 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNemotron 3 Super: Open, Efficient Mixture-of-Experts Hybrid Mamba-Transformer Model for Agentic Reasoning
Apr 14, 2026We describe the pre-training, post-training, and quantization of Nemotron 3 Super, a 120 billion (active 12 billion) parameter hybrid Mamba-Attention Mixture-of-Experts model. Nemotron 3 Super is the first model in the Nemotron 3 family to 1) be pre-trained in NVFP4, 2) leverage LatentMoE, a new Mixture-of-Experts architecture that optimizes for both accuracy per FLOP and accuracy per parameter, and 3) include MTP layers for inference acceleration through native speculative decoding. We pre-trained Nemotron 3 Super on 25 trillion tokens followed by post-training using supervised fine tuning (SFT) and reinforcement learning (RL). The final model supports up to 1M context length and achieves comparable accuracy on common benchmarks, while also achieving up to 2.2x and 7.5x higher inference throughput compared to GPT-OSS-120B and Qwen3.5-122B, respectively. Nemotron 3 Super datasets, along with the base, post-trained, and quantized checkpoints, are open-sourced on HuggingFace.
FluidGaussian: Propagating Simulation-Based Uncertainty Toward Functionally-Intelligent 3D Reconstruction
Mar 22, 2026Real objects that inhabit the physical world follow physical laws and thus behave plausibly during interaction with other physical objects. However, current methods that perform 3D reconstructions of real-world scenes from multi-view 2D images optimize primarily for visual fidelity, i.e., they train with photometric losses and reason about uncertainty in the image or representation space. This appearance-centric view overlooks body contacts and couplings, conflates function-critical regions (e.g., aerodynamic or hydrodynamic surfaces) with ornamentation, and reconstructs structures suboptimally, even when physical regularizers are added. All these can lead to unphysical and implausible interactions. To address this, we consider the question: How can 3D reconstruction become aware of real-world interactions and underlying object functionality, beyond visual cues? To answer this question, we propose FluidGaussian, a plug-and-play method that tightly couples geometry reconstruction with ubiquitous fluid-structure interactions to assess surface quality at high granularity. We define a simulation-based uncertainty metric induced by fluid simulations and integrate it with active learning to prioritize views that improve both visual and physical fidelity. In an empirical evaluation on NeRF Synthetic (Blender), Mip-NeRF 360, and DrivAerNet++, our FluidGaussian method yields up to +8.6% visual PSNR (Peak Signal-to-Noise Ratio) and -62.3% velocity divergence during fluid simulations. Our code is available at https://github.com/delta-lab-ai/FluidGaussian.
SEMA: Simple yet Effective Learning for Multi-Turn Jailbreak Attacks
Feb 06, 2026Multi-turn jailbreaks capture the real threat model for safety-aligned chatbots, where single-turn attacks are merely a special case. Yet existing approaches break under exploration complexity and intent drift. We propose SEMA, a simple yet effective framework that trains a multi-turn attacker without relying on any existing strategies or external data. SEMA comprises two stages. Prefilling self-tuning enables usable rollouts by fine-tuning on non-refusal, well-structured, multi-turn adversarial prompts that are self-generated with a minimal prefix, thereby stabilizing subsequent learning. Reinforcement learning with intent-drift-aware reward trains the attacker to elicit valid multi-turn adversarial prompts while maintaining the same harmful objective. We anchor harmful intent in multi-turn jailbreaks via an intent-drift-aware reward that combines intent alignment, compliance risk, and level of detail. Our open-loop attack regime avoids dependence on victim feedback, unifies single- and multi-turn settings, and reduces exploration complexity. Across multiple datasets, victim models, and jailbreak judges, our method achieves state-of-the-art (SOTA) attack success rates (ASR), outperforming all single-turn baselines, manually scripted and template-driven multi-turn baselines, as well as our SFT (Supervised Fine-Tuning) and DPO (Direct Preference Optimization) variants. For instance, SEMA performs an average $80.1\%$ ASR@1 across three closed-source and open-source victim models on AdvBench, 33.9% over SOTA. The approach is compact, reproducible, and transfers across targets, providing a stronger and more realistic stress test for large language model (LLM) safety and enabling automatic redteaming to expose and localize failure modes. Our code is available at: https://github.com/fmmarkmq/SEMA.
Beyond Single Frames: Can LMMs Comprehend Temporal and Contextual Narratives in Image Sequences?
Feb 19, 2025Large Multimodal Models (LMMs) have achieved remarkable success across various visual-language tasks. However, existing benchmarks predominantly focus on single-image understanding, leaving the analysis of image sequences largely unexplored. To address this limitation, we introduce StripCipher, a comprehensive benchmark designed to evaluate capabilities of LMMs to comprehend and reason over sequential images. StripCipher comprises a human-annotated dataset and three challenging subtasks: visual narrative comprehension, contextual frame prediction, and temporal narrative reordering. Our evaluation of $16$ state-of-the-art LMMs, including GPT-4o and Qwen2.5VL, reveals a significant performance gap compared to human capabilities, particularly in tasks that require reordering shuffled sequential images. For instance, GPT-4o achieves only 23.93% accuracy in the reordering subtask, which is 56.07% lower than human performance. Further quantitative analysis discuss several factors, such as input format of images, affecting the performance of LLMs in sequential understanding, underscoring the fundamental challenges that remain in the development of LMMs.
PDE-Controller: LLMs for Autoformalization and Reasoning of PDEs
Feb 03, 2025



While recent AI-for-math has made strides in pure mathematics, areas of applied mathematics, particularly PDEs, remain underexplored despite their significant real-world applications. We present PDE-Controller, a framework that enables large language models (LLMs) to control systems governed by partial differential equations (PDEs). Our approach enables LLMs to transform informal natural language instructions into formal specifications, and then execute reasoning and planning steps to improve the utility of PDE control. We build a holistic solution comprising datasets (both human-written cases and 2 million synthetic samples), math-reasoning models, and novel evaluation metrics, all of which require significant effort. Our PDE-Controller significantly outperforms prompting the latest open-source and GPT models in reasoning, autoformalization, and program synthesis, achieving up to a 62% improvement in utility gain for PDE control. By bridging the gap between language generation and PDE systems, we demonstrate the potential of LLMs in addressing complex scientific and engineering challenges. We will release all data, model checkpoints, and code at https://pde-controller.github.io/.
Effective Large Language Model Debugging with Best-first Tree Search
Jul 26, 2024



Large Language Models (LLMs) show promise in code generation tasks. However, their code-writing abilities are often limited in scope: while they can successfully implement simple functions, they struggle with more complex tasks. A fundamental difference with how an LLM writes code, compared to a human programmer, is that it cannot consistently spot and fix bugs. Debugging is a crucial skill for programmers and it enables iterative code refinement towards a correct implementation. In this work, we propose a novel algorithm to enable LLMs to debug their code via self-reflection and search where a model attempts to identify its previous mistakes. Our key contributions are 1) a best-first tree search algorithm with self-reflections (BESTER) that achieves state-of-the-art Pass@1 in three code generation benchmarks. BESTER maintains its superiority when we measure pass rates taking into account additional inference costs incurred by tree search. 2) A novel interpretability study on what self-reflections attend to in buggy programs and how they impact bug fixes, which provides a deeper understanding of the debugging process. 3) An extensive study on when self-reflections are effective in finding bugs.
Learning Physics for Unveiling Hidden Earthquake Ground Motions via Conditional Generative Modeling
Jul 21, 2024



Predicting high-fidelity ground motions for future earthquakes is crucial for seismic hazard assessment and infrastructure resilience. Conventional empirical simulations suffer from sparse sensor distribution and geographically localized earthquake locations, while physics-based methods are computationally intensive and require accurate representations of Earth structures and earthquake sources. We propose a novel artificial intelligence (AI) simulator, Conditional Generative Modeling for Ground Motion (CGM-GM), to synthesize high-frequency and spatially continuous earthquake ground motion waveforms. CGM-GM leverages earthquake magnitudes and geographic coordinates of earthquakes and sensors as inputs, learning complex wave physics and Earth heterogeneities, without explicit physics constraints. This is achieved through a probabilistic autoencoder that captures latent distributions in the time-frequency domain and variational sequential models for prior and posterior distributions. We evaluate the performance of CGM-GM using small-magnitude earthquake records from the San Francisco Bay Area, a region with high seismic risks. CGM-GM demonstrates a strong potential for outperforming a state-of-the-art non-ergodic empirical ground motion model and shows great promise in seismology and beyond.
CircuitVAE: Efficient and Scalable Latent Circuit Optimization
Jun 13, 2024
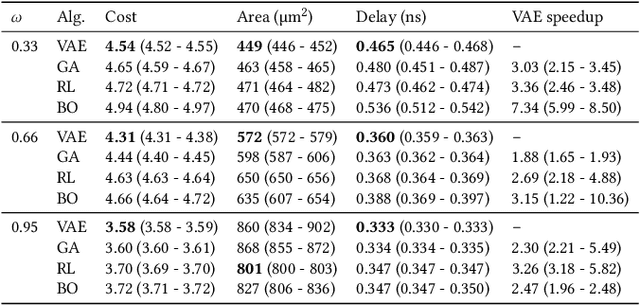
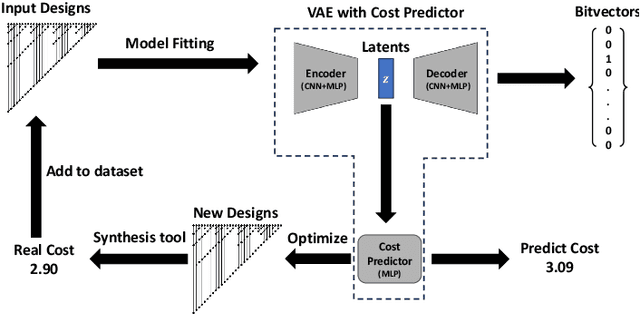
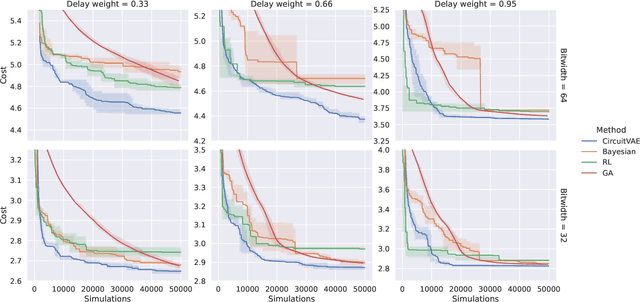
Automatically designing fast and space-efficient digital circuits is challenging because circuits are discrete, must exactly implement the desired logic, and are costly to simulate. We address these challenges with CircuitVAE, a search algorithm that embeds computation graphs in a continuous space and optimizes a learned surrogate of physical simulation by gradient descent. By carefully controlling overfitting of the simulation surrogate and ensuring diverse exploration, our algorithm is highly sample-efficient, yet gracefully scales to large problem instances and high sample budgets. We test CircuitVAE by designing binary adders across a large range of sizes, IO timing constraints, and sample budgets. Our method excels at designing large circuits, where other algorithms struggle: compared to reinforcement learning and genetic algorithms, CircuitVAE typically finds 64-bit adders which are smaller and faster using less than half the sample budget. We also find CircuitVAE can design state-of-the-art adders in a real-world chip, demonstrating that our method can outperform commercial tools in a realistic setting.
Data-Efficient Operator Learning via Unsupervised Pretraining and In-Context Learning
Feb 24, 2024



Recent years have witnessed the promise of coupling machine learning methods and physical domain-specific insight for solving scientific problems based on partial differential equations (PDEs). However, being data-intensive, these methods still require a large amount of PDE data. This reintroduces the need for expensive numerical PDE solutions, partially undermining the original goal of avoiding these expensive simulations. In this work, seeking data efficiency, we design unsupervised pretraining and in-context learning methods for PDE operator learning. To reduce the need for training data with simulated solutions, we pretrain neural operators on unlabeled PDE data using reconstruction-based proxy tasks. To improve out-of-distribution performance, we further assist neural operators in flexibly leveraging in-context learning methods, without incurring extra training costs or designs. Extensive empirical evaluations on a diverse set of PDEs demonstrate that our method is highly data-efficient, more generalizable, and even outperforms conventional vision-pretrained models.
Joint-Space Multi-Robot Motion Planning with Learned Decentralized Heuristics
Nov 21, 2023In this paper, we present a method of multi-robot motion planning by biasing centralized, sampling-based tree search with decentralized, data-driven steer and distance heuristics. Over a range of robot and obstacle densities, we evaluate the plain Rapidly-expanding Random Trees (RRT), and variants of our method for double integrator dynamics. We show that whereas plain RRT fails in every instance to plan for $4$ robots, our method can plan for up to 16 robots, corresponding to searching through a very large 65-dimensional space, which validates the effectiveness of data-driven heuristics at combating exponential search space growth. We also find that the heuristic information is complementary; using both heuristics produces search trees with lower failure rates, nodes, and path costs when compared to using each in isolation. These results illustrate the effective decomposition of high-dimensional joint-space motion planning problems into local problems.