 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning to Search via Retrospective Imitation
Paper and Code
Oct 05, 2018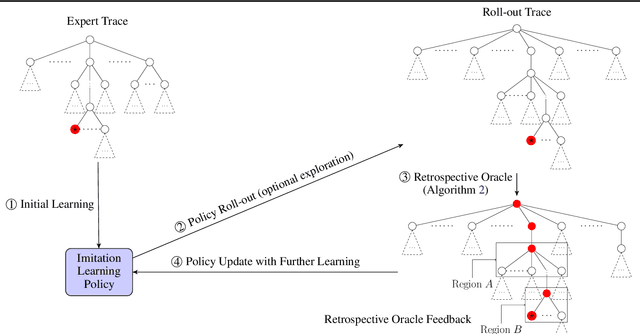
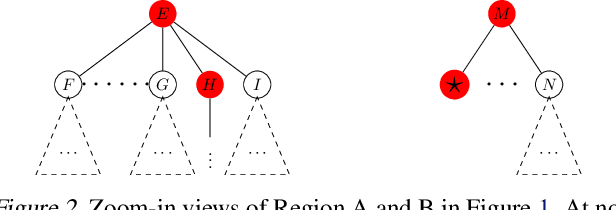
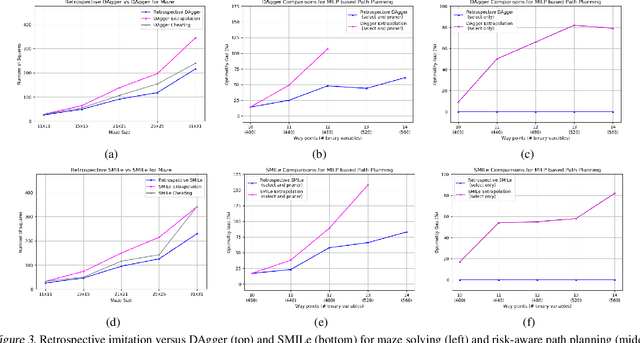

We study the problem of learning a good search policy from demonstrations for combinatorial search spaces. We propose retrospective imitation learning, which, after initial training by an expert, improves itself by learning from its own retrospective solutions. That is, when the policy eventually reaches a feasible solution in a search tree after making mistakes and backtracks, it retrospectively constructs an improved search trace to the solution by removing backtracks, which is then used to further train the policy. A key feature of our approach is that it can iteratively scale up, or transfer, to larger problem sizes than the initial expert demonstrations, thus dramatically expanding its applicability beyond that of conventional imitation learning. We showcase the effectiveness of our approach on two tasks: synthetic maze solving, and integer program based risk-aware path planning.