 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn Neural Scaling Laws for Weather Emulation through Continual Training
Mar 26, 2026Neural scaling laws, which in some domains can predict the performance of large neural networks as a function of model, data, and compute scale, are the cornerstone of building foundation models in Natural Language Processing and Computer Vision. We study neural scaling in Scientific Machine Learning, focusing on models for weather forecasting. To analyze scaling behavior in as simple a setting as possible, we adopt a minimal, scalable, general-purpose Swin Transformer architecture, and we use continual training with constant learning rates and periodic cooldowns as an efficient training strategy. We show that models trained in this minimalist way follow predictable scaling trends and even outperform standard cosine learning rate schedules. Cooldown phases can be re-purposed to improve downstream performance, e.g., enabling accurate multi-step rollouts over longer forecast horizons as well as sharper predictions through spectral loss adjustments. We also systematically explore a wide range of model and dataset sizes under various compute budgets to construct IsoFLOP curves, and we identify compute-optimal training regimes. Extrapolating these trends to larger scales highlights potential performance limits, demonstrating that neural scaling can serve as an important diagnostic for efficient resource allocation. We open-source our code for reproducibility.
Examining Fast Radiative Feedbacks Using Machine-Learning Weather Emulators
Feb 17, 2026The response of the climate system to increased greenhouse gases and other radiative perturbations is governed by a combination of fast and slow feedbacks. Slow feedbacks are typically activated in response to changes in ocean temperatures on decadal timescales and manifest as changes in climatic state with no recent historical analogue. However, fast feedbacks are activated in response to rapid atmospheric physical processes on weekly timescales, and they are already operative in the present-day climate. This distinction implies that the physics of fast radiative feedbacks is present in the historical meteorological reanalyses used to train many recent successful machine-learning-based (ML) emulators of weather and climate. In addition, these feedbacks are functional under the historical boundary conditions pertaining to the top-of-atmosphere radiative balance and sea-surface temperatures. Together, these factors imply that we can use historically trained ML weather emulators to study the response of radiative-convective equilibrium (RCE), and hence the global hydrological cycle, to perturbations in carbon dioxide and other well-mixed greenhouse gases. Without retraining on prospective Earth system conditions, we use ML weather emulators to quantify the fast precipitation response to reduced and elevated carbon dioxed concentrations with no recent historical precedent. We show that the responses from historically trained emulators agree with those produced by full-physics Earth System Models (ESMs). In conclusion, we discuss the prospects for and advantages from using ESMs and ML emulators to study fast processes in global climate.
Huge Ensembles Part I: Design of Ensemble Weather Forecasts using Spherical Fourier Neural Operators
Aug 06, 2024



Studying low-likelihood high-impact extreme weather events in a warming world is a significant and challenging task for current ensemble forecasting systems. While these systems presently use up to 100 members, larger ensembles could enrich the sampling of internal variability. They may capture the long tails associated with climate hazards better than traditional ensemble sizes. Due to computational constraints, it is infeasible to generate huge ensembles (comprised of 1,000-10,000 members) with traditional, physics-based numerical models. In this two-part paper, we replace traditional numerical simulations with machine learning (ML) to generate hindcasts of huge ensembles. In Part I, we construct an ensemble weather forecasting system based on Spherical Fourier Neural Operators (SFNO), and we discuss important design decisions for constructing such an ensemble. The ensemble represents model uncertainty through perturbed-parameter techniques, and it represents initial condition uncertainty through bred vectors, which sample the fastest growing modes of the forecast. Using the European Centre for Medium-Range Weather Forecasts Integrated Forecasting System (IFS) as a baseline, we develop an evaluation pipeline composed of mean, spectral, and extreme diagnostics. Using large-scale, distributed SFNOs with 1.1 billion learned parameters, we achieve calibrated probabilistic forecasts. As the trajectories of the individual members diverge, the ML ensemble mean spectra degrade with lead time, consistent with physical expectations. However, the individual ensemble members' spectra stay constant with lead time. Therefore, these members simulate realistic weather states, and the ML ensemble thus passes a crucial spectral test in the literature. The IFS and ML ensembles have similar Extreme Forecast Indices, and we show that the ML extreme weather forecasts are reliable and discriminating.
Huge Ensembles Part II: Properties of a Huge Ensemble of Hindcasts Generated with Spherical Fourier Neural Operators
Aug 02, 2024



In Part I, we created an ensemble based on Spherical Fourier Neural Operators. As initial condition perturbations, we used bred vectors, and as model perturbations, we used multiple checkpoints trained independently from scratch. Based on diagnostics that assess the ensemble's physical fidelity, our ensemble has comparable performance to operational weather forecasting systems. However, it requires several orders of magnitude fewer computational resources. Here in Part II, we generate a huge ensemble (HENS), with 7,424 members initialized each day of summer 2023. We enumerate the technical requirements for running huge ensembles at this scale. HENS precisely samples the tails of the forecast distribution and presents a detailed sampling of internal variability. For extreme climate statistics, HENS samples events 4$\sigma$ away from the ensemble mean. At each grid cell, HENS improves the skill of the most accurate ensemble member and enhances coverage of possible future trajectories. As a weather forecasting model, HENS issues extreme weather forecasts with better uncertainty quantification. It also reduces the probability of outlier events, in which the verification value lies outside the ensemble forecast distribution.
Analyzing and Exploring Training Recipes for Large-Scale Transformer-Based Weather Prediction
Apr 30, 2024



The rapid rise of deep learning (DL) in numerical weather prediction (NWP) has led to a proliferation of models which forecast atmospheric variables with comparable or superior skill than traditional physics-based NWP. However, among these leading DL models, there is a wide variance in both the training settings and architecture used. Further, the lack of thorough ablation studies makes it hard to discern which components are most critical to success. In this work, we show that it is possible to attain high forecast skill even with relatively off-the-shelf architectures, simple training procedures, and moderate compute budgets. Specifically, we train a minimally modified SwinV2 transformer on ERA5 data, and find that it attains superior forecast skill when compared against IFS. We present some ablations on key aspects of the training pipeline, exploring different loss functions, model sizes and depths, and multi-step fine-tuning to investigate their effect. We also examine the model performance with metrics beyond the typical ACC and RMSE, and investigate how the performance scales with model size.
* 9 pages, 6 figures
Data-Efficient Operator Learning via Unsupervised Pretraining and In-Context Learning
Feb 24, 2024



Recent years have witnessed the promise of coupling machine learning methods and physical domain-specific insight for solving scientific problems based on partial differential equations (PDEs). However, being data-intensive, these methods still require a large amount of PDE data. This reintroduces the need for expensive numerical PDE solutions, partially undermining the original goal of avoiding these expensive simulations. In this work, seeking data efficiency, we design unsupervised pretraining and in-context learning methods for PDE operator learning. To reduce the need for training data with simulated solutions, we pretrain neural operators on unlabeled PDE data using reconstruction-based proxy tasks. To improve out-of-distribution performance, we further assist neural operators in flexibly leveraging in-context learning methods, without incurring extra training costs or designs. Extensive empirical evaluations on a diverse set of PDEs demonstrate that our method is highly data-efficient, more generalizable, and even outperforms conventional vision-pretrained models.
SuperBench: A Super-Resolution Benchmark Dataset for Scientific Machine Learning
Jun 24, 2023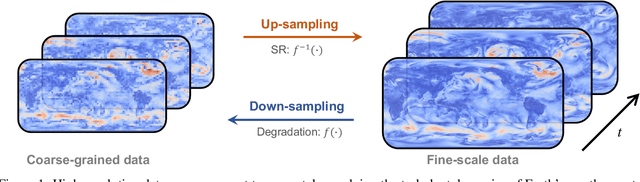

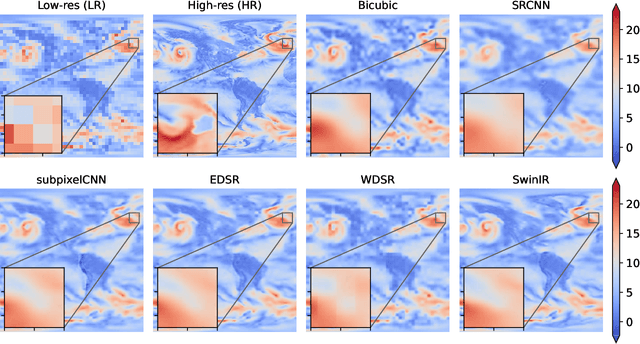

Super-Resolution (SR) techniques aim to enhance data resolution, enabling the retrieval of finer details, and improving the overall quality and fidelity of the data representation. There is growing interest in applying SR methods to complex spatiotemporal systems within the Scientific Machine Learning (SciML) community, with the hope of accelerating numerical simulations and/or improving forecasts in weather, climate, and related areas. However, the lack of standardized benchmark datasets for comparing and validating SR methods hinders progress and adoption in SciML. To address this, we introduce SuperBench, the first benchmark dataset featuring high-resolution datasets (up to $2048\times2048$ dimensions), including data from fluid flows, cosmology, and weather. Here, we focus on validating spatial SR performance from data-centric and physics-preserved perspectives, as well as assessing robustness to data degradation tasks. While deep learning-based SR methods (developed in the computer vision community) excel on certain tasks, despite relatively limited prior physics information, we identify limitations of these methods in accurately capturing intricate fine-scale features and preserving fundamental physical properties and constraints in scientific data. These shortcomings highlight the importance and subtlety of incorporating domain knowledge into ML models. We anticipate that SuperBench will significantly advance SR methods for scientific tasks.
Towards Stability of Autoregressive Neural Operators
Jun 18, 2023Neural operators have proven to be a promising approach for modeling spatiotemporal systems in the physical sciences. However, training these models for large systems can be quite challenging as they incur significant computational and memory expense -- these systems are often forced to rely on autoregressive time-stepping of the neural network to predict future temporal states. While this is effective in managing costs, it can lead to uncontrolled error growth over time and eventual instability. We analyze the sources of this autoregressive error growth using prototypical neural operator models for physical systems and explore ways to mitigate it. We introduce architectural and application-specific improvements that allow for careful control of instability-inducing operations within these models without inflating the compute/memory expense. We present results on several scientific systems that include Navier-Stokes fluid flow, rotating shallow water, and a high-resolution global weather forecasting system. We demonstrate that applying our design principles to prototypical neural networks leads to significantly lower errors in long-range forecasts with 800\% longer forecasts without qualitative signs of divergence compared to the original models for these systems. We open-source our \href{https://anonymous.4open.science/r/stabilizing_neural_operators-5774/}{code} for reproducibility.
Towards Foundation Models for Scientific Machine Learning: Characterizing Scaling and Transfer Behavior
Jun 01, 2023



Pre-trained machine learning (ML) models have shown great performance for a wide range of applications, in particular in natural language processing (NLP) and computer vision (CV). Here, we study how pre-training could be used for scientific machine learning (SciML) applications, specifically in the context of transfer learning. We study the transfer behavior of these models as (i) the pre-trained model size is scaled, (ii) the downstream training dataset size is scaled, (iii) the physics parameters are systematically pushed out of distribution, and (iv) how a single model pre-trained on a mixture of different physics problems can be adapted to various downstream applications. We find that-when fine-tuned appropriately-transfer learning can help reach desired accuracy levels with orders of magnitude fewer downstream examples (across different tasks that can even be out-of-distribution) than training from scratch, with consistent behavior across a wide range of downstream examples. We also find that fine-tuning these models yields more performance gains as model size increases, compared to training from scratch on new downstream tasks. These results hold for a broad range of PDE learning tasks. All in all, our results demonstrate the potential of the "pre-train and fine-tune" paradigm for SciML problems, demonstrating a path towards building SciML foundation models. We open-source our code for reproducibility.
Generative Modeling of High-resolution Global Precipitation Forecasts
Oct 22, 2022



Forecasting global precipitation patterns and, in particular, extreme precipitation events is of critical importance to preparing for and adapting to climate change. Making accurate high-resolution precipitation forecasts using traditional physical models remains a major challenge in operational weather forecasting as they incur substantial computational costs and struggle to achieve sufficient forecast skill. Recently, deep-learning-based models have shown great promise in closing the gap with numerical weather prediction (NWP) models in terms of precipitation forecast skill, opening up exciting new avenues for precipitation modeling. However, it is challenging for these deep learning models to fully resolve the fine-scale structures of precipitation phenomena and adequately characterize the extremes of the long-tailed precipitation distribution. In this work, we present several improvements to the architecture and training process of a current state-of-the art deep learning precipitation model (FourCastNet) using a novel generative adversarial network (GAN) to better capture fine scales and extremes. Our improvements achieve superior performance in capturing the extreme percentiles of global precipitation, while comparable to state-of-the-art NWP models in terms of forecast skill at 1--2 day lead times. Together, these improvements set a new state-of-the-art in global precipitation forecasting.