 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhancing Compositional Reasoning in Vision-Language Models with Synthetic Preference Data
Apr 07, 2025



Compositionality, or correctly recognizing scenes as compositions of atomic visual concepts, remains difficult for multimodal large language models (MLLMs). Even state of the art MLLMs such as GPT-4o can make mistakes in distinguishing compositions like "dog chasing cat" vs "cat chasing dog". While on Winoground, a benchmark for measuring such reasoning, MLLMs have made significant progress, they are still far from a human's performance. We show that compositional reasoning in these models can be improved by elucidating such concepts via data, where a model is trained to prefer the correct caption for an image over a close but incorrect one. We introduce SCRAMBLe: Synthetic Compositional Reasoning Augmentation of MLLMs with Binary preference Learning, an approach for preference tuning open-weight MLLMs on synthetic preference data generated in a fully automated manner from existing image-caption data. SCRAMBLe holistically improves these MLLMs' compositional reasoning capabilities which we can see through significant improvements across multiple vision language compositionality benchmarks, as well as smaller but significant improvements on general question answering tasks. As a sneak peek, SCRAMBLe tuned Molmo-7B model improves on Winoground from 49.5% to 54.8% (best reported to date), while improving by ~1% on more general visual question answering tasks. Code for SCRAMBLe along with tuned models and our synthetic training dataset is available at https://github.com/samarth4149/SCRAMBLe.
SPARC: Score Prompting and Adaptive Fusion for Zero-Shot Multi-Label Recognition in Vision-Language Models
Feb 24, 2025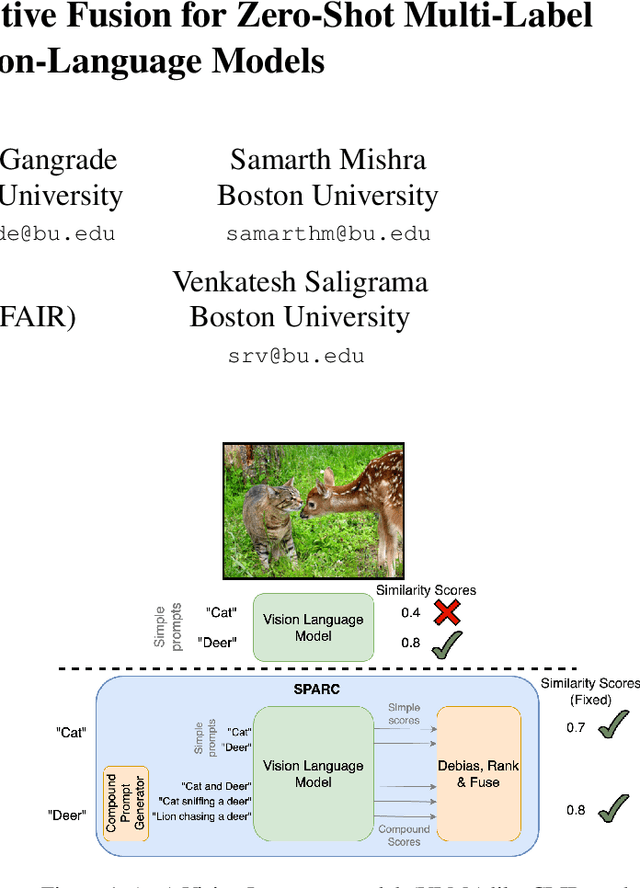
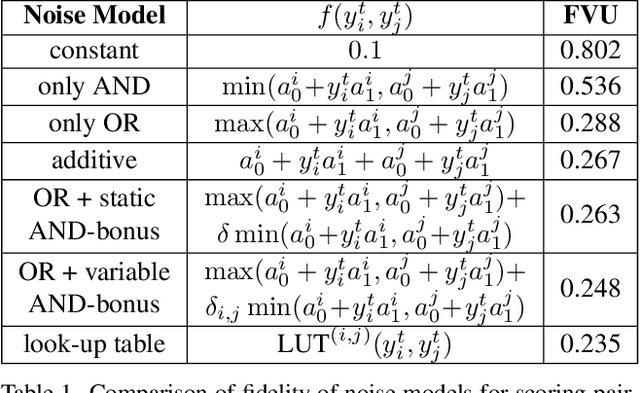
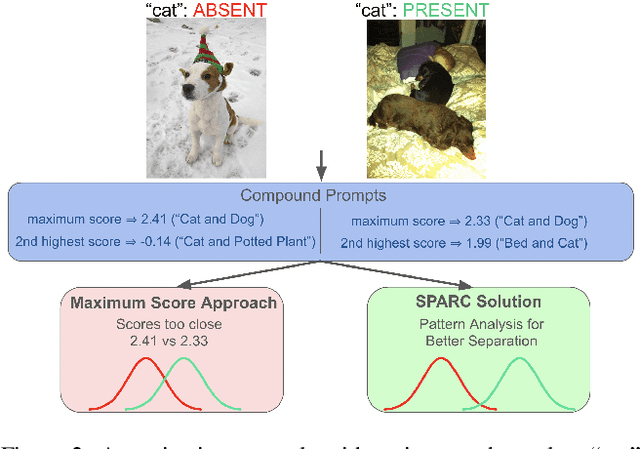
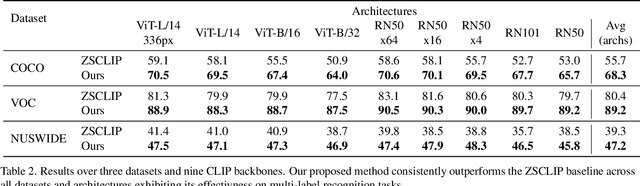
Zero-shot multi-label recognition (MLR) with Vision-Language Models (VLMs) faces significant challenges without training data, model tuning, or architectural modifications. Existing approaches require prompt tuning or architectural adaptations, limiting zero-shot applicability. Our work proposes a novel solution treating VLMs as black boxes, leveraging scores without training data or ground truth. Using large language model insights on object co-occurrence, we introduce compound prompts grounded in realistic object combinations. Analysis of these prompt scores reveals VLM biases and ``AND''/``OR'' signal ambiguities, notably that maximum compound scores are surprisingly suboptimal compared to second-highest scores. We address these through a debiasing and score-fusion algorithm that corrects image bias and clarifies VLM response behaviors. Our method enhances other zero-shot approaches, consistently improving their results. Experiments show superior mean Average Precision (mAP) compared to methods requiring training data, achieved through refined object ranking for robust zero-shot MLR.
SynCDR : Training Cross Domain Retrieval Models with Synthetic Data
Dec 31, 2023In cross-domain retrieval, a model is required to identify images from the same semantic category across two visual domains. For instance, given a sketch of an object, a model needs to retrieve a real image of it from an online store's catalog. A standard approach for such a problem is learning a feature space of images where Euclidean distances reflect similarity. Even without human annotations, which may be expensive to acquire, prior methods function reasonably well using unlabeled images for training. Our problem constraint takes this further to scenarios where the two domains do not necessarily share any common categories in training data. This can occur when the two domains in question come from different versions of some biometric sensor recording identities of different people. We posit a simple solution, which is to generate synthetic data to fill in these missing category examples across domains. This, we do via category preserving translation of images from one visual domain to another. We compare approaches specifically trained for this translation for a pair of domains, as well as those that can use large-scale pre-trained text-to-image diffusion models via prompts, and find that the latter can generate better replacement synthetic data, leading to more accurate cross-domain retrieval models. Code for our work is available at https://github.com/samarth4149/SynCDR .
Learning Human Action Recognition Representations Without Real Humans
Nov 10, 2023



Pre-training on massive video datasets has become essential to achieve high action recognition performance on smaller downstream datasets. However, most large-scale video datasets contain images of people and hence are accompanied with issues related to privacy, ethics, and data protection, often preventing them from being publicly shared for reproducible research. Existing work has attempted to alleviate these problems by blurring faces, downsampling videos, or training on synthetic data. On the other hand, analysis on the transferability of privacy-preserving pre-trained models to downstream tasks has been limited. In this work, we study this problem by first asking the question: can we pre-train models for human action recognition with data that does not include real humans? To this end, we present, for the first time, a benchmark that leverages real-world videos with humans removed and synthetic data containing virtual humans to pre-train a model. We then evaluate the transferability of the representation learned on this data to a diverse set of downstream action recognition benchmarks. Furthermore, we propose a novel pre-training strategy, called Privacy-Preserving MAE-Align, to effectively combine synthetic data and human-removed real data. Our approach outperforms previous baselines by up to 5% and closes the performance gap between human and no-human action recognition representations on downstream tasks, for both linear probing and fine-tuning. Our benchmark, code, and models are available at https://github.com/howardzh01/PPMA .
VisDA 2022 Challenge: Domain Adaptation for Industrial Waste Sorting
Mar 26, 2023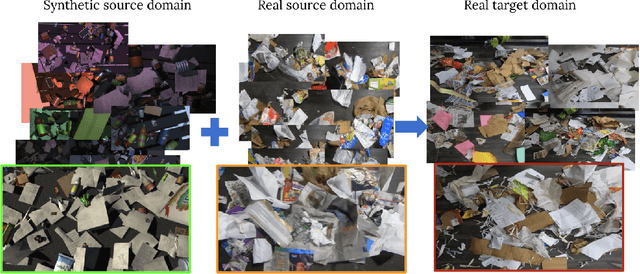
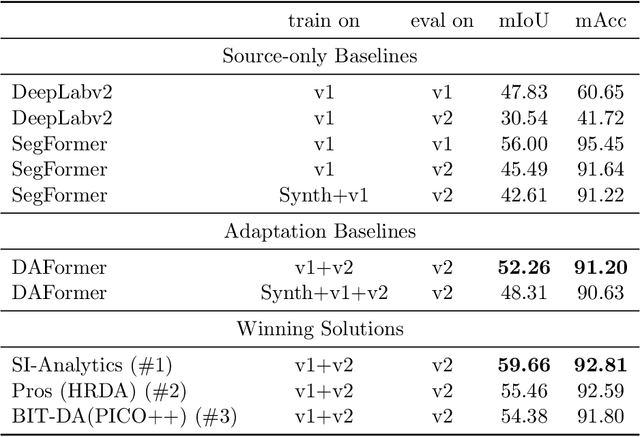
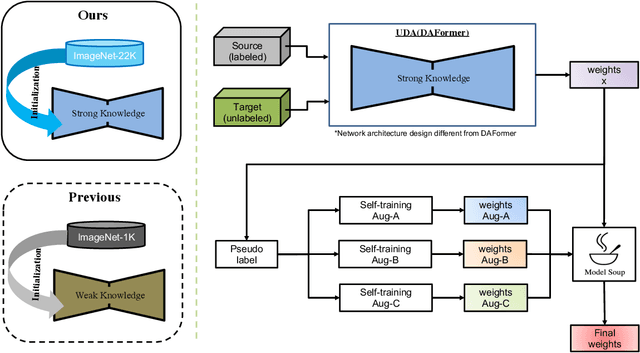

Label-efficient and reliable semantic segmentation is essential for many real-life applications, especially for industrial settings with high visual diversity, such as waste sorting. In industrial waste sorting, one of the biggest challenges is the extreme diversity of the input stream depending on factors like the location of the sorting facility, the equipment available in the facility, and the time of year, all of which significantly impact the composition and visual appearance of the waste stream. These changes in the data are called ``visual domains'', and label-efficient adaptation of models to such domains is needed for successful semantic segmentation of industrial waste. To test the abilities of computer vision models on this task, we present the VisDA 2022 Challenge on Domain Adaptation for Industrial Waste Sorting. Our challenge incorporates a fully-annotated waste sorting dataset, ZeroWaste, collected from two real material recovery facilities in different locations and seasons, as well as a novel procedurally generated synthetic waste sorting dataset, SynthWaste. In this competition, we aim to answer two questions: 1) can we leverage domain adaptation techniques to minimize the domain gap? and 2) can synthetic data augmentation improve performance on this task and help adapt to changing data distributions? The results of the competition show that industrial waste detection poses a real domain adaptation problem, that domain generalization techniques such as augmentations, ensembling, etc., improve the overall performance on the unlabeled target domain examples, and that leveraging synthetic data effectively remains an open problem. See https://ai.bu.edu/visda-2022/
Fine-grained Few-shot Recognition by Deep Object Parsing
Jul 14, 2022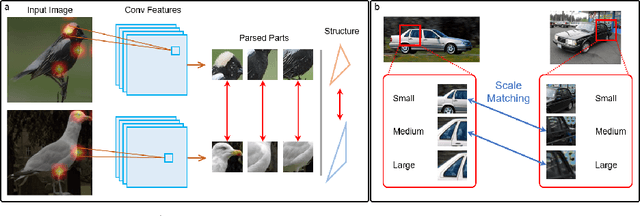
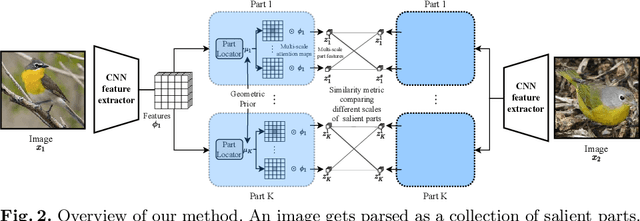
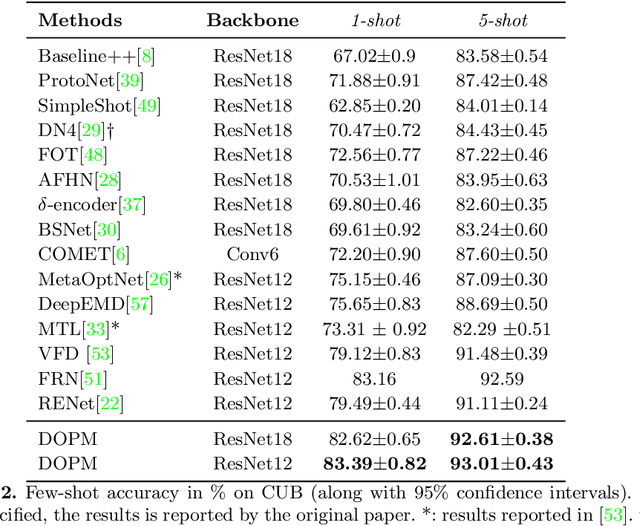
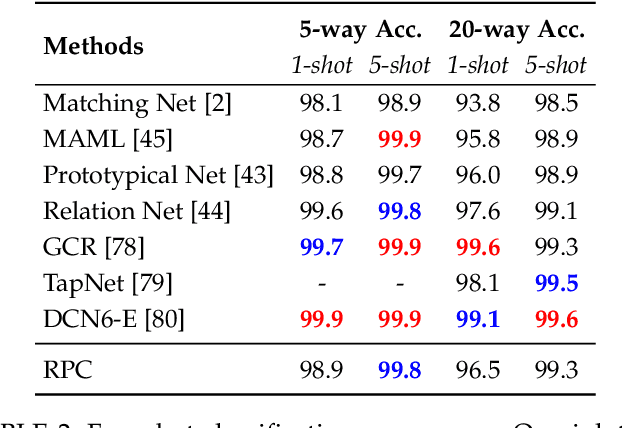
In our framework, an object is made up of K distinct parts or units, and we parse a test instance by inferring the K parts, where each part occupies a distinct location in the feature space, and the instance features at this location, manifest as an active subset of part templates shared across all instances. We recognize test instances by comparing its active templates and the relative geometry of its part locations against those of the presented few-shot instances. We propose an end-to-end training method to learn part templates on-top of a convolutional backbone. To combat visual distortions such as orientation, pose and size, we learn multi-scale templates, and at test-time parse and match instances across these scales. We show that our method is competitive with the state-of-the-art, and by virtue of parsing enjoys interpretability as well.
Learning Compositional Representations for Effective Low-Shot Generalization
Apr 17, 2022
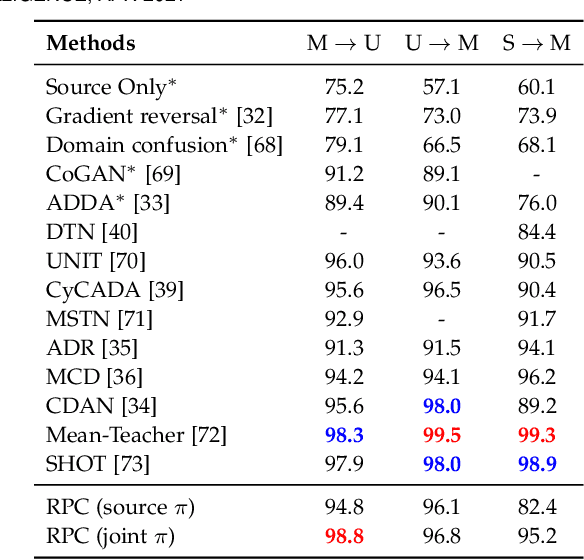
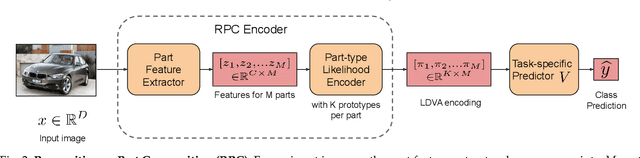
We propose Recognition as Part Composition (RPC), an image encoding approach inspired by human cognition. It is based on the cognitive theory that humans recognize complex objects by components, and that they build a small compact vocabulary of concepts to represent each instance with. RPC encodes images by first decomposing them into salient parts, and then encoding each part as a mixture of a small number of prototypes, each representing a certain concept. We find that this type of learning inspired by human cognition can overcome hurdles faced by deep convolutional networks in low-shot generalization tasks, like zero-shot learning, few-shot learning and unsupervised domain adaptation. Furthermore, we find a classifier using an RPC image encoder is fairly robust to adversarial attacks, that deep neural networks are known to be prone to. Given that our image encoding principle is based on human cognition, one would expect the encodings to be interpretable by humans, which we find to be the case via crowd-sourcing experiments. Finally, we propose an application of these interpretable encodings in the form of generating synthetic attribute annotations for evaluating zero-shot learning methods on new datasets.
Task2Sim : Towards Effective Pre-training and Transfer from Synthetic Data
Nov 30, 2021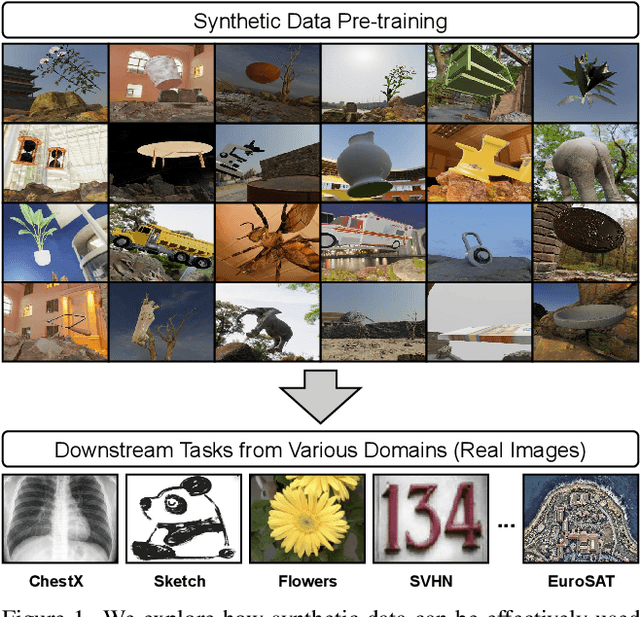
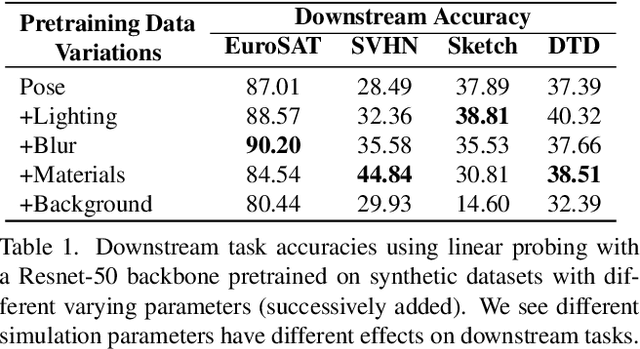
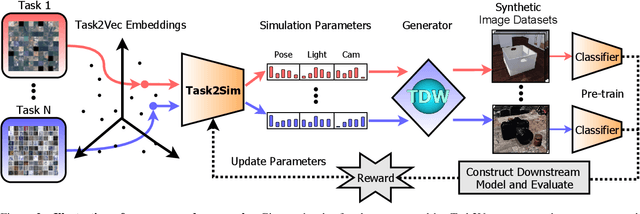
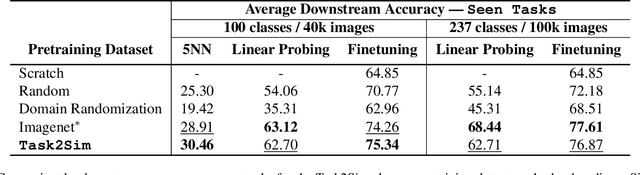
Pre-training models on Imagenet or other massive datasets of real images has led to major advances in computer vision, albeit accompanied with shortcomings related to curation cost, privacy, usage rights, and ethical issues. In this paper, for the first time, we study the transferability of pre-trained models based on synthetic data generated by graphics simulators to downstream tasks from very different domains. In using such synthetic data for pre-training, we find that downstream performance on different tasks are favored by different configurations of simulation parameters (e.g. lighting, object pose, backgrounds, etc.), and that there is no one-size-fits-all solution. It is thus better to tailor synthetic pre-training data to a specific downstream task, for best performance. We introduce Task2Sim, a unified model mapping downstream task representations to optimal simulation parameters to generate synthetic pre-training data for them. Task2Sim learns this mapping by training to find the set of best parameters on a set of "seen" tasks. Once trained, it can then be used to predict best simulation parameters for novel "unseen" tasks in one shot, without requiring additional training. Given a budget in number of images per class, our extensive experiments with 20 diverse downstream tasks show Task2Sim's task-adaptive pre-training data results in significantly better downstream performance than non-adaptively choosing simulation parameters on both seen and unseen tasks. It is even competitive with pre-training on real images from Imagenet.
VisDA-2021 Competition Universal Domain Adaptation to Improve Performance on Out-of-Distribution Data
Jul 23, 2021
Progress in machine learning is typically measured by training and testing a model on the same distribution of data, i.e., the same domain. This over-estimates future accuracy on out-of-distribution data. The Visual Domain Adaptation (VisDA) 2021 competition tests models' ability to adapt to novel test distributions and handle distributional shift. We set up unsupervised domain adaptation challenges for image classifiers and will evaluate adaptation to novel viewpoints, backgrounds, modalities and degradation in quality. Our challenge draws on large-scale publicly available datasets but constructs the evaluation across domains, rather that the traditional in-domain bench-marking. Furthermore, we focus on the difficult "universal" setting where, in addition to input distribution drift, methods may encounter missing and/or novel classes in the target dataset. Performance will be measured using a rigorous protocol, comparing to state-of-the-art domain adaptation methods with the help of established metrics. We believe that the competition will encourage further improvement in machine learning methods' ability to handle realistic data in many deployment scenarios.
Effectively Leveraging Attributes for Visual Similarity
May 04, 2021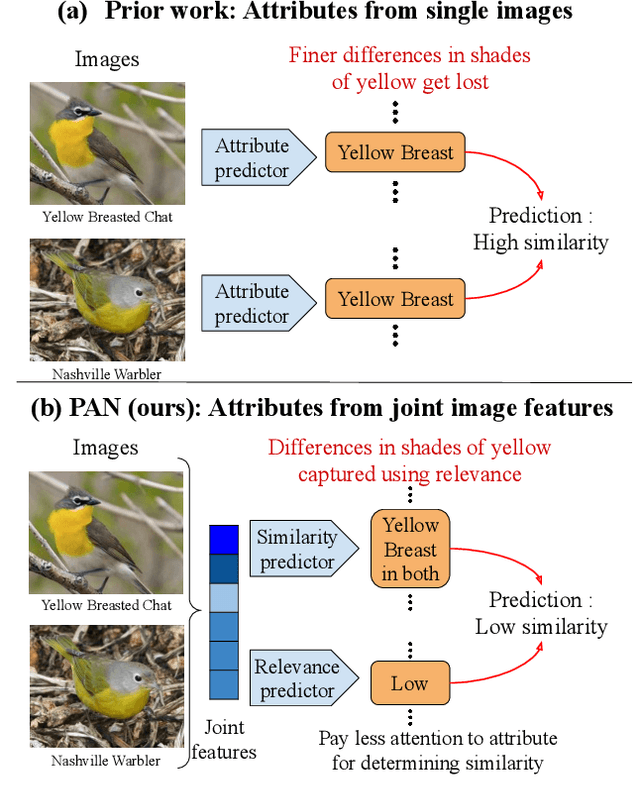
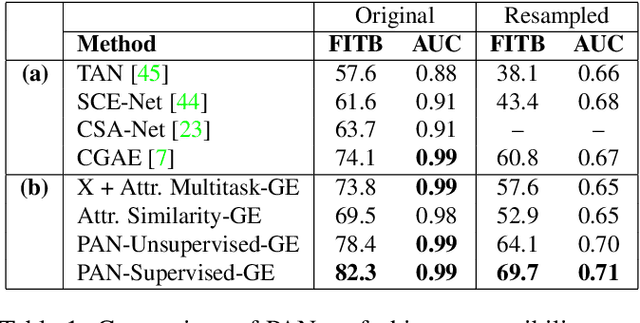


Measuring similarity between two images often requires performing complex reasoning along different axes (e.g., color, texture, or shape). Insights into what might be important for measuring similarity can can be provided by annotated attributes, but prior work tends to view these annotations as complete, resulting in them using a simplistic approach of predicting attributes on single images, which are, in turn, used to measure similarity. However, it is impractical for a dataset to fully annotate every attribute that may be important. Thus, only representing images based on these incomplete annotations may miss out on key information. To address this issue, we propose the Pairwise Attribute-informed similarity Network (PAN), which breaks similarity learning into capturing similarity conditions and relevance scores from a joint representation of two images. This enables our model to identify that two images contain the same attribute, but can have it deemed irrelevant (e.g., due to fine-grained differences between them) and ignored for measuring similarity between the two images. Notably, while prior methods of using attribute annotations are often unable to outperform prior art, PAN obtains a 4-9% improvement on compatibility prediction between clothing items on Polyvore Outfits, a 5\% gain on few shot classification of images using Caltech-UCSD Birds (CUB), and over 1% boost to Recall@1 on In-Shop Clothes Retrieval.