 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA General Framework for Group Sparsity in Hyperspectral Unmixing Using Endmember Bundles
May 20, 2025Due to low spatial resolution, hyperspectral data often consists of mixtures of contributions from multiple materials. This limitation motivates the task of hyperspectral unmixing (HU), a fundamental problem in hyperspectral imaging. HU aims to identify the spectral signatures (\textit{endmembers}) of the materials present in an observed scene, along with their relative proportions (\textit{fractional abundance}) in each pixel. A major challenge lies in the class variability in materials, which hinders accurate representation by a single spectral signature, as assumed in the conventional linear mixing model. Moreover, To address this issue, we propose using group sparsity after representing each material with a set of spectral signatures, known as endmember bundles, where each group corresponds to a specific material. In particular, we develop a bundle-based framework that can enforce either inter-group sparsity or sparsity within and across groups (SWAG) on the abundance coefficients. Furthermore, our framework offers the flexibility to incorporate a variety of sparsity-promoting penalties, among which the transformed $\ell_1$ (TL1) penalty is a novel regularization in the HU literature. Extensive experiments conducted on both synthetic and real hyperspectral data demonstrate the effectiveness and superiority of the proposed approaches.
Detection and tracking of gas plumes in LWIR hyperspectral video sequence data
Nov 01, 2024Automated detection of chemical plumes presents a segmentation challenge. The segmentation problem for gas plumes is difficult due to the diffusive nature of the cloud. The advantage of considering hyperspectral images in the gas plume detection problem over the conventional RGB imagery is the presence of non-visual data, allowing for a richer representation of information. In this paper we present an effective method of visualizing hyperspectral video sequences containing chemical plumes and investigate the effectiveness of segmentation techniques on these post-processed videos. Our approach uses a combination of dimension reduction and histogram equalization to prepare the hyperspectral videos for segmentation. First, Principal Components Analysis (PCA) is used to reduce the dimension of the entire video sequence. This is done by projecting each pixel onto the first few Principal Components resulting in a type of spectral filter. Next, a Midway method for histogram equalization is used. These methods redistribute the intensity values in order to reduce flicker between frames. This properly prepares these high-dimensional video sequences for more traditional segmentation techniques. We compare the ability of various clustering techniques to properly segment the chemical plume. These include K-means, spectral clustering, and the Ginzburg-Landau functional.
MALADY: Multiclass Active Learning with Auction Dynamics on Graphs
Sep 14, 2024


Active learning enhances the performance of machine learning methods, particularly in semi-supervised cases, by judiciously selecting a limited number of unlabeled data points for labeling, with the goal of improving the performance of an underlying classifier. In this work, we introduce the Multiclass Active Learning with Auction Dynamics on Graphs (MALADY) framework which leverages the auction dynamics algorithm on similarity graphs for efficient active learning. In particular, we generalize the auction dynamics algorithm on similarity graphs for semi-supervised learning in [24] to incorporate a more general optimization functional. Moreover, we introduce a novel active learning acquisition function that uses the dual variable of the auction algorithm to measure the uncertainty in the classifier to prioritize queries near the decision boundaries between different classes. Lastly, using experiments on classification tasks, we evaluate the performance of our proposed method and show that it exceeds that of comparison algorithms.
Graph-Based Bidirectional Transformer Decision Threshold Adjustment Algorithm for Class-Imbalanced Molecular Data
Jun 10, 2024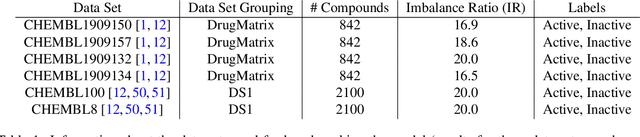
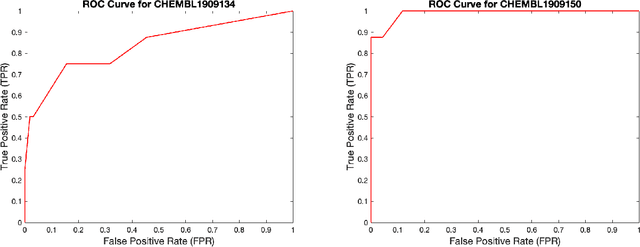
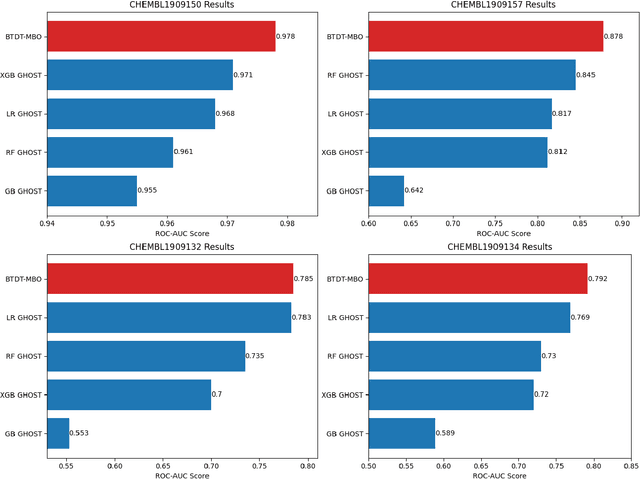
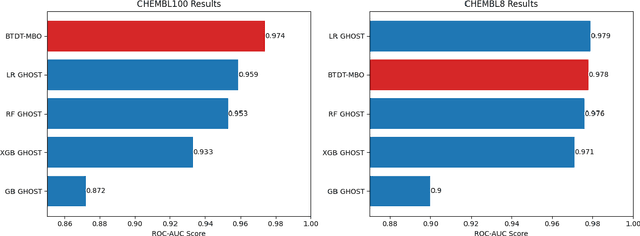
Data sets with imbalanced class sizes, often where one class size is much smaller than that of others, occur extremely often in various applications, including those with biological foundations, such as drug discovery and disease diagnosis. Thus, it is extremely important to be able to identify data elements of classes of various sizes, as a failure to detect can result in heavy costs. However, many data classification algorithms do not perform well on imbalanced data sets as they often fail to detect elements belonging to underrepresented classes. In this paper, we propose the BTDT-MBO algorithm, incorporating Merriman-Bence-Osher (MBO) techniques and a bidirectional transformer, as well as distance correlation and decision threshold adjustments, for data classification problems on highly imbalanced molecular data sets, where the sizes of the classes vary greatly. The proposed method not only integrates adjustments in the classification threshold for the MBO algorithm in order to help deal with the class imbalance, but also uses a bidirectional transformer model based on an attention mechanism for self-supervised learning. Additionally, the method implements distance correlation as a weight function for the similarity graph-based framework on which the adjusted MBO algorithm operates. The proposed model is validated using six molecular data sets, and we also provide a thorough comparison to other competing algorithms. The computational experiments show that the proposed method performs better than competing techniques even when the class imbalance ratio is very high.
Persistent Laplacian-enhanced Algorithm for Scarcely Labeled Data Classification
May 25, 2023The success of many machine learning (ML) methods depends crucially on having large amounts of labeled data. However, obtaining enough labeled data can be expensive, time-consuming, and subject to ethical constraints for many applications. One approach that has shown tremendous value in addressing this challenge is semi-supervised learning (SSL); this technique utilizes both labeled and unlabeled data during training, often with much less labeled data than unlabeled data, which is often relatively easy and inexpensive to obtain. In fact, SSL methods are particularly useful in applications where the cost of labeling data is especially expensive, such as medical analysis, natural language processing (NLP), or speech recognition. A subset of SSL methods that have achieved great success in various domains involves algorithms that integrate graph-based techniques. These procedures are popular due to the vast amount of information provided by the graphical framework and the versatility of their applications. In this work, we propose an algebraic topology-based semi-supervised method called persistent Laplacian-enhanced graph MBO (PL-MBO) by integrating persistent spectral graph theory with the classical Merriman-Bence- Osher (MBO) scheme. Specifically, we use a filtration procedure to generate a sequence of chain complexes and associated families of simplicial complexes, from which we construct a family of persistent Laplacians. Overall, it is a very efficient procedure that requires much less labeled data to perform well compared to many ML techniques, and it can be adapted for both small and large datasets. We evaluate the performance of the proposed method on data classification, and the results indicate that the proposed technique outperforms other existing semi-supervised algorithms.
Integrating Transformer and Autoencoder Techniques with Spectral Graph Algorithms for the Prediction of Scarcely Labeled Molecular Data
Nov 12, 2022In molecular and biological sciences, experiments are expensive, time-consuming, and often subject to ethical constraints. Consequently, one often faces the challenging task of predicting desirable properties from small data sets or scarcely-labeled data sets. Although transfer learning can be advantageous, it requires the existence of a related large data set. This work introduces three graph-based models incorporating Merriman-Bence-Osher (MBO) techniques to tackle this challenge. Specifically, graph-based modifications of the MBO scheme is integrated with state-of-the-art techniques, including a home-made transformer and an autoencoder, in order to deal with scarcely-labeled data sets. In addition, a consensus technique is detailed. The proposed models are validated using five benchmark data sets. We also provide a thorough comparison to other competing methods, such as support vector machines, random forests, and gradient boosted decision trees, which are known for their good performance on small data sets. The performances of various methods are analyzed using residue-similarity (R-S) scores and R-S indices. Extensive computational experiments and theoretical analysis show that the new models perform very well even when as little as 1% of the data set is used as labeled data.
Multiscale Laplacian Learning
Sep 08, 2021
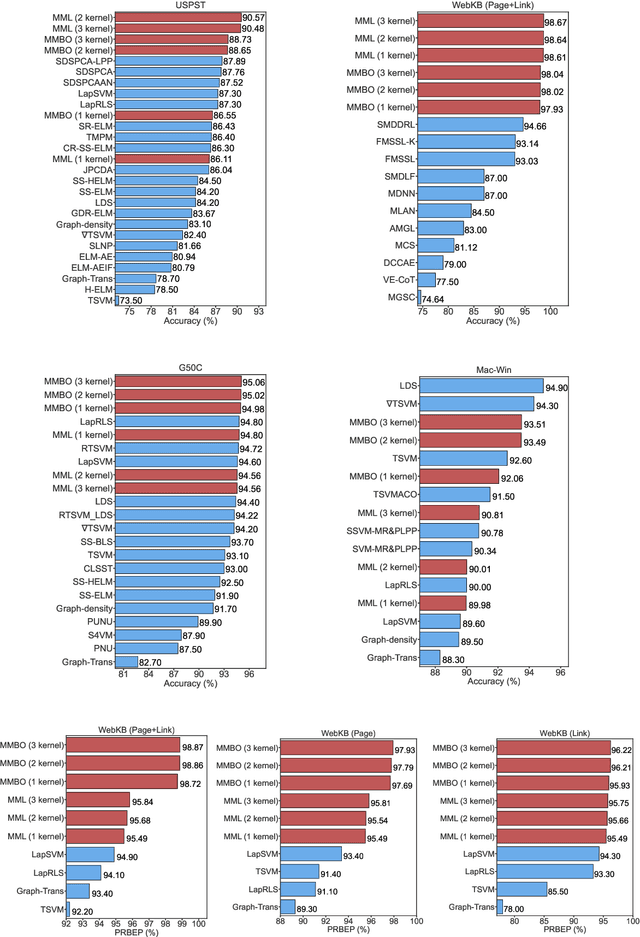
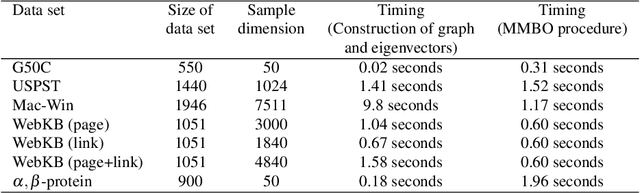
Machine learning methods have greatly changed science, engineering, finance, business, and other fields. Despite the tremendous accomplishments of machine learning and deep learning methods, many challenges still remain. In particular, the performance of machine learning methods is often severely affected in case of diverse data, usually associated with smaller data sets or data related to areas of study where the size of the data sets is constrained by the complexity and/or high cost of experiments. Moreover, data with limited labeled samples is a challenge to most learning approaches. In this paper, the aforementioned challenges are addressed by integrating graph-based frameworks, multiscale structure, modified and adapted optimization procedures and semi-supervised techniques. This results in two innovative multiscale Laplacian learning (MLL) approaches for machine learning tasks, such as data classification, and for tackling diverse data, data with limited samples and smaller data sets. The first approach, called multikernel manifold learning (MML), integrates manifold learning with multikernel information and solves a regularization problem consisting of a loss function and a warped kernel regularizer using multiscale graph Laplacians. The second approach, called the multiscale MBO (MMBO) method, introduces multiscale Laplacians to a modification of the famous classical Merriman-Bence-Osher (MBO) scheme, and makes use of fast solvers for finding the approximations to the extremal eigenvectors of the graph Laplacian. We demonstrate the performance of our methods experimentally on a variety of data sets, such as biological, text and image data, and compare them favorably to existing approaches.
Multiclass Data Segmentation using Diffuse Interface Methods on Graphs
Jan 17, 2014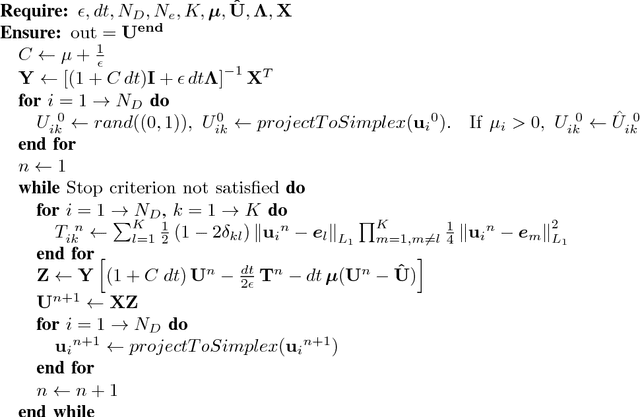
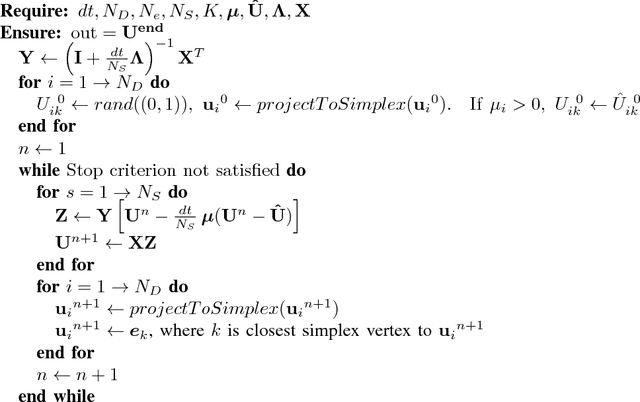
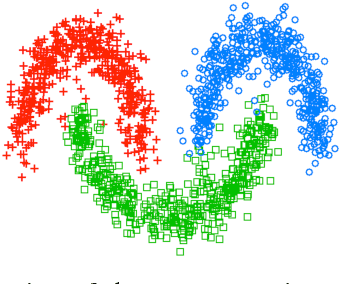

We present two graph-based algorithms for multiclass segmentation of high-dimensional data. The algorithms use a diffuse interface model based on the Ginzburg-Landau functional, related to total variation compressed sensing and image processing. A multiclass extension is introduced using the Gibbs simplex, with the functional's double-well potential modified to handle the multiclass case. The first algorithm minimizes the functional using a convex splitting numerical scheme. The second algorithm is a uses a graph adaptation of the classical numerical Merriman-Bence-Osher (MBO) scheme, which alternates between diffusion and thresholding. We demonstrate the performance of both algorithms experimentally on synthetic data, grayscale and color images, and several benchmark data sets such as MNIST, COIL and WebKB. We also make use of fast numerical solvers for finding the eigenvectors and eigenvalues of the graph Laplacian, and take advantage of the sparsity of the matrix. Experiments indicate that the results are competitive with or better than the current state-of-the-art multiclass segmentation algorithms.