 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFine-grained Few-shot Recognition by Deep Object Parsing
Paper and Code
Jul 14, 2022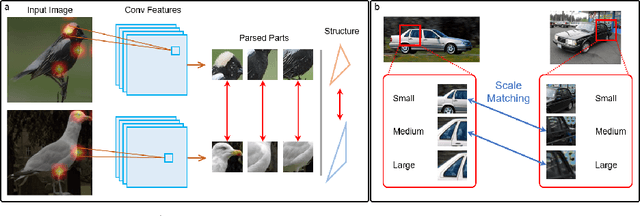
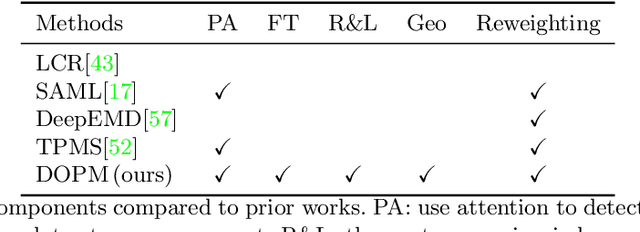
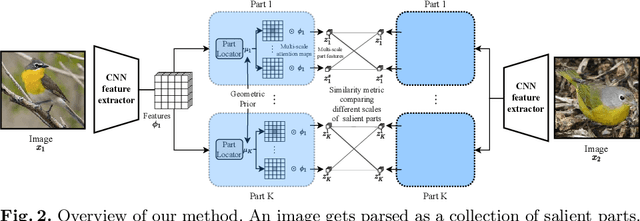
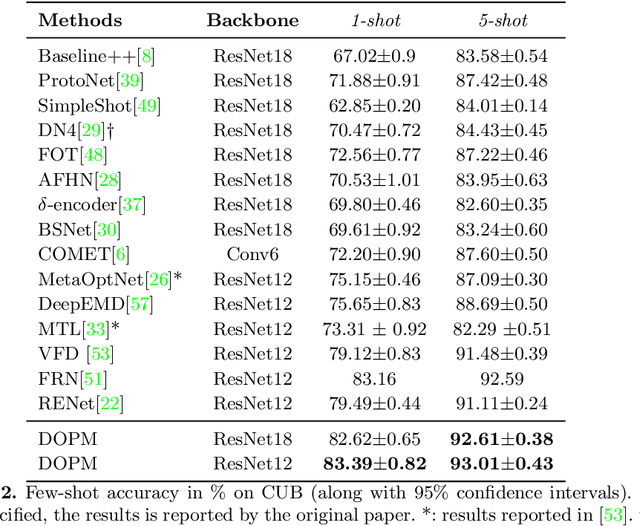
In our framework, an object is made up of K distinct parts or units, and we parse a test instance by inferring the K parts, where each part occupies a distinct location in the feature space, and the instance features at this location, manifest as an active subset of part templates shared across all instances. We recognize test instances by comparing its active templates and the relative geometry of its part locations against those of the presented few-shot instances. We propose an end-to-end training method to learn part templates on-top of a convolutional backbone. To combat visual distortions such as orientation, pose and size, we learn multi-scale templates, and at test-time parse and match instances across these scales. We show that our method is competitive with the state-of-the-art, and by virtue of parsing enjoys interpretability as well.