 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhancing Vision-Language Pre-training with Rich Supervisions
Mar 05, 2024



We propose Strongly Supervised pre-training with ScreenShots (S4) - a novel pre-training paradigm for Vision-Language Models using data from large-scale web screenshot rendering. Using web screenshots unlocks a treasure trove of visual and textual cues that are not present in using image-text pairs. In S4, we leverage the inherent tree-structured hierarchy of HTML elements and the spatial localization to carefully design 10 pre-training tasks with large scale annotated data. These tasks resemble downstream tasks across different domains and the annotations are cheap to obtain. We demonstrate that, compared to current screenshot pre-training objectives, our innovative pre-training method significantly enhances performance of image-to-text model in nine varied and popular downstream tasks - up to 76.1% improvements on Table Detection, and at least 1% on Widget Captioning.
DEED: Dynamic Early Exit on Decoder for Accelerating Encoder-Decoder Transformer Models
Nov 15, 2023Encoder-decoder transformer models have achieved great success on various vision-language (VL) tasks, but they suffer from high inference latency. Typically, the decoder takes up most of the latency because of the auto-regressive decoding. To accelerate the inference, we propose an approach of performing Dynamic Early Exit on Decoder (DEED). We build a multi-exit encoder-decoder transformer model which is trained with deep supervision so that each of its decoder layers is capable of generating plausible predictions. In addition, we leverage simple yet practical techniques, including shared generation head and adaptation modules, to keep accuracy when exiting at shallow decoder layers. Based on the multi-exit model, we perform step-level dynamic early exit during inference, where the model may decide to use fewer decoder layers based on its confidence of the current layer at each individual decoding step. Considering different number of decoder layers may be used at different decoding steps, we compute deeper-layer decoder features of previous decoding steps just-in-time, which ensures the features from different decoding steps are semantically aligned. We evaluate our approach with two state-of-the-art encoder-decoder transformer models on various VL tasks. We show our approach can reduce overall inference latency by 30%-60% with comparable or even higher accuracy compared to baselines.
Fine-grained Few-shot Recognition by Deep Object Parsing
Jul 14, 2022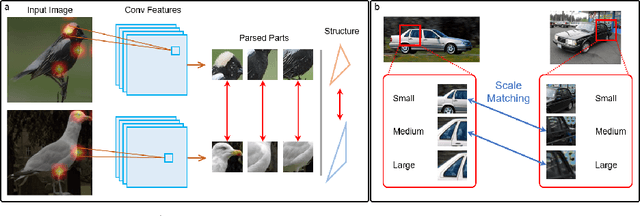
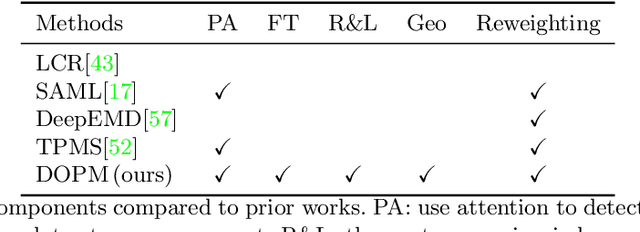
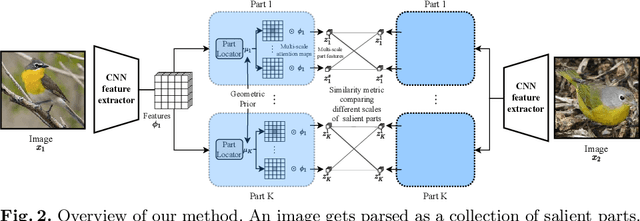
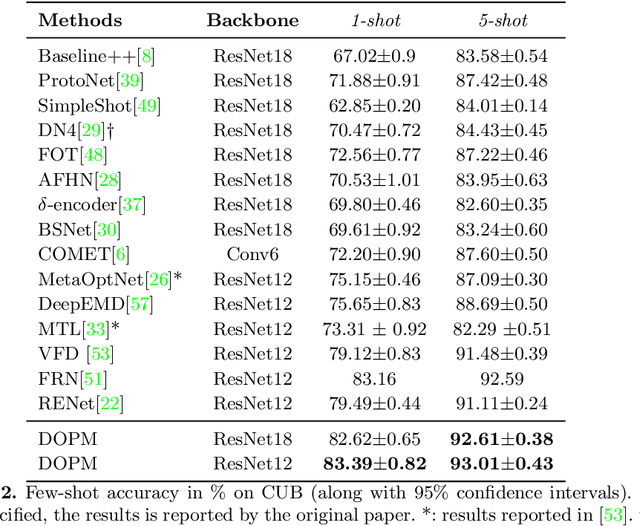
In our framework, an object is made up of K distinct parts or units, and we parse a test instance by inferring the K parts, where each part occupies a distinct location in the feature space, and the instance features at this location, manifest as an active subset of part templates shared across all instances. We recognize test instances by comparing its active templates and the relative geometry of its part locations against those of the presented few-shot instances. We propose an end-to-end training method to learn part templates on-top of a convolutional backbone. To combat visual distortions such as orientation, pose and size, we learn multi-scale templates, and at test-time parse and match instances across these scales. We show that our method is competitive with the state-of-the-art, and by virtue of parsing enjoys interpretability as well.
Learning Compositional Representations for Effective Low-Shot Generalization
Apr 17, 2022
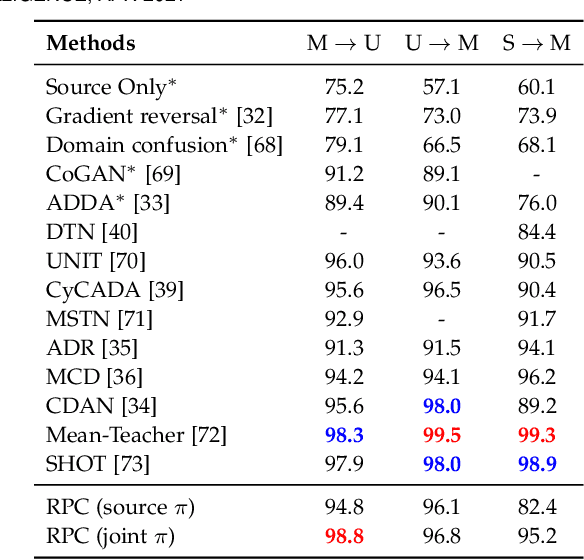
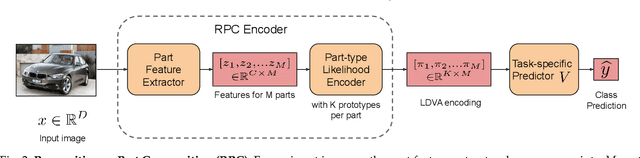
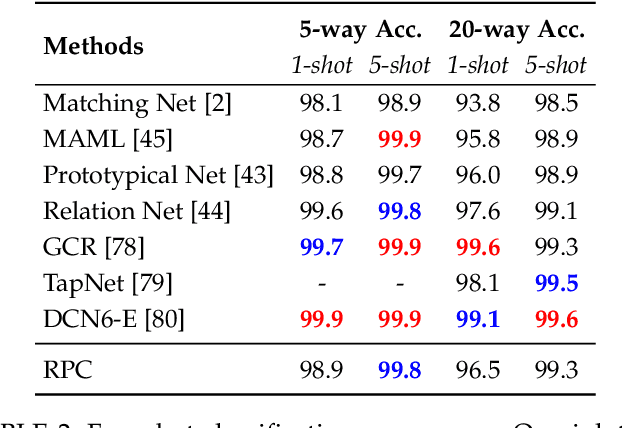
We propose Recognition as Part Composition (RPC), an image encoding approach inspired by human cognition. It is based on the cognitive theory that humans recognize complex objects by components, and that they build a small compact vocabulary of concepts to represent each instance with. RPC encodes images by first decomposing them into salient parts, and then encoding each part as a mixture of a small number of prototypes, each representing a certain concept. We find that this type of learning inspired by human cognition can overcome hurdles faced by deep convolutional networks in low-shot generalization tasks, like zero-shot learning, few-shot learning and unsupervised domain adaptation. Furthermore, we find a classifier using an RPC image encoder is fairly robust to adversarial attacks, that deep neural networks are known to be prone to. Given that our image encoding principle is based on human cognition, one would expect the encodings to be interpretable by humans, which we find to be the case via crowd-sourcing experiments. Finally, we propose an application of these interpretable encodings in the form of generating synthetic attribute annotations for evaluating zero-shot learning methods on new datasets.
Contrastive Neighborhood Alignment
Jan 06, 2022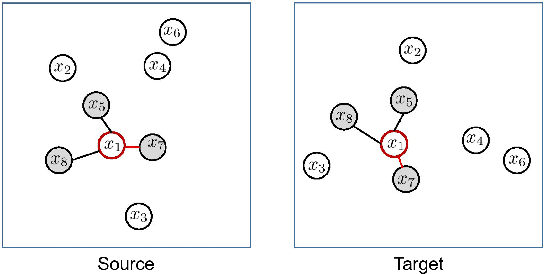
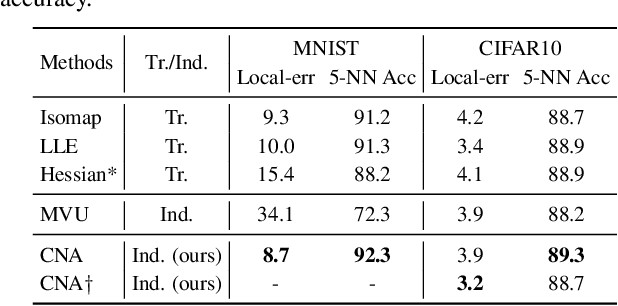
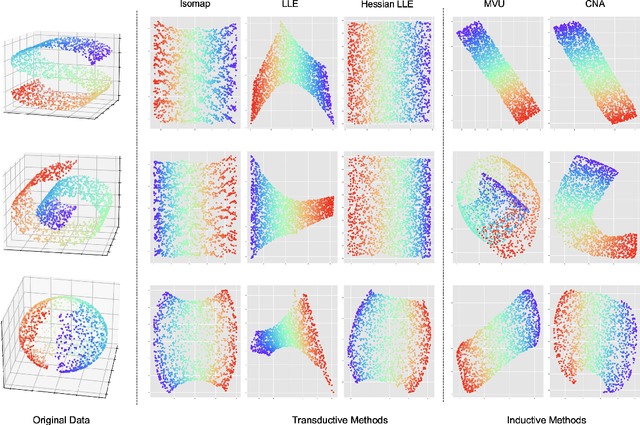
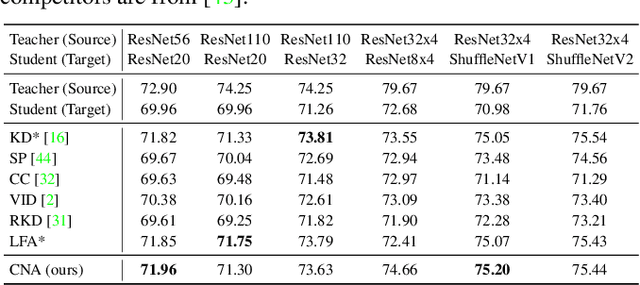
We present Contrastive Neighborhood Alignment (CNA), a manifold learning approach to maintain the topology of learned features whereby data points that are mapped to nearby representations by the source (teacher) model are also mapped to neighbors by the target (student) model. The target model aims to mimic the local structure of the source representation space using a contrastive loss. CNA is an unsupervised learning algorithm that does not require ground-truth labels for the individual samples. CNA is illustrated in three scenarios: manifold learning, where the model maintains the local topology of the original data in a dimension-reduced space; model distillation, where a small student model is trained to mimic a larger teacher; and legacy model update, where an older model is replaced by a more powerful one. Experiments show that CNA is able to capture the manifold in a high-dimensional space and improves performance compared to the competing methods in their domains.
Dont Even Look Once: Synthesizing Features for Zero-Shot Detection
Nov 18, 2019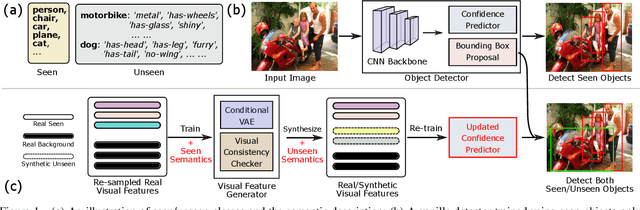
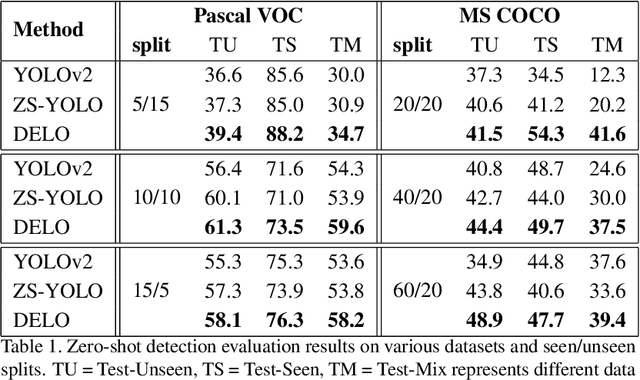

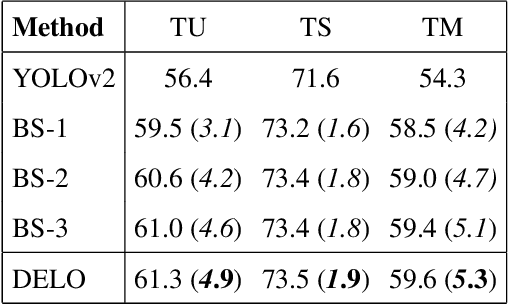
Zero-shot detection, namely, localizing both seen and unseen objects, increasingly gains importance for large-scale applications, with large number of object classes, since, collecting sufficient annotated data with ground truth bounding boxes is simply not scalable. While vanilla deep neural networks deliver high performance for objects available during training, unseen object detection degrades significantly. At a fundamental level, while vanilla detectors are capable of proposing bounding boxes, which include unseen objects, they are often incapable of assigning high-confidence to unseen objects, due to the inherent precision/recall tradeoffs that requires rejecting background objects. We propose a novel detection algorithm Dont Even Look Once (DELO), that synthesizes visual features for unseen objects and augments existing training algorithms to incorporate unseen object detection. Our proposed scheme is evaluated on Pascal VOC and MSCOCO, and we demonstrate significant improvements in test accuracy over vanilla and other state-of-art zero-shot detectors
Learning for New Visual Environments with Limited Labels
Jan 25, 2019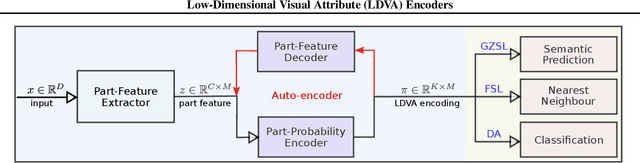

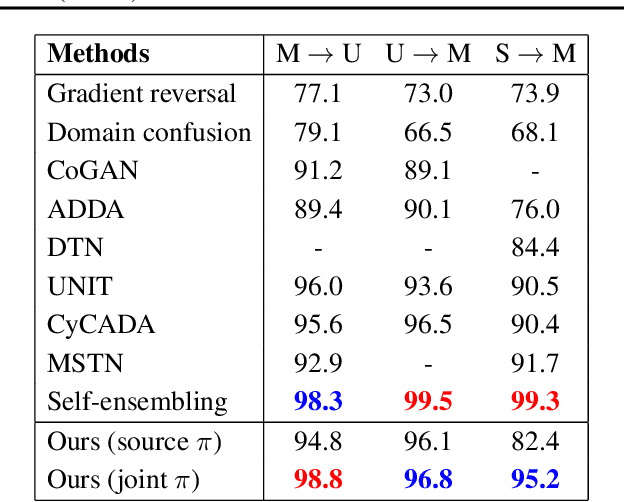
In computer vision applications, such as domain adaptation (DA), few shot learning (FSL) and zero-shot learning (ZSL), we encounter new objects and environments, for which insufficient examples exist to allow for training "models from scratch," and methods that adapt existing models, trained on the presented training environment, to the new scenario are required. We propose a novel visual attribute encoding method that encodes each image as a low-dimensional probability vector composed of prototypical part-type probabilities. The prototypes are learnt to be representative of all training data. At test-time we utilize this encoding as an input to a classifier. At test-time we freeze the encoder and only learn/adapt the classifier component to limited annotated labels in FSL; new semantic attributes in ZSL. We conduct extensive experiments on benchmark datasets. Our method outperforms state-of-art methods trained for the specific contexts (ZSL, FSL, DA).
Generalized Zero-Shot Recognition based on Visually Semantic Embedding
Nov 19, 2018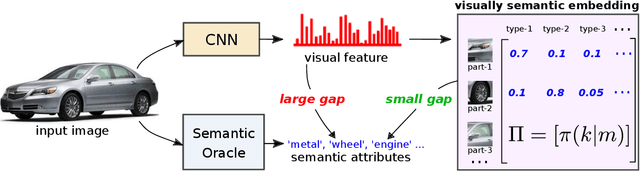
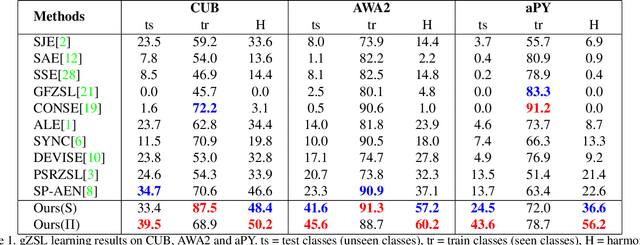
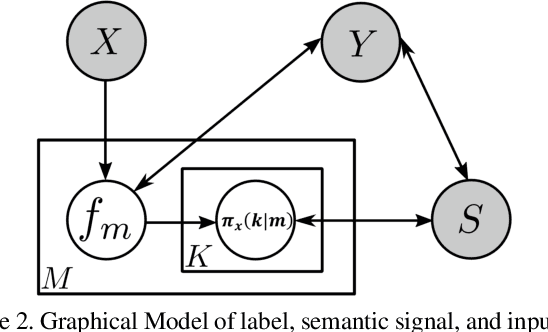

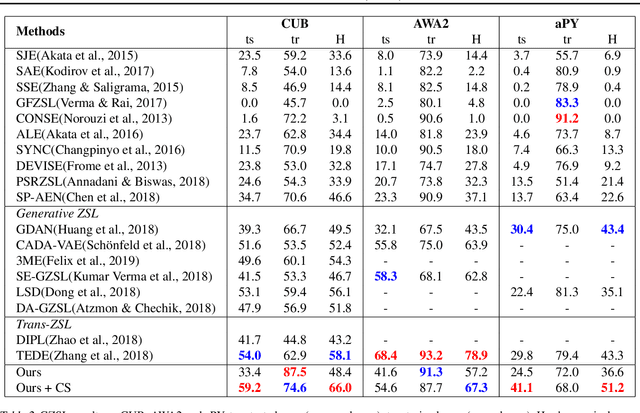
We propose a novel Generalized Zero-Shot learning (GZSL) method that is agnostic to both unseen images and unseen semantic vectors during training. Prior works in this context propose to map high-dimensional visual features to the semantic domain, we believe contributes to the semantic gap. To bridge the gap, we propose a novel low-dimensional embedding of visual instances that is "visually semantic." Analogous to semantic data that quantifies the existence of an attribute in the presented instance, components of our visual embedding quantifies existence of a prototypical part-type in the presented instance. In parallel, as a thought experiment, we quantify the impact of noisy semantic data by utilizing a novel visual oracle to visually supervise a learner. These factors, namely semantic noise, visual-semantic gap and label noise lead us to propose a new graphical model for inference with pairwise interactions between label, semantic data, and inputs. We tabulate results on a number of benchmark datasets demonstrating significant improvement in accuracy over state-of-the-art under both semantic and visual supervision.
Zero-Shot Detection
Mar 19, 2018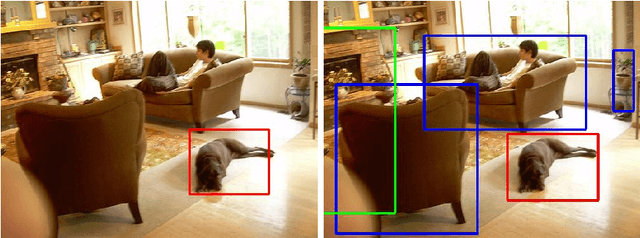


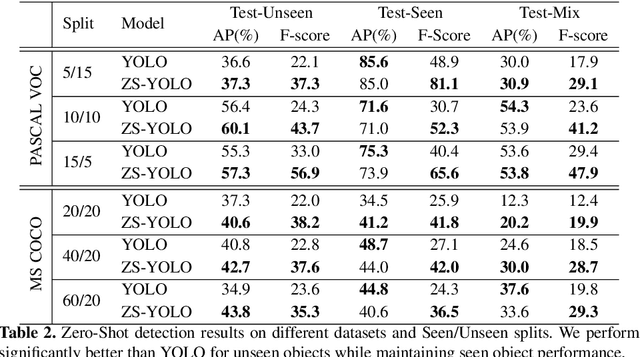
As we move towards large-scale object detection, it is unrealistic to expect annotated training data for all object classes at sufficient scale, and so methods capable of unseen object detection are required. We propose a novel zero-shot method based on training an end-to-end model that fuses semantic attribute prediction with visual features to propose object bounding boxes for seen and unseen classes. While we utilize semantic features during training, our method is agnostic to semantic information for unseen classes at test-time. Our method retains the efficiency and effectiveness of YOLO for objects seen during training, while improving its performance for novel and unseen objects. The ability of state-of-art detection methods to learn discriminative object features to reject background proposals also limits their performance for unseen objects. We posit that, to detect unseen objects, we must incorporate semantic information into the visual domain so that the learned visual features reflect this information and leads to improved recall rates for unseen objects. We test our method on PASCAL VOC and MS COCO dataset and observed significant improvements on the average precision of unseen classes.