 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGraph-Based Bidirectional Transformer Decision Threshold Adjustment Algorithm for Class-Imbalanced Molecular Data
Jun 10, 2024
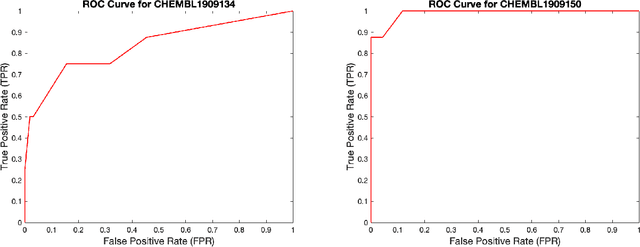
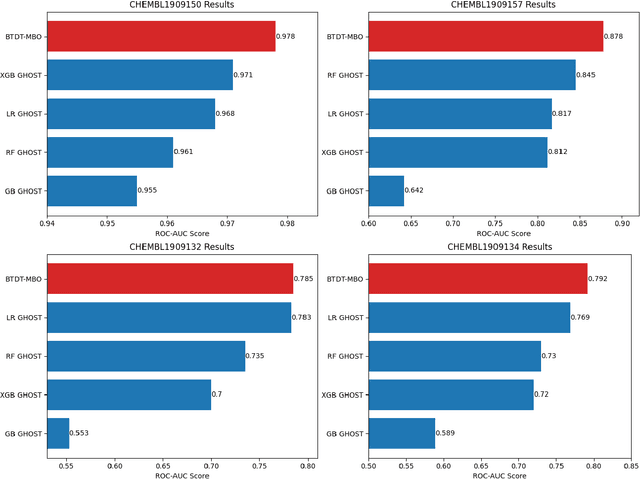
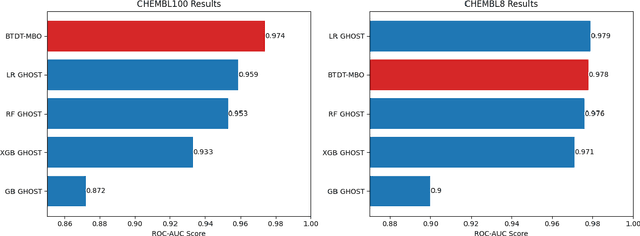
Data sets with imbalanced class sizes, often where one class size is much smaller than that of others, occur extremely often in various applications, including those with biological foundations, such as drug discovery and disease diagnosis. Thus, it is extremely important to be able to identify data elements of classes of various sizes, as a failure to detect can result in heavy costs. However, many data classification algorithms do not perform well on imbalanced data sets as they often fail to detect elements belonging to underrepresented classes. In this paper, we propose the BTDT-MBO algorithm, incorporating Merriman-Bence-Osher (MBO) techniques and a bidirectional transformer, as well as distance correlation and decision threshold adjustments, for data classification problems on highly imbalanced molecular data sets, where the sizes of the classes vary greatly. The proposed method not only integrates adjustments in the classification threshold for the MBO algorithm in order to help deal with the class imbalance, but also uses a bidirectional transformer model based on an attention mechanism for self-supervised learning. Additionally, the method implements distance correlation as a weight function for the similarity graph-based framework on which the adjusted MBO algorithm operates. The proposed model is validated using six molecular data sets, and we also provide a thorough comparison to other competing algorithms. The computational experiments show that the proposed method performs better than competing techniques even when the class imbalance ratio is very high.
Integrating Transformer and Autoencoder Techniques with Spectral Graph Algorithms for the Prediction of Scarcely Labeled Molecular Data
Nov 12, 2022In molecular and biological sciences, experiments are expensive, time-consuming, and often subject to ethical constraints. Consequently, one often faces the challenging task of predicting desirable properties from small data sets or scarcely-labeled data sets. Although transfer learning can be advantageous, it requires the existence of a related large data set. This work introduces three graph-based models incorporating Merriman-Bence-Osher (MBO) techniques to tackle this challenge. Specifically, graph-based modifications of the MBO scheme is integrated with state-of-the-art techniques, including a home-made transformer and an autoencoder, in order to deal with scarcely-labeled data sets. In addition, a consensus technique is detailed. The proposed models are validated using five benchmark data sets. We also provide a thorough comparison to other competing methods, such as support vector machines, random forests, and gradient boosted decision trees, which are known for their good performance on small data sets. The performances of various methods are analyzed using residue-similarity (R-S) scores and R-S indices. Extensive computational experiments and theoretical analysis show that the new models perform very well even when as little as 1% of the data set is used as labeled data.