 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNon-autoregressive Sequence-to-Sequence Vision-Language Models
Mar 04, 2024



Sequence-to-sequence vision-language models are showing promise, but their applicability is limited by their inference latency due to their autoregressive way of generating predictions. We propose a parallel decoding sequence-to-sequence vision-language model, trained with a Query-CTC loss, that marginalizes over multiple inference paths in the decoder. This allows us to model the joint distribution of tokens, rather than restricting to conditional distribution as in an autoregressive model. The resulting model, NARVL, achieves performance on-par with its state-of-the-art autoregressive counterpart, but is faster at inference time, reducing from the linear complexity associated with the sequential generation of tokens to a paradigm of constant time joint inference.
MATrIX -- Modality-Aware Transformer for Information eXtraction
May 17, 2022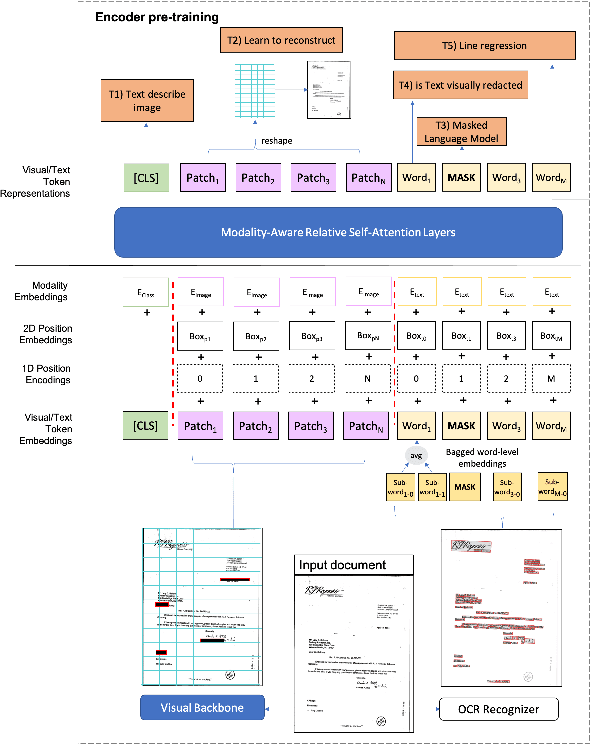
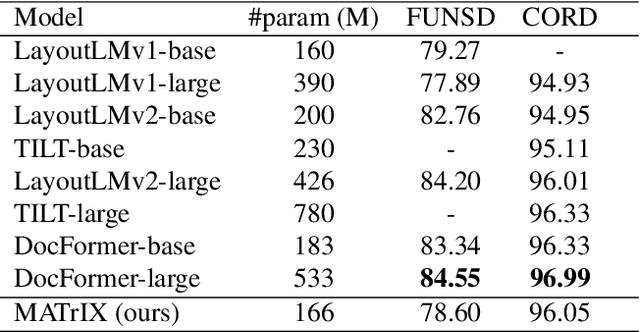

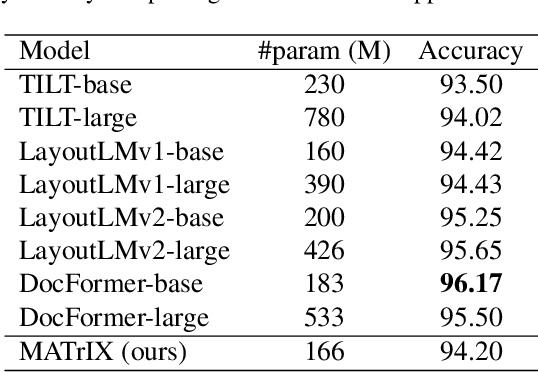
We present MATrIX - a Modality-Aware Transformer for Information eXtraction in the Visual Document Understanding (VDU) domain. VDU covers information extraction from visually rich documents such as forms, invoices, receipts, tables, graphs, presentations, or advertisements. In these, text semantics and visual information supplement each other to provide a global understanding of the document. MATrIX is pre-trained in an unsupervised way with specifically designed tasks that require the use of multi-modal information (spatial, visual, or textual). We consider the spatial and text modalities all at once in a single token set. To make the attention more flexible, we use a learned modality-aware relative bias in the attention mechanism to modulate the attention between the tokens of different modalities. We evaluate MATrIX on 3 different datasets each with strong baselines.
Contrastive Neighborhood Alignment
Jan 06, 2022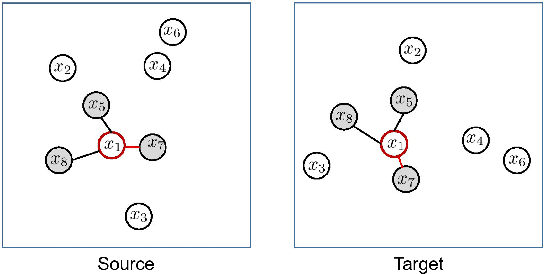
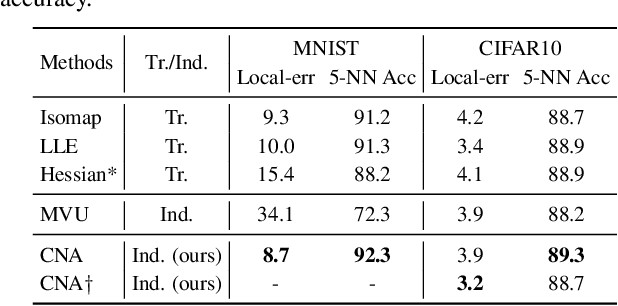
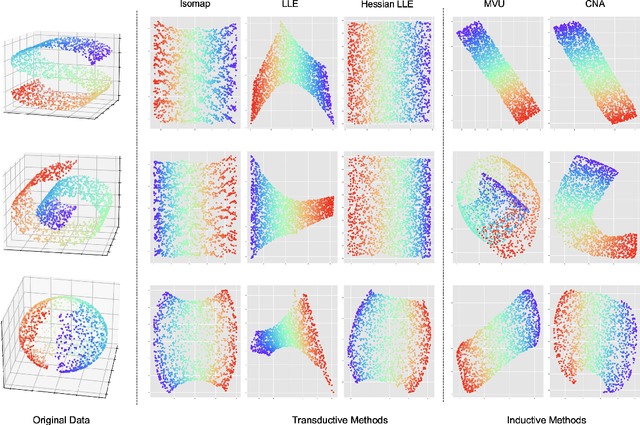
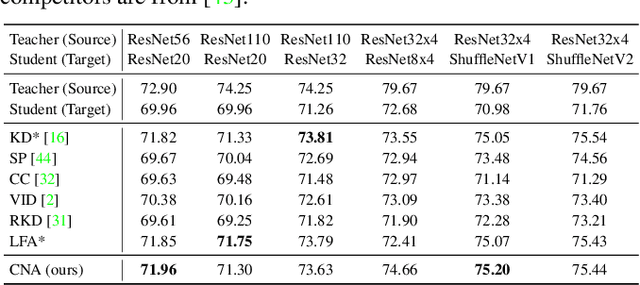
We present Contrastive Neighborhood Alignment (CNA), a manifold learning approach to maintain the topology of learned features whereby data points that are mapped to nearby representations by the source (teacher) model are also mapped to neighbors by the target (student) model. The target model aims to mimic the local structure of the source representation space using a contrastive loss. CNA is an unsupervised learning algorithm that does not require ground-truth labels for the individual samples. CNA is illustrated in three scenarios: manifold learning, where the model maintains the local topology of the original data in a dimension-reduced space; model distillation, where a small student model is trained to mimic a larger teacher; and legacy model update, where an older model is replaced by a more powerful one. Experiments show that CNA is able to capture the manifold in a high-dimensional space and improves performance compared to the competing methods in their domains.