed algorithm, Poisson ReWeighted Laplace Learning (PWLL) for the classifier and we introduce an acquisition function designed to measure uncertainty in this graph-based classifier that identifies unexplored regions of the data. We introduce a diagonal perturbation in PWLL which produces exponential localization of solutions, and controls the exploration versus exploitation tradeoff in active learning. We use the well-posed continuum limit of PWLL to rigorously analyze our method, and present experimental results on a number of graph-based image classification problems.
Graph-based Active Learning for Semi-supervised Classification of SAR Data
Mar 31, 2022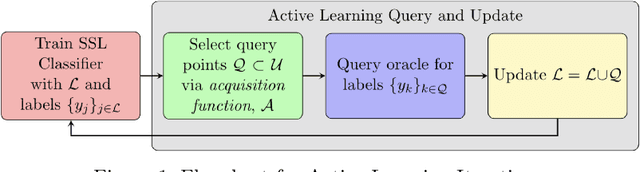


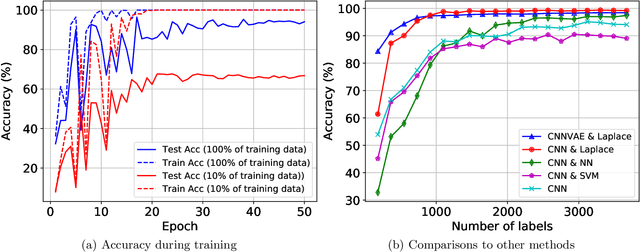
We present a novel method for classification of Synthetic Aperture Radar (SAR) data by combining ideas from graph-based learning and neural network methods within an active learning framework. Graph-based methods in machine learning are based on a similarity graph constructed from the data. When the data consists of raw images composed of scenes, extraneous information can make the classification task more difficult. In recent years, neural network methods have been shown to provide a promising framework for extracting patterns from SAR images. These methods, however, require ample training data to avoid overfitting. At the same time, such training data are often unavailable for applications of interest, such as automatic target recognition (ATR) and SAR data. We use a Convolutional Neural Network Variational Autoencoder (CNNVAE) to embed SAR data into a feature space, and then construct a similarity graph from the embedded data and apply graph-based semi-supervised learning techniques. The CNNVAE feature embedding and graph construction requires no labeled data, which reduces overfitting and improves the generalization performance of graph learning at low label rates. Furthermore, the method easily incorporates a human-in-the-loop for active learning in the data-labeling process. We present promising results and compare them to other standard machine learning methods on the Moving and Stationary Target Acquisition and Recognition (MSTAR) dataset for ATR with small amounts of labeled data.