 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePlanetary Exploration 3.0: A Roadmap for Software-Defined, Radically Adaptive Space Systems
Apr 22, 2026The surface and subsurface of worlds beyond Mars remain largely unexplored. Yet these worlds hold keys to fundamental questions in planetary science - from potentially habitable subsurface oceans on icy moons to ancient records preserved in Kuiper Belt objects. NASA's success in Mars exploration was achieved through incrementalism: 22 progressively sophisticated missions over decades. This paradigm, which we call Planetary Exploration 2.0 (PE 2.0), is untenable for the outer Solar System, where cruise times of a decade or more make iterative missions infeasible. We propose Planetary Exploration 3.0 (PE 3.0): a paradigm in which unvisited worlds are explored by a single or a few missions with radically adaptive space systems. A PE 3.0 mission conducts both initial exploratory science and follow-on hypothesis-driven science based on its own in situ data returns, evolving spacecraft capabilities to work resiliently in previously unseen environments. The key enabler of PE 3.0 is software-defined space systems (SDSSs) - systems that can adapt their functions at all levels through software updates. This paper presents findings from a Keck Institute for Space Studies (KISS) workshop on PE 3.0, covering: (1) PE 3.0 systems engineering including science definition, architecture, design methods, and verification & validation; (2) software-defined space system technologies including reconfigurable hardware, multi-functionality, and modularity; (3) onboard intelligence including autonomous science, navigation, controls, and embodied AI; and (4) three PE 3.0 mission concepts: a Neptune/Triton smart flyby, an ocean world explorer, and an Oort cloud reconnaissance mission.
Risk-aware Integrated Task and Motion Planning for Versatile Snake Robots under Localization Failures
Feb 27, 2025



Snake robots enable mobility through extreme terrains and confined environments in terrestrial and space applications. However, robust perception and localization for snake robots remain an open challenge due to the proximity of the sensor payload to the ground coupled with a limited field of view. To address this issue, we propose Blind-motion with Intermittently Scheduled Scans (BLISS) which combines proprioception-only mobility with intermittent scans to be resilient against both localization failures and collision risks. BLISS is formulated as an integrated Task and Motion Planning (TAMP) problem that leads to a Chance-Constrained Hybrid Partially Observable Markov Decision Process (CC-HPOMDP), known to be computationally intractable due to the curse of history. Our novelty lies in reformulating CC-HPOMDP as a tractable, convex Mixed Integer Linear Program. This allows us to solve BLISS-TAMP significantly faster and jointly derive optimal task-motion plans. Simulations and hardware experiments on the EELS snake robot show our method achieves over an order of magnitude computational improvement compared to state-of-the-art POMDP planners and $>$ 50\% better navigation time optimality versus classical two-stage planners.
ShadowNav: Autonomous Global Localization for Lunar Navigation in Darkness
May 06, 2024The ability to determine the pose of a rover in an inertial frame autonomously is a crucial capability necessary for the next generation of surface rover missions on other planetary bodies. Currently, most on-going rover missions utilize ground-in-the-loop interventions to manually correct for drift in the pose estimate and this human supervision bottlenecks the distance over which rovers can operate autonomously and carry out scientific measurements. In this paper, we present ShadowNav, an autonomous approach for global localization on the Moon with an emphasis on driving in darkness and at nighttime. Our approach uses the leading edge of Lunar craters as landmarks and a particle filtering approach is used to associate detected craters with known ones on an offboard map. We discuss the key design decisions in developing the ShadowNav framework for use with a Lunar rover concept equipped with a stereo camera and an external illumination source. Finally, we demonstrate the efficacy of our proposed approach in both a Lunar simulation environment and on data collected during a field test at Cinder Lakes, Arizona.
Temporal Multimodal Multivariate Learning
Jun 14, 2022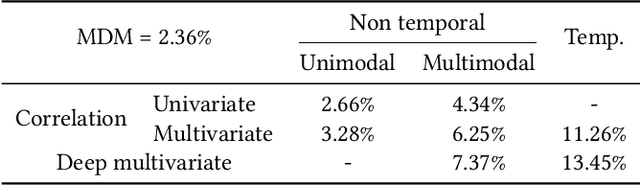
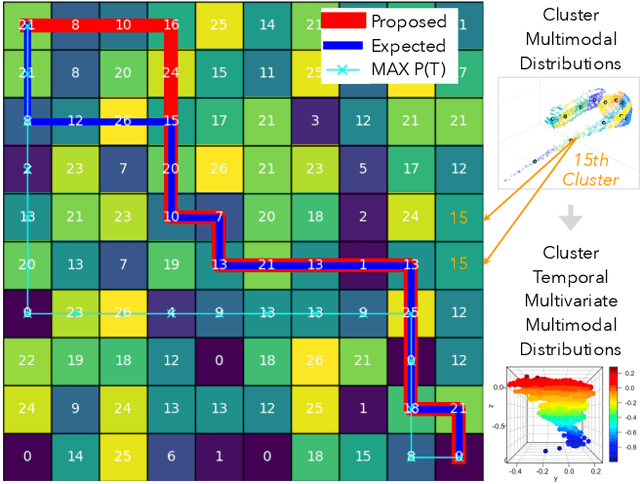
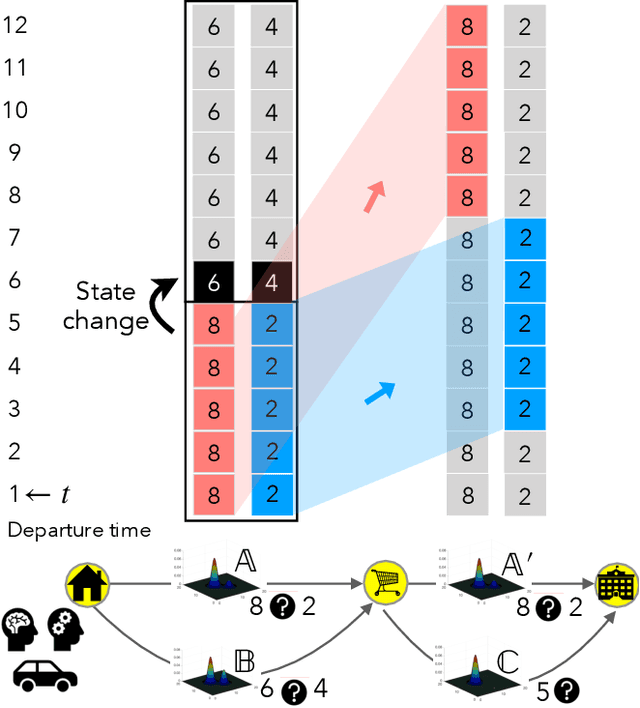
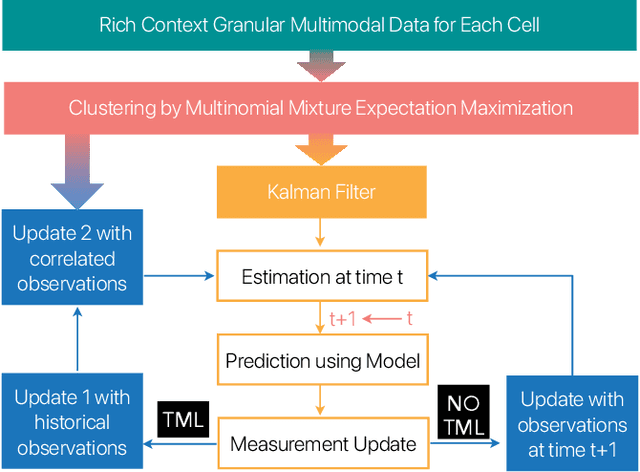
We introduce temporal multimodal multivariate learning, a new family of decision making models that can indirectly learn and transfer online information from simultaneous observations of a probability distribution with more than one peak or more than one outcome variable from one time stage to another. We approximate the posterior by sequentially removing additional uncertainties across different variables and time, based on data-physics driven correlation, to address a broader class of challenging time-dependent decision-making problems under uncertainty. Extensive experiments on real-world datasets ( i.e., urban traffic data and hurricane ensemble forecasting data) demonstrate the superior performance of the proposed targeted decision-making over the state-of-the-art baseline prediction methods across various settings.
Lunar Rover Localization Using Craters as Landmarks
Mar 18, 2022

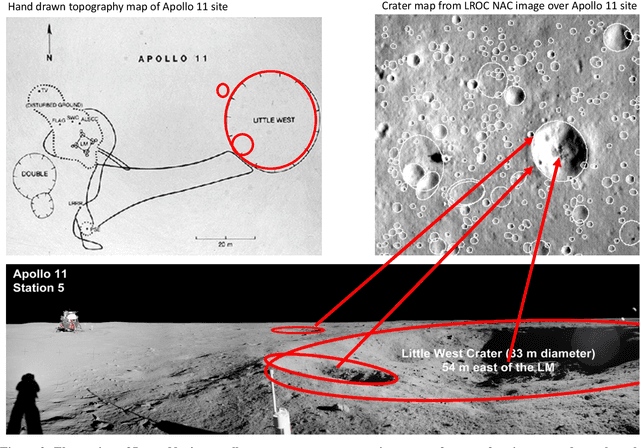
Onboard localization capabilities for planetary rovers to date have used relative navigation, by integrating combinations of wheel odometry, visual odometry, and inertial measurements during each drive to track position relative to the start of each drive. At the end of each drive, a ground-in-the-loop (GITL) interaction is used to get a position update from human operators in a more global reference frame, by matching images or local maps from onboard the rover to orbital reconnaissance images or maps of a large region around the rover's current position. Autonomous rover drives are limited in distance so that accumulated relative navigation error does not risk the possibility of the rover driving into hazards known from orbital images. However, several rover mission concepts have recently been studied that require much longer drives between GITL cycles, particularly for the Moon. These concepts require greater autonomy to minimize GITL cycles to enable such large range; onboard global localization is a key element of such autonomy. Multiple techniques have been studied in the past for onboard rover global localization, but a satisfactory solution has not yet emerged. For the Moon, the ubiquitous craters offer a new possibility, which involves mapping craters from orbit, then recognizing crater landmarks with cameras and-or a lidar onboard the rover. This approach is applicable everywhere on the Moon, does not require high resolution stereo imaging from orbit as some other approaches do, and has potential to enable position knowledge with order of 5 to 10 m accuracy at all times. This paper describes our technical approach to crater-based lunar rover localization and presents initial results on crater detection using 3D point cloud data from onboard lidar or stereo cameras, as well as using shading cues in monocular onboard imagery.
MLNav: Learning to Safely Navigate on Martian Terrains
Mar 09, 2022
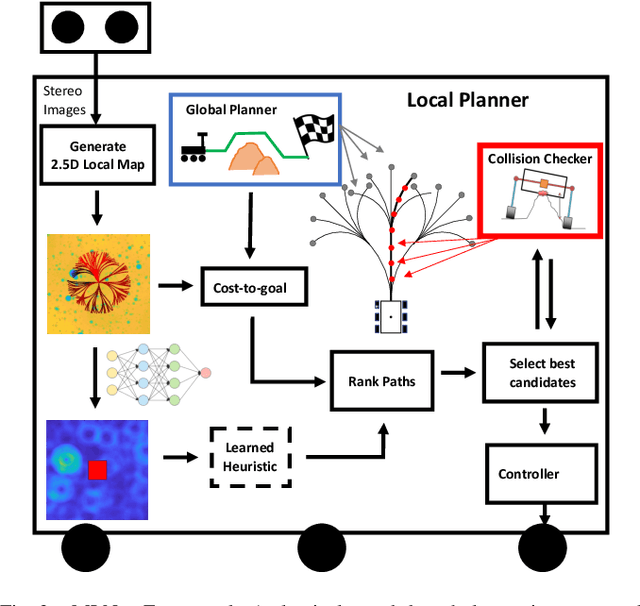

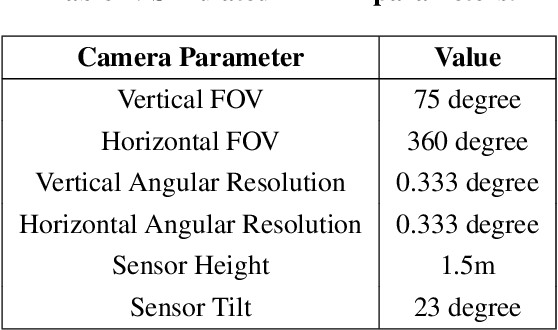
We present MLNav, a learning-enhanced path planning framework for safety-critical and resource-limited systems operating in complex environments, such as rovers navigating on Mars. MLNav makes judicious use of machine learning to enhance the efficiency of path planning while fully respecting safety constraints. In particular, the dominant computational cost in such safety-critical settings is running a model-based safety checker on the proposed paths. Our learned search heuristic can simultaneously predict the feasibility for all path options in a single run, and the model-based safety checker is only invoked on the top-scoring paths. We validate in high-fidelity simulations using both real Martian terrain data collected by the Perseverance rover, as well as a suite of challenging synthetic terrains. Our experiments show that: (i) compared to the baseline ENav path planner on board the Perserverance rover, MLNav can provide a significant improvement in multiple key metrics, such as a 10x reduction in collision checks when navigating real Martian terrains, despite being trained with synthetic terrains; and (ii) MLNav can successfully navigate highly challenging terrains where the baseline ENav fails to find a feasible path before timing out.
Machine Learning Based Path Planning for Improved Rover Navigation (Pre-Print Version)
Nov 11, 2020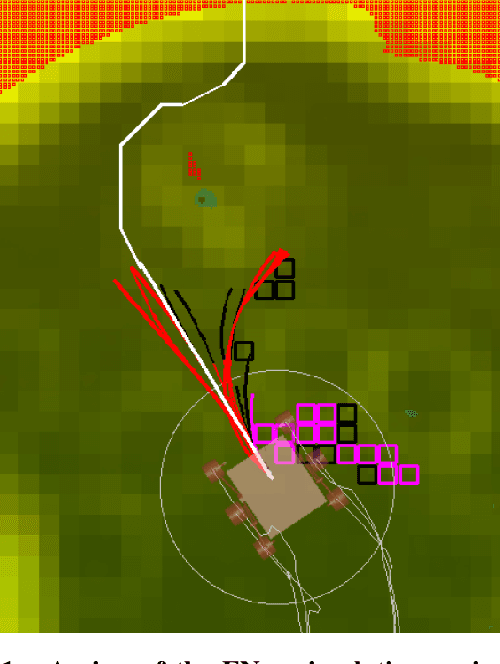
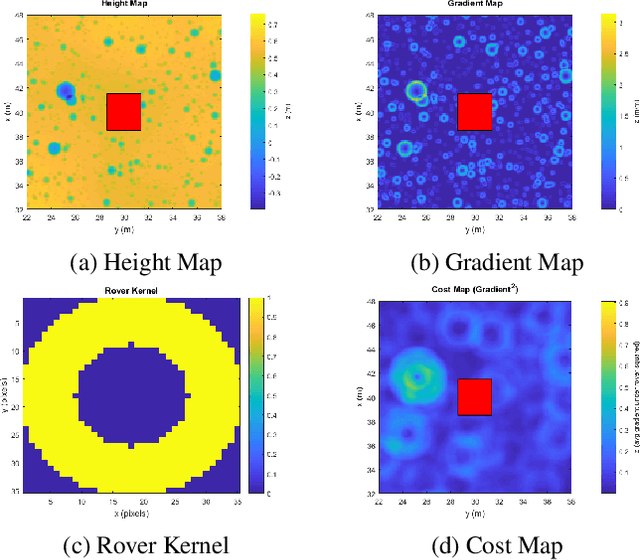

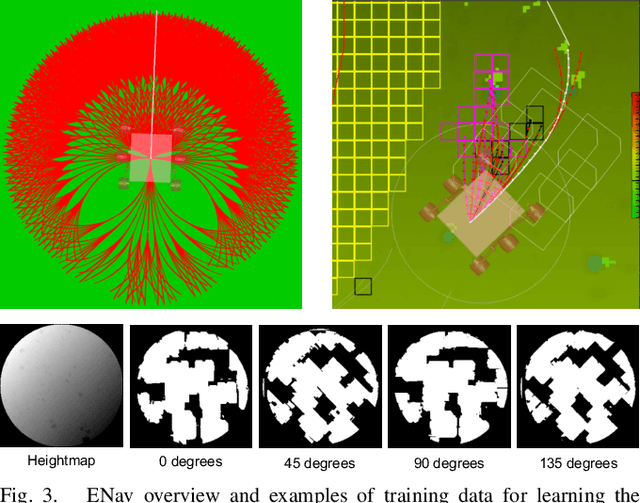
Enhanced AutoNav (ENav), the baseline surface navigation software for NASA's Perseverance rover, sorts a list of candidate paths for the rover to traverse, then uses the Approximate Clearance Evaluation (ACE) algorithm to evaluate whether the most highly ranked paths are safe. ACE is crucial for maintaining the safety of the rover, but is computationally expensive. If the most promising candidates in the list of paths are all found to be infeasible, ENav must continue to search the list and run time-consuming ACE evaluations until a feasible path is found. In this paper, we present two heuristics that, given a terrain heightmap around the rover, produce cost estimates that more effectively rank the candidate paths before ACE evaluation. The first heuristic uses Sobel operators and convolution to incorporate the cost of traversing high-gradient terrain. The second heuristic uses a machine learning (ML) model to predict areas that will be deemed untraversable by ACE. We used physics simulations to collect training data for the ML model and to run Monte Carlo trials to quantify navigation performance across a variety of terrains with various slopes and rock distributions. Compared to ENav's baseline performance, integrating the heuristics can lead to a significant reduction in ACE evaluations and average computation time per planning cycle, increase path efficiency, and maintain or improve the rate of successful traverses. This strategy of targeting specific bottlenecks with ML while maintaining the original ACE safety checks provides an example of how ML can be infused into planetary science missions and other safety-critical software.
Risk-Averse Planning Under Uncertainty
Sep 27, 2019

We consider the problem of designing policies for partially observable Markov decision processes (POMDPs) with dynamic coherent risk objectives. Synthesizing risk-averse optimal policies for POMDPs requires infinite memory and thus undecidable. To overcome this difficulty, we propose a method based on bounded policy iteration for designing stochastic but finite state (memory) controllers, which takes advantage of standard convex optimization methods. Given a memory budget and optimality criterion, the proposed method modifies the stochastic finite state controller leading to sub-optimal solutions with lower coherent risk.
Co-training for Policy Learning
Jul 03, 2019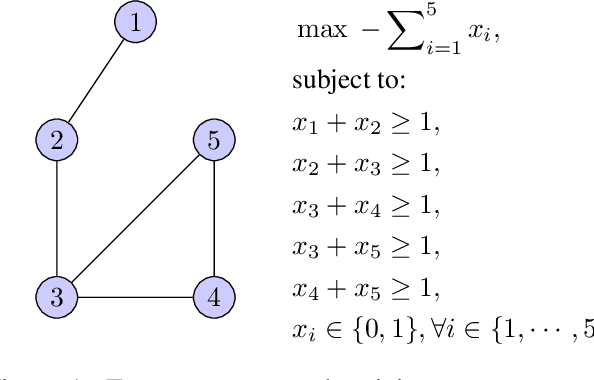
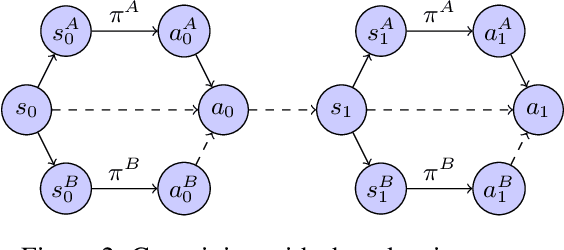
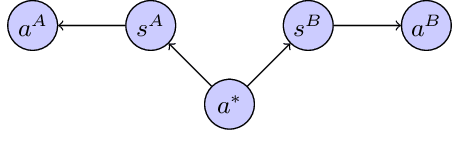
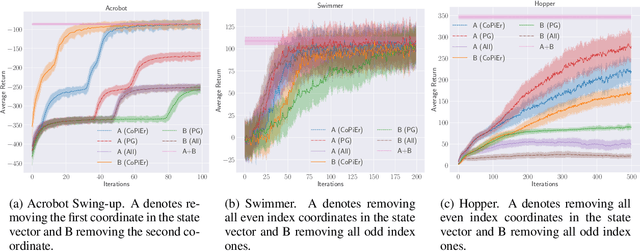
We study the problem of learning sequential decision-making policies in settings with multiple state-action representations. Such settings naturally arise in many domains, such as planning (e.g., multiple integer programming formulations) and various combinatorial optimization problems (e.g., those with both integer programming and graph-based formulations). Inspired by the classical co-training framework for classification, we study the problem of co-training for policy learning. We present sufficient conditions under which learning from two views can improve upon learning from a single view alone. Motivated by these theoretical insights, we present a meta-algorithm for co-training for sequential decision making. Our framework is compatible with both reinforcement learning and imitation learning. We validate the effectiveness of our approach across a wide range of tasks, including discrete/continuous control and combinatorial optimization.
Learning to Search via Retrospective Imitation
Oct 05, 2018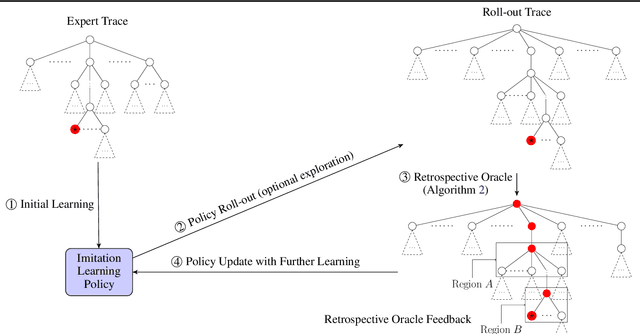
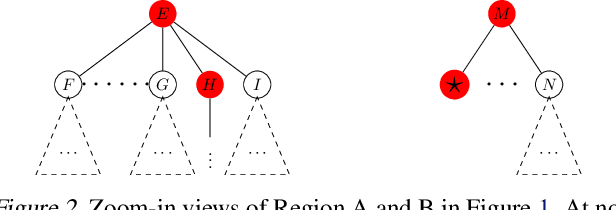
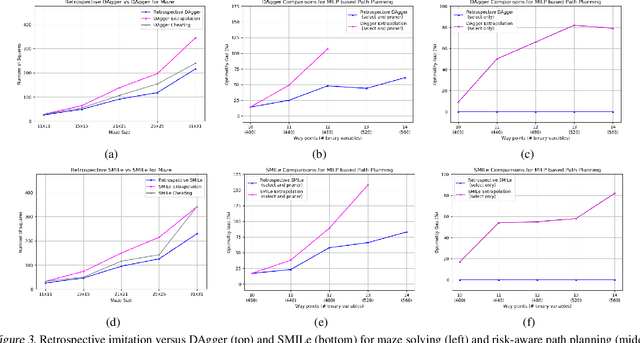

We study the problem of learning a good search policy from demonstrations for combinatorial search spaces. We propose retrospective imitation learning, which, after initial training by an expert, improves itself by learning from its own retrospective solutions. That is, when the policy eventually reaches a feasible solution in a search tree after making mistakes and backtracks, it retrospectively constructs an improved search trace to the solution by removing backtracks, which is then used to further train the policy. A key feature of our approach is that it can iteratively scale up, or transfer, to larger problem sizes than the initial expert demonstrations, thus dramatically expanding its applicability beyond that of conventional imitation learning. We showcase the effectiveness of our approach on two tasks: synthetic maze solving, and integer program based risk-aware path planning.