 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExecTune: Effective Steering of Black-Box LLMs with Guide Models
Apr 09, 2026For large language models deployed through black-box APIs, recurring inference costs often exceed one-time training costs. This motivates composed agentic systems that amortize expensive reasoning into reusable intermediate representations. We study a broad class of such systems, termed Guide-Core Policies (GCoP), in which a guide model generates a structured strategy that is executed by a black-box core model. This abstraction subsumes base, supervised, and advisor-style approaches, which differ primarily in how the guide is trained. We formalize GCoP under a cost-sensitive utility objective and show that end-to-end performance is governed by guide-averaged executability: the probability that a strategy generated by the guide can be faithfully executed by the core. Our analysis shows that existing GCoP instantiations often fail to optimize executability under deployment constraints, resulting in brittle strategies and inefficient computation. Motivated by these insights, we propose ExecTune, a principled training recipe that combines teacher-guided acceptance sampling, supervised fine-tuning, and structure-aware reinforcement learning to directly optimize syntactic validity, execution success, and cost efficiency. Across mathematical reasoning and code-generation benchmarks, GCoP with ExecTune improves accuracy by up to 9.2% over prior state-of-the-art baselines while reducing inference cost by up to 22.4%. It enables Claude Haiku 3.5 to outperform Sonnet 3.5 on both math and code tasks, and to come within 1.7% absolute accuracy of Sonnet 4 at 38% lower cost. Beyond efficiency, GCoP also supports modular adaptation by updating the guide without retraining the core.
Asymmetric Actor-Critic for Multi-turn LLM Agents
Mar 31, 2026Large language models (LLMs) exhibit strong reasoning and conversational abilities, but ensuring reliable behavior in multi-turn interactions remains challenging. In many real-world applications, agents must succeed in one-shot settings where retries are impossible. Existing approaches either rely on reflection or post-hoc evaluation, which require additional attempts, or assume fully trainable models that cannot leverage proprietary LLMs. We propose an asymmetric actor-critic framework for reliable conversational agents. A powerful proprietary LLM acts as the actor, while a smaller open-source critic provides runtime supervision, monitoring the actor's actions and intervening within the same interaction trajectory. Unlike training-based actor-critic methods, our framework supervises a fixed actor operating in open-ended conversational environments. The design leverages a generation-verification asymmetry: while high-quality generation requires large models, effective oversight can often be achieved by smaller ones. We further introduce a data generation pipeline that produces supervision signals for critic fine-tuning without modifying the actor. Experiments on $τ$-bench and UserBench show that our approach significantly improves reliability and task success over strong single-agent baselines. Moreover, lightweight open-source critics rival or surpass larger proprietary models in the critic role, and critic fine-tuning yields additional gains over several state-of-the-art methods.
Learning When to Attend: Conditional Memory Access for Long-Context LLMs
Mar 18, 2026Language models struggle to generalize beyond pretraining context lengths, limiting long-horizon reasoning and retrieval. Continued pretraining on long-context data can help but is expensive due to the quadratic scaling of Attention. We observe that most tokens do not require (Global) Attention over the entire sequence and can rely on local context. Based on this, we propose L2A (Learning To Attend), a layer that enables conditional (token-wise) long-range memory access by deciding when to invoke global attention. We evaluate L2A on Qwen 2.5 and Qwen 3 models, extending their effective context length from 32K to 128K tokens. L2A matches the performance of standard long-context training to within 3% while skipping Global Attention for $\sim$80% of tokens, outperforming prior baselines. We also design custom Triton kernels to efficiently implement this token-wise conditional Attention on GPUs, achieving up to $\sim$2x improvements in training throughput and time-to-first-token over FlashAttention. Moreover, L2A enables post-training pruning of highly sparse Global Attention layers, reducing KV cache memory by up to 50% with negligible performance loss.
Reinforcement-aware Knowledge Distillation for LLM Reasoning
Feb 26, 2026Reinforcement learning (RL) post-training has recently driven major gains in long chain-of-thought reasoning large language models (LLMs), but the high inference cost of such models motivates distillation into smaller students. Most existing knowledge distillation (KD) methods are designed for supervised fine-tuning (SFT), relying on fixed teacher traces or teacher-student Kullback-Leibler (KL) divergence-based regularization. When combined with RL, these approaches often suffer from distribution mismatch and objective interference: teacher supervision may not align with the student's evolving rollout distribution, and the KL regularizer can compete with reward maximization and require careful loss balancing. To address these issues, we propose RL-aware distillation (RLAD), which performs selective imitation during RL -- guiding the student toward the teacher only when it improves the current policy update. Our core component, Trust Region Ratio Distillation (TRRD), replaces the teacher-student KL regularizer with a PPO/GRPO-style likelihood-ratio objective anchored to a teacher--old-policy mixture, yielding advantage-aware, trust-region-bounded distillation on student rollouts and naturally balancing exploration, exploitation, and imitation. Across diverse logic reasoning and math benchmarks, RLAD consistently outperforms offline distillation, standard GRPO, and KL-based on-policy teacher-student knowledge distillation.
Evolutionary Generation of Multi-Agent Systems
Feb 06, 2026Large language model (LLM)-based multi-agent systems (MAS) show strong promise for complex reasoning, planning, and tool-augmented tasks, but designing effective MAS architectures remains labor-intensive, brittle, and hard to generalize. Existing automatic MAS generation methods either rely on code generation, which often leads to executability and robustness failures, or impose rigid architectural templates that limit expressiveness and adaptability. We propose Evolutionary Generation of Multi-Agent Systems (EvoMAS), which formulates MAS generation as structured configuration generation. EvoMAS performs evolutionary generation in configuration space. Specifically, EvoMAS selects initial configurations from a pool, applies feedback-conditioned mutation and crossover guided by execution traces, and iteratively refines both the candidate pool and an experience memory. We evaluate EvoMAS on diverse benchmarks, including BBEH, SWE-Bench, and WorkBench, covering reasoning, software engineering, and tool-use tasks. EvoMAS consistently improves task performance over both human-designed MAS and prior automatic MAS generation methods, while producing generated systems with higher executability and runtime robustness. EvoMAS outperforms the agent evolution method EvoAgent by +10.5 points on BBEH reasoning and +7.1 points on WorkBench. With Claude-4.5-Sonnet, EvoMAS also reaches 79.1% on SWE-Bench-Verified, matching the top of the leaderboard.
Talk2Move: Reinforcement Learning for Text-Instructed Object-Level Geometric Transformation in Scenes
Jan 08, 2026We introduce Talk2Move, a reinforcement learning (RL) based diffusion framework for text-instructed spatial transformation of objects within scenes. Spatially manipulating objects in a scene through natural language poses a challenge for multimodal generation systems. While existing text-based manipulation methods can adjust appearance or style, they struggle to perform object-level geometric transformations-such as translating, rotating, or resizing objects-due to scarce paired supervision and pixel-level optimization limits. Talk2Move employs Group Relative Policy Optimization (GRPO) to explore geometric actions through diverse rollouts generated from input images and lightweight textual variations, removing the need for costly paired data. A spatial reward guided model aligns geometric transformations with linguistic description, while off-policy step evaluation and active step sampling improve learning efficiency by focusing on informative transformation stages. Furthermore, we design object-centric spatial rewards that evaluate displacement, rotation, and scaling behaviors directly, enabling interpretable and coherent transformations. Experiments on curated benchmarks demonstrate that Talk2Move achieves precise, consistent, and semantically faithful object transformations, outperforming existing text-guided editing approaches in both spatial accuracy and scene coherence.
Experience-Guided Adaptation of Inference-Time Reasoning Strategies
Nov 14, 2025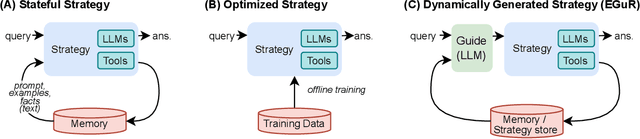
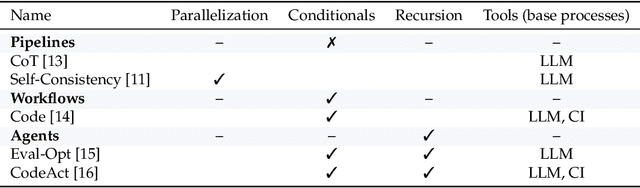

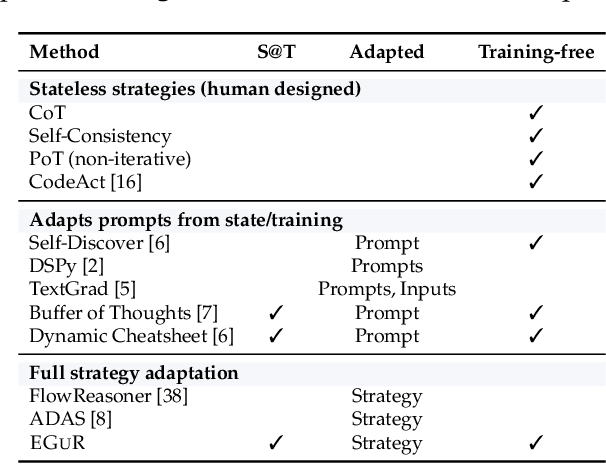
Enabling agentic AI systems to adapt their problem-solving approaches based on post-training interactions remains a fundamental challenge. While systems that update and maintain a memory at inference time have been proposed, existing designs only steer the system by modifying textual input to a language model or agent, which means that they cannot change sampling parameters, remove tools, modify system prompts, or switch between agentic and workflow paradigms. On the other hand, systems that adapt more flexibly require offline optimization and remain static once deployed. We present Experience-Guided Reasoner (EGuR), which generates tailored strategies -- complete computational procedures involving LLM calls, tools, sampling parameters, and control logic -- dynamically at inference time based on accumulated experience. We achieve this using an LLM-based meta-strategy -- a strategy that outputs strategies -- enabling adaptation of all strategy components (prompts, sampling parameters, tool configurations, and control logic). EGuR operates through two components: a Guide generates multiple candidate strategies conditioned on the current problem and structured memory of past experiences, while a Consolidator integrates execution feedback to improve future strategy generation. This produces complete, ready-to-run strategies optimized for each problem, which can be cached, retrieved, and executed as needed without wasting resources. Across five challenging benchmarks (AIME 2025, 3-SAT, and three Big Bench Extra Hard tasks), EGuR achieves up to 14% accuracy improvements over the strongest baselines while reducing computational costs by up to 111x, with both metrics improving as the system gains experience.
MURPHY: Multi-Turn GRPO for Self Correcting Code Generation
Nov 11, 2025Reinforcement Learning with Verifiable Rewards (RLVR) has emerged as a powerful framework for enhancing the reasoning capabilities of large language models (LLMs). However, existing approaches such as Group Relative Policy Optimization (GRPO) and its variants, while effective on reasoning benchmarks, struggle with agentic tasks that require iterative decision-making. We introduce Murphy, a multi-turn reflective optimization framework that extends GRPO by incorporating iterative self-correction during training. By leveraging both quantitative and qualitative execution feedback, Murphy enables models to progressively refine their reasoning across multiple turns. Evaluations on code generation benchmarks with model families such as Qwen and OLMo show that Murphy consistently improves performance, achieving up to a 8% relative gain in pass@1 over GRPO, on similar compute budgets.
Learning to Focus: Focal Attention for Selective and Scalable Transformers
Nov 10, 2025Attention is a core component of transformer architecture, whether encoder-only, decoder-only, or encoder-decoder model. However, the standard softmax attention often produces noisy probability distribution, which can impair effective feature selection at every layer of these models, particularly for long contexts. We propose Focal Attention, a simple yet effective modification that sharpens the attention distribution by controlling the softmax temperature, either as a fixed hyperparameter or as a learnable parameter during training. This sharpening enables the model to concentrate on the most relevant tokens while suppressing irrelevant ones. Empirically, Focal Attention scales more favorably than standard transformer with respect to model size, training data, and context length. Across diverse benchmarks, it achieves the same accuracy with up to 42% fewer parameters or 33% less training data. On long-context tasks, it delivers substantial relative improvements ranging from 17% to 82%, demonstrating its effectiveness in real world applications.
e1: Learning Adaptive Control of Reasoning Effort
Oct 30, 2025Increasing the thinking budget of AI models can significantly improve accuracy, but not all questions warrant the same amount of reasoning. Users may prefer to allocate different amounts of reasoning effort depending on how they value output quality versus latency and cost. To leverage this tradeoff effectively, users need fine-grained control over the amount of thinking used for a particular query, but few approaches enable such control. Existing methods require users to specify the absolute number of desired tokens, but this requires knowing the difficulty of the problem beforehand to appropriately set the token budget for a query. To address these issues, we propose Adaptive Effort Control, a self-adaptive reinforcement learning method that trains models to use a user-specified fraction of tokens relative to the current average chain-of-thought length for each query. This approach eliminates dataset- and phase-specific tuning while producing better cost-accuracy tradeoff curves compared to standard methods. Users can dynamically adjust the cost-accuracy trade-off through a continuous effort parameter specified at inference time. We observe that the model automatically learns to allocate resources proportionally to the task difficulty and, across model scales ranging from 1.5B to 32B parameters, our approach enables approximately 3x reduction in chain-of-thought length while maintaining or improving performance relative to the base model used for RL training.