 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRobust Planning for Autonomous Driving via Mixed Adversarial Diffusion Predictions
May 18, 2025
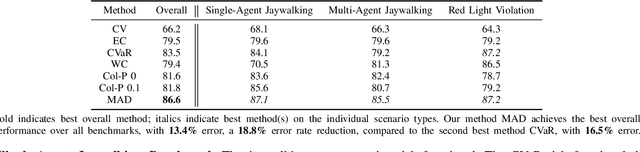


We describe a robust planning method for autonomous driving that mixes normal and adversarial agent predictions output by a diffusion model trained for motion prediction. We first train a diffusion model to learn an unbiased distribution of normal agent behaviors. We then generate a distribution of adversarial predictions by biasing the diffusion model at test time to generate predictions that are likely to collide with a candidate plan. We score plans using expected cost with respect to a mixture distribution of normal and adversarial predictions, leading to a planner that is robust against adversarial behaviors but not overly conservative when agents behave normally. Unlike current approaches, we do not use risk measures that over-weight adversarial behaviors while placing little to no weight on low-cost normal behaviors or use hard safety constraints that may not be appropriate for all driving scenarios. We show the effectiveness of our method on single-agent and multi-agent jaywalking scenarios as well as a red light violation scenario.
LaTeS: Latent Space Distillation for Teacher-Student Driving Policy Learning
Dec 06, 2019

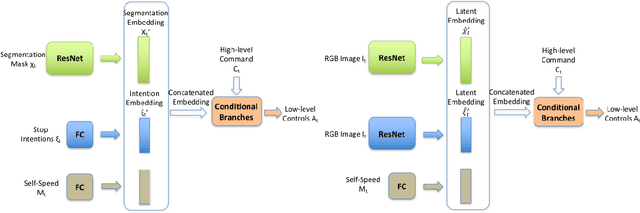

We describe a policy learning approach to map visual inputs to driving controls that leverages side information on semantics and affordances of objects in the scene from a secondary teacher model. While the teacher receives semantic segmentation and stop "intention" values as inputs and produces an estimate of the driving controls, the primary student model only receives images as inputs, and attempts to imitate the controls while being biased towards the latent representation of the teacher model. The latent representation encodes task-relevant information in the inputs of the teacher model, which are semantic segmentation of the image, and intention values for driving controls in the presence of objects in the scene such as vehicles, pedestrians and traffic lights. Our student model does not attempt to infer semantic segmentation or intention values from its inputs, nor to mimic the output behavior of the teacher. It instead attempts to capture the representation of the teacher inputs that are relevant for driving. Our training does not require laborious annotations such as maps or objects in three dimensions; even the teacher model just requires two-dimensional segmentation and intention values. Moreover, our model runs in real time of 59 FPS. We test our approach on recent simulated and real-world driving datasets, and introduce a more challenging but realistic evaluation protocol that considers a run that reaches the destination successful only if it does not violate common traffic rules.
Learning to Search via Retrospective Imitation
Oct 05, 2018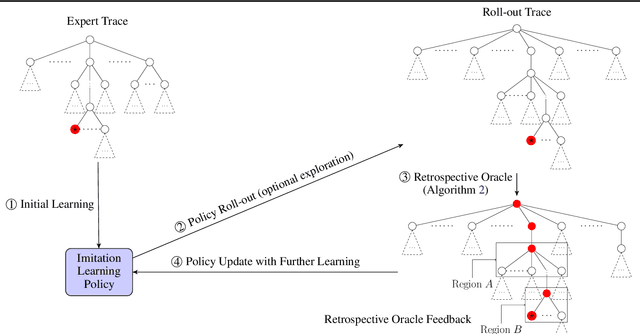
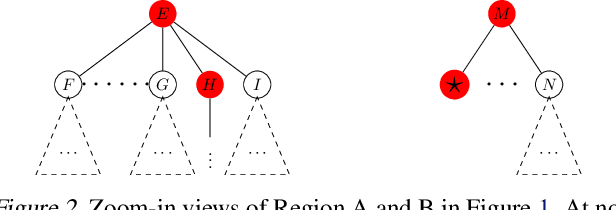
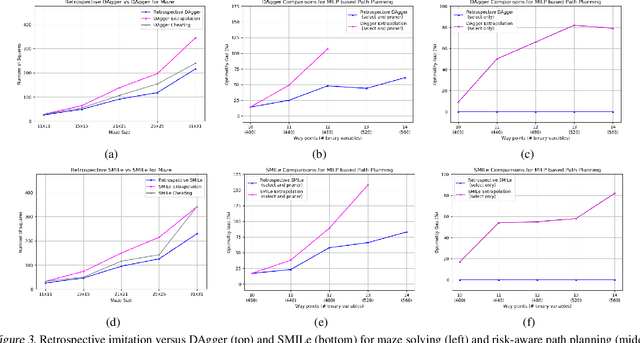

We study the problem of learning a good search policy from demonstrations for combinatorial search spaces. We propose retrospective imitation learning, which, after initial training by an expert, improves itself by learning from its own retrospective solutions. That is, when the policy eventually reaches a feasible solution in a search tree after making mistakes and backtracks, it retrospectively constructs an improved search trace to the solution by removing backtracks, which is then used to further train the policy. A key feature of our approach is that it can iteratively scale up, or transfer, to larger problem sizes than the initial expert demonstrations, thus dramatically expanding its applicability beyond that of conventional imitation learning. We showcase the effectiveness of our approach on two tasks: synthetic maze solving, and integer program based risk-aware path planning.